 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProject Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
Exact and Asymptotically Complete Robust Verifications of Neural Networks via Quantum Optimization
Feb 28, 2026Deep neural networks (DNNs) enable high performance across domains but remain vulnerable to adversarial perturbations, limiting their use in safety-critical settings. Here, we introduce two quantum-optimization-based models for robust verification that reduce the combinatorial burden of certification under bounded input perturbations. For piecewise-linear activations (e.g., ReLU and hardtanh), our first model yields an exact formulation that is sound and complete, enabling precise identification of adversarial examples. For general activations (including sigmoid and tanh), our second model constructs scalable over-approximations via piecewise-constant bounds and is asymptotically complete, with approximation error vanishing as the segmentation is refined. We further integrate Quantum Benders Decomposition with interval arithmetic to accelerate solving, and propose certificate-transfer bounds that relate robustness guarantees of pruned networks to those of the original model. Finally, a layerwise partitioning strategy supports a quantum--classical hybrid workflow by coupling subproblems across depth. Experiments on robustness benchmarks show high certification accuracy, indicating that quantum optimization can serve as a principled primitive for robustness guarantees in neural networks with complex activations.
Kaiwu-PyTorch-Plugin: Bridging Deep Learning and Photonic Quantum Computing for Energy-Based Models and Active Sample Selection
Feb 22, 2026This paper introduces the Kaiwu-PyTorch-Plugin (KPP) to bridge Deep Learning and Photonic Quantum Computing across multiple dimensions. KPP integrates the Coherent Ising Machine into the PyTorch ecosystem, addressing classical inefficiencies in Energy-Based Models. The framework facilitates quantum integration in three key aspects: accelerating Boltzmann sampling, optimizing training data via Active Sampling, and constructing hybrid architectures like QBM-VAE and Q-Diffusion. Empirical results on single-cell and OpenWebText datasets demonstrate KPPs ability to achieve SOTA performance, validating a comprehensive quantum-classical paradigm.
FoundDiff: Foundational Diffusion Model for Generalizable Low-Dose CT Denoising
Aug 24, 2025Low-dose computed tomography (CT) denoising is crucial for reduced radiation exposure while ensuring diagnostically acceptable image quality. Despite significant advancements driven by deep learning (DL) in recent years, existing DL-based methods, typically trained on a specific dose level and anatomical region, struggle to handle diverse noise characteristics and anatomical heterogeneity during varied scanning conditions, limiting their generalizability and robustness in clinical scenarios. In this paper, we propose FoundDiff, a foundational diffusion model for unified and generalizable LDCT denoising across various dose levels and anatomical regions. FoundDiff employs a two-stage strategy: (i) dose-anatomy perception and (ii) adaptive denoising. First, we develop a dose- and anatomy-aware contrastive language image pre-training model (DA-CLIP) to achieve robust dose and anatomy perception by leveraging specialized contrastive learning strategies to learn continuous representations that quantify ordinal dose variations and identify salient anatomical regions. Second, we design a dose- and anatomy-aware diffusion model (DA-Diff) to perform adaptive and generalizable denoising by synergistically integrating the learned dose and anatomy embeddings from DACLIP into diffusion process via a novel dose and anatomy conditional block (DACB) based on Mamba. Extensive experiments on two public LDCT datasets encompassing eight dose levels and three anatomical regions demonstrate superior denoising performance of FoundDiff over existing state-of-the-art methods and the remarkable generalization to unseen dose levels. The codes and models are available at https://github.com/hao1635/FoundDiff.
