 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling Students Dropouts in an LLM-driven Interactive Online Course Using Language Models
Aug 24, 2025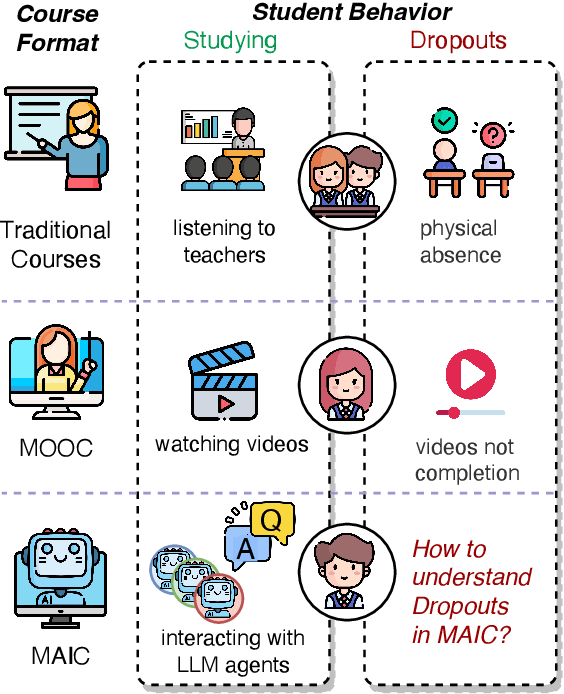
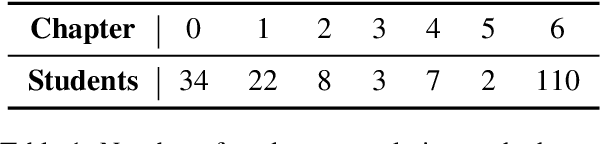
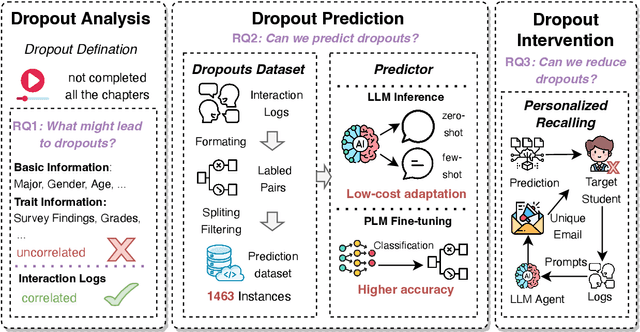
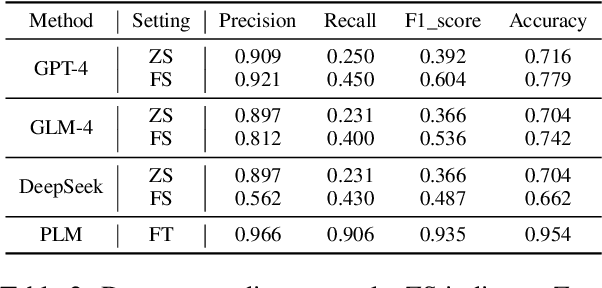
Interactive online learning environments, represented by Massive AI-empowered Courses (MAIC), leverage LLM-driven multi-agent systems to transform passive MOOCs into dynamic, text-based platforms, enhancing interactivity through LLMs. This paper conducts an empirical study on a specific MAIC course to explore three research questions about dropouts in these interactive online courses: (1) What factors might lead to dropouts? (2) Can we predict dropouts? (3) Can we reduce dropouts? We analyze interaction logs to define dropouts and identify contributing factors. Our findings reveal strong links between dropout behaviors and textual interaction patterns. We then propose a course-progress-adaptive dropout prediction framework (CPADP) to predict dropouts with at most 95.4% accuracy. Based on this, we design a personalized email recall agent to re-engage at-risk students. Applied in the deployed MAIC system with over 3,000 students, the feasibility and effectiveness of our approach have been validated on students with diverse backgrounds.