LangMamba: A Language-driven Mamba Framework for Low-dose CT Denoising with Vision-language Models
Jul 08, 2025Low-dose computed tomography (LDCT) reduces radiation exposure but often degrades image quality, potentially compromising diagnostic accuracy. Existing deep learning-based denoising methods focus primarily on pixel-level mappings, overlooking the potential benefits of high-level semantic guidance. Recent advances in vision-language models (VLMs) suggest that language can serve as a powerful tool for capturing structured semantic information, offering new opportunities to improve LDCT reconstruction. In this paper, we introduce LangMamba, a Language-driven Mamba framework for LDCT denoising that leverages VLM-derived representations to enhance supervision from normal-dose CT (NDCT). LangMamba follows a two-stage learning strategy. First, we pre-train a Language-guided AutoEncoder (LangAE) that leverages frozen VLMs to map NDCT images into a semantic space enriched with anatomical information. Second, we synergize LangAE with two key components to guide LDCT denoising: Semantic-Enhanced Efficient Denoiser (SEED), which enhances NDCT-relevant local semantic while capturing global features with efficient Mamba mechanism, and Language-engaged Dual-space Alignment (LangDA) Loss, which ensures that denoised images align with NDCT in both perceptual and semantic spaces. Extensive experiments on two public datasets demonstrate that LangMamba outperforms conventional state-of-the-art methods, significantly improving detail preservation and visual fidelity. Remarkably, LangAE exhibits strong generalizability to unseen datasets, thereby reducing training costs. Furthermore, LangDA loss improves explainability by integrating language-guided insights into image reconstruction and offers a plug-and-play fashion. Our findings shed new light on the potential of language as a supervisory signal to advance LDCT denoising. The code is publicly available on https://github.com/hao1635/LangMamba.
Human-Centered Human-AI Collaboration (HCHAC)
May 28, 2025



In the intelligent era, the interaction between humans and intelligent systems fundamentally involves collaboration with autonomous intelligent agents. Human-AI Collaboration (HAC) represents a novel type of human-machine relationship facilitated by autonomous intelligent machines equipped with AI technologies. In this paradigm, AI agents serve not only as auxiliary tools but also as active teammates, partnering with humans to accomplish tasks collaboratively. Human-centered AI (HCAI) emphasizes that humans play critical leadership roles in the collaboration. This human-led collaboration imparts new dimensions to the human-machine relationship, necessitating innovative research perspectives, paradigms, and agenda to address the unique challenges posed by HAC. This chapter delves into the essence of HAC from the human-centered perspective, outlining its core concepts and distinguishing features. It reviews the current research methodologies and research agenda within the HAC field from the HCAI perspective, highlighting advancements and ongoing studies. Furthermore, a framework for human-centered HAC (HCHAC) is proposed by integrating these reviews and analyses. A case study of HAC in the context of autonomous vehicles is provided, illustrating practical applications and the synergistic interactions between humans and AI agents. Finally, it identifies potential future research directions aimed at enhancing the effectiveness, reliability, and ethical integration of human-centered HAC systems in diverse domains.
Efficient Deep Learning Board: Training Feedback Is Not All You Need
Oct 17, 2024Current automatic deep learning (i.e., AutoDL) frameworks rely on training feedback from actual runs, which often hinder their ability to provide quick and clear performance predictions for selecting suitable DL systems. To address this issue, we propose EfficientDL, an innovative deep learning board designed for automatic performance prediction and component recommendation. EfficientDL can quickly and precisely recommend twenty-seven system components and predict the performance of DL models without requiring any training feedback. The magic of no training feedback comes from our proposed comprehensive, multi-dimensional, fine-grained system component dataset, which enables us to develop a static performance prediction model and comprehensive optimized component recommendation algorithm (i.e., {\alpha}\b{eta}-BO search), removing the dependency on actually running parameterized models during the traditional optimization search process. The simplicity and power of EfficientDL stem from its compatibility with most DL models. For example, EfficientDL operates seamlessly with mainstream models such as ResNet50, MobileNetV3, EfficientNet-B0, MaxViT-T, Swin-B, and DaViT-T, bringing competitive performance improvements. Besides, experimental results on the CIFAR-10 dataset reveal that EfficientDL outperforms existing AutoML tools in both accuracy and efficiency (approximately 20 times faster along with 1.31% Top-1 accuracy improvement than the cutting-edge methods). Source code, pretrained models, and datasets are available at https://github.com/OpenSELab/EfficientDL.