LecEval: An Automated Metric for Multimodal Knowledge Acquisition in Multimedia Learning
May 04, 2025Evaluating the quality of slide-based multimedia instruction is challenging. Existing methods like manual assessment, reference-based metrics, and large language model evaluators face limitations in scalability, context capture, or bias. In this paper, we introduce LecEval, an automated metric grounded in Mayer's Cognitive Theory of Multimedia Learning, to evaluate multimodal knowledge acquisition in slide-based learning. LecEval assesses effectiveness using four rubrics: Content Relevance (CR), Expressive Clarity (EC), Logical Structure (LS), and Audience Engagement (AE). We curate a large-scale dataset of over 2,000 slides from more than 50 online course videos, annotated with fine-grained human ratings across these rubrics. A model trained on this dataset demonstrates superior accuracy and adaptability compared to existing metrics, bridging the gap between automated and human assessments. We release our dataset and toolkits at https://github.com/JoylimJY/LecEval.
LongWriter-V: Enabling Ultra-Long and High-Fidelity Generation in Vision-Language Models
Feb 20, 2025Existing Large Vision-Language Models (LVLMs) can process inputs with context lengths up to 128k visual and text tokens, yet they struggle to generate coherent outputs beyond 1,000 words. We find that the primary limitation is the absence of long output examples during supervised fine-tuning (SFT). To tackle this issue, we introduce LongWriter-V-22k, a SFT dataset comprising 22,158 examples, each with multiple input images, an instruction, and corresponding outputs ranging from 0 to 10,000 words. Moreover, to achieve long outputs that maintain high-fidelity to the input images, we employ Direct Preference Optimization (DPO) to the SFT model. Given the high cost of collecting human feedback for lengthy outputs (e.g., 3,000 words), we propose IterDPO, which breaks long outputs into segments and uses iterative corrections to form preference pairs with the original outputs. Additionally, we develop MMLongBench-Write, a benchmark featuring six tasks to evaluate the long-generation capabilities of VLMs. Our 7B parameter model, trained with LongWriter-V-22k and IterDPO, achieves impressive performance on this benchmark, outperforming larger proprietary models like GPT-4o. Code and data: https://github.com/THU-KEG/LongWriter-V
Exploring LLM-based Student Simulation for Metacognitive Cultivation
Feb 17, 2025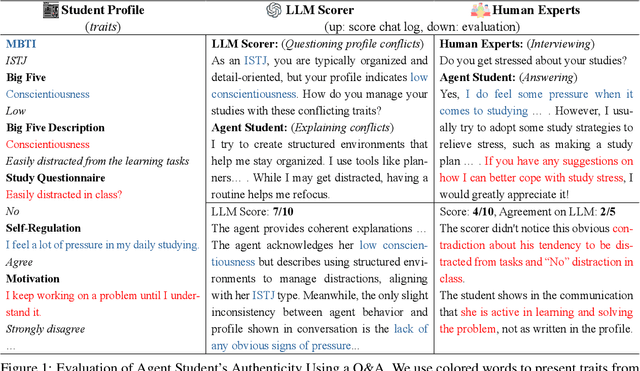



Metacognitive education plays a crucial role in cultivating students' self-regulation and reflective thinking, providing essential support for those with learning difficulties through academic advising. Simulating students with insufficient learning capabilities using large language models offers a promising approach to refining pedagogical methods without ethical concerns. However, existing simulations often fail to authentically represent students' learning struggles and face challenges in evaluation due to the lack of reliable metrics and ethical constraints in data collection. To address these issues, we propose a pipeline for automatically generating and filtering high-quality simulated student agents. Our approach leverages a two-round automated scoring system validated by human experts and employs a score propagation module to obtain more consistent scores across the student graph. Experimental results demonstrate that our pipeline efficiently identifies high-quality student agents, and we discuss the traits that influence the simulation's effectiveness. By simulating students with varying degrees of learning difficulties, our work paves the way for broader applications in personalized learning and educational assessment.
CoT-based Synthesizer: Enhancing LLM Performance through Answer Synthesis
Jan 03, 2025



Current inference scaling methods, such as Self-consistency and Best-of-N, have proven effective in improving the accuracy of LLMs on complex reasoning tasks. However, these methods rely heavily on the quality of candidate responses and are unable to produce correct answers when all candidates are incorrect. In this paper, we propose a novel inference scaling strategy, CoT-based Synthesizer, which leverages CoT reasoning to synthesize superior answers by analyzing complementary information from multiple candidate responses, even when all candidate responses are flawed. To enable a lightweight and cost-effective implementation, we introduce an automated data generation pipeline that creates diverse training data. This allows smaller LLMs trained on this data to improve the inference accuracy of larger models, including API-based LLMs. Experimental results across four benchmark datasets with seven policy models demonstrate that our method significantly enhances performance, with gains of 11.8% for Llama3-8B and 10.3% for GPT-4o on the MATH dataset. The corresponding training data and code are publicly available on https://github.com/RUCKBReasoning/CoT-based-Synthesizer.
Dynamic Scaling of Unit Tests for Code Reward Modeling
Jan 02, 2025



Current large language models (LLMs) often struggle to produce accurate responses on the first attempt for complex reasoning tasks like code generation. Prior research tackles this challenge by generating multiple candidate solutions and validating them with LLM-generated unit tests. The execution results of unit tests serve as reward signals to identify correct solutions. As LLMs always confidently make mistakes, these unit tests are not reliable, thereby diminishing the quality of reward signals. Motivated by the observation that scaling the number of solutions improves LLM performance, we explore the impact of scaling unit tests to enhance reward signal quality. Our pioneer experiment reveals a positive correlation between the number of unit tests and reward signal quality, with greater benefits observed in more challenging problems. Based on these insights, we propose CodeRM-8B, a lightweight yet effective unit test generator that enables efficient and high-quality unit test scaling. Additionally, we implement a dynamic scaling mechanism that adapts the number of unit tests based on problem difficulty, further improving efficiency. Experimental results show that our approach significantly improves performance across various models on three benchmarks (e.g., with gains of 18.43% for Llama3-8B and 3.42% for GPT-4o-mini on HumanEval Plus).
Awaking the Slides: A Tuning-free and Knowledge-regulated AI Tutoring System via Language Model Coordination
Sep 11, 2024The vast pre-existing slides serve as rich and important materials to carry lecture knowledge. However, effectively leveraging lecture slides to serve students is difficult due to the multi-modal nature of slide content and the heterogeneous teaching actions. We study the problem of discovering effective designs that convert a slide into an interactive lecture. We develop Slide2Lecture, a tuning-free and knowledge-regulated intelligent tutoring system that can (1) effectively convert an input lecture slide into a structured teaching agenda consisting of a set of heterogeneous teaching actions; (2) create and manage an interactive lecture that generates responsive interactions catering to student learning demands while regulating the interactions to follow teaching actions. Slide2Lecture contains a complete pipeline for learners to obtain an interactive classroom experience to learn the slide. For teachers and developers, Slide2Lecture enables customization to cater to personalized demands. The evaluation rated by annotators and students shows that Slide2Lecture is effective in outperforming the remaining implementation. Slide2Lecture's online deployment has made more than 200K interaction with students in the 3K lecture sessions. We open source Slide2Lecture's implementation in https://anonymous.4open.science/r/slide2lecture-4210/.