Herald: A Natural Language Annotated Lean 4 Dataset
Oct 09, 2024


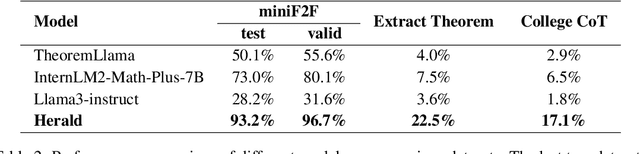
Verifiable formal languages like Lean have profoundly impacted mathematical reasoning, particularly through the use of large language models (LLMs) for automated reasoning. A significant challenge in training LLMs for these formal languages is the lack of parallel datasets that align natural language with formal language proofs. To address this challenge, this paper introduces a novel framework for translating the Mathlib4 corpus (a unified library of mathematics in formal language Lean 4) into natural language. Building upon this, we employ a dual augmentation strategy that combines tactic-based and informal-based approaches, leveraging the Lean-jixia system, a Lean 4 analyzer. We present the results of this pipeline on Mathlib4 as Herald (Hierarchy and Retrieval-based Translated Lean Dataset). We also propose the Herald Translator, which is fine-tuned on Herald. Herald translator achieves a 93.2% accuracy (Pass@128) on formalizing statements in the miniF2F-test and a 22.5% accuracy on our internal graduate-level textbook dataset, outperforming InternLM2-Math-Plus-7B (74.0% and 7.5%) and TheoremLlama (50.1% and 4.0%). Furthermore, we propose a section-level translation framework for real-world applications. As a direct application of Herald translator, we have successfully translated a template section in the Stack project, marking a notable progress in the automatic formalization of graduate-level mathematical literature. Our model, along with the datasets, will be open-sourced to the public soon.
Distortion-Aware Phase Retrieval Receiver for High-Order QAM Transmission with Carrierless Intensity-Only Measurements
Oct 09, 2023We experimentally investigate transmitting high-order quadrature amplitude modulation (QAM) signals with carrierless and intensity-only measurements with phase retrieval (PR) receiving techniques. The intensity errors during measurement, including noise and distortions, are found to be a limiting factor for the precise convergence of the PR algorithm. To improve the PR reconstruction accuracy, we propose a distortion-aware PR scheme comprising both training and reconstruction stages. By estimating and emulating the distortion caused by various channel impairments, the proposed scheme enables enhanced agreement between the estimated and measured amplitudes throughout the PR iteration, thus resulting in improved reconstruction performance to support high-order QAM transmission. With the aid of proposed techniques, we experimentally demonstrate 50-GBaud 16QAM and 32QAM signals transmitting through a standard single-mode optical fiber (SSMF) span of 40 and 80 km, and achieve bit error rates (BERs) below the 6.25% hard decision (HD)-forward error correction (FEC) and 25% soft decision (SD)-FEC thresholds for the two modulation formats, respectively. By tuning the pilot symbol ratio and applying concatenated coding, we also demonstrate that a post-FEC data rate of up to 140 Gb/s can be achieved for both distances at an optimal pilot symbol ratio of 20%.
Agent Teaming Situation Awareness (ATSA): A Situation Awareness Framework for Human-AI Teaming
Sep 04, 2023The rapid advancements in artificial intelligence (AI) have led to a growing trend of human-AI teaming (HAT) in various fields. As machines continue to evolve from mere automation to a state of autonomy, they are increasingly exhibiting unexpected behaviors and human-like cognitive/intelligent capabilities, including situation awareness (SA). This shift has the potential to enhance the performance of mixed human-AI teams over all-human teams, underscoring the need for a better understanding of the dynamic SA interactions between humans and machines. To this end, we provide a review of leading SA theoretical models and a new framework for SA in the HAT context based on the key features and processes of HAT. The Agent Teaming Situation Awareness (ATSA) framework unifies human and AI behavior, and involves bidirectional, and dynamic interaction. The framework is based on the individual and team SA models and elaborates on the cognitive mechanisms for modeling HAT. Similar perceptual cycles are adopted for the individual (including both human and AI) and the whole team, which is tailored to the unique requirements of the HAT context. ATSA emphasizes cohesive and effective HAT through structures and components, including teaming understanding, teaming control, and the world, as well as adhesive transactive part. We further propose several future research directions to expand on the distinctive contributions of ATSA and address the specific and pressing next steps.