From MOOC to MAIC: Reshaping Online Teaching and Learning through LLM-driven Agents
Sep 05, 2024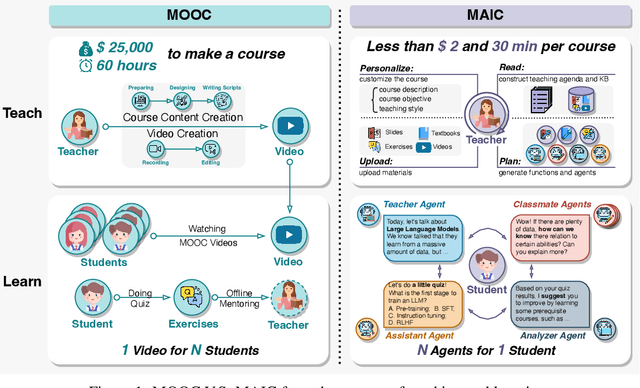
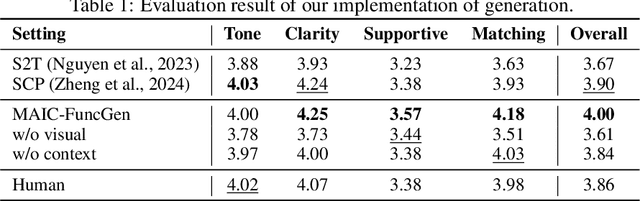
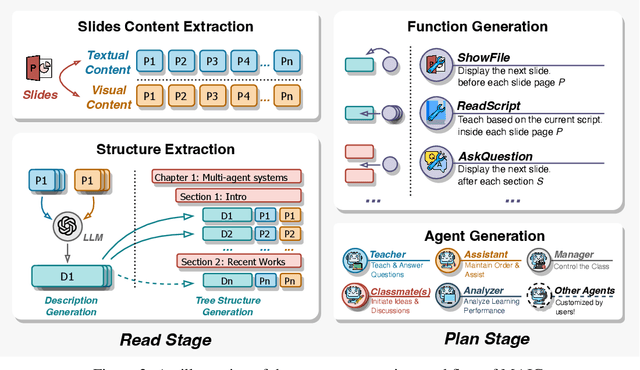

Since the first instances of online education, where courses were uploaded to accessible and shared online platforms, this form of scaling the dissemination of human knowledge to reach a broader audience has sparked extensive discussion and widespread adoption. Recognizing that personalized learning still holds significant potential for improvement, new AI technologies have been continuously integrated into this learning format, resulting in a variety of educational AI applications such as educational recommendation and intelligent tutoring. The emergence of intelligence in large language models (LLMs) has allowed for these educational enhancements to be built upon a unified foundational model, enabling deeper integration. In this context, we propose MAIC (Massive AI-empowered Course), a new form of online education that leverages LLM-driven multi-agent systems to construct an AI-augmented classroom, balancing scalability with adaptivity. Beyond exploring the conceptual framework and technical innovations, we conduct preliminary experiments at Tsinghua University, one of China's leading universities. Drawing from over 100,000 learning records of more than 500 students, we obtain a series of valuable observations and initial analyses. This project will continue to evolve, ultimately aiming to establish a comprehensive open platform that supports and unifies research, technology, and applications in exploring the possibilities of online education in the era of large model AI. We envision this platform as a collaborative hub, bringing together educators, researchers, and innovators to collectively explore the future of AI-driven online education.
Simulating Classroom Education with LLM-Empowered Agents
Jun 27, 2024



Large language models (LLMs) have been employed in various intelligent educational tasks to assist teaching. While preliminary explorations have focused on independent LLM-empowered agents for specific educational tasks, the potential for LLMs within a multi-agent collaborative framework to simulate a classroom with real user participation remains unexplored. In this work, we propose SimClass, a multi-agent classroom simulation framework involving user participation. We recognize representative class roles and introduce a novel class control mechanism for automatic classroom teaching, and conduct user experiments in two real-world courses. Utilizing the Flanders Interactive Analysis System and Community of Inquiry theoretical frame works from educational analysis, we demonstrate that LLMs can simulate traditional classroom interaction patterns effectively while enhancing user's experience. We also observe emergent group behaviors among agents in SimClass, where agents collaborate to create enlivening interactions in classrooms to improve user learning process. We hope this work pioneers the application of LLM-empowered multi-agent systems in virtual classroom teaching.
SpreadsheetBench: Towards Challenging Real World Spreadsheet Manipulation
Jun 21, 2024



We introduce SpreadsheetBench, a challenging spreadsheet manipulation benchmark exclusively derived from real-world scenarios, designed to immerse current large language models (LLMs) in the actual workflow of spreadsheet users. Unlike existing benchmarks that rely on synthesized queries and simplified spreadsheet files, SpreadsheetBench is built from 912 real questions gathered from online Excel forums, which reflect the intricate needs of users. The associated spreadsheets from the forums contain a variety of tabular data such as multiple tables, non-standard relational tables, and abundant non-textual elements. Furthermore, we propose a more reliable evaluation metric akin to online judge platforms, where multiple spreadsheet files are created as test cases for each instruction, ensuring the evaluation of robust solutions capable of handling spreadsheets with varying values. Our comprehensive evaluation of various LLMs under both single-round and multi-round inference settings reveals a substantial gap between the state-of-the-art (SOTA) models and human performance, highlighting the benchmark's difficulty.