 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRPC-Bench: A Fine-grained Benchmark for Research Paper Comprehension
Jan 14, 2026Understanding research papers remains challenging for foundation models due to specialized scientific discourse and complex figures and tables, yet existing benchmarks offer limited fine-grained evaluation at scale. To address this gap, we introduce RPC-Bench, a large-scale question-answering benchmark built from review-rebuttal exchanges of high-quality computer science papers, containing 15K human-verified QA pairs. We design a fine-grained taxonomy aligned with the scientific research flow to assess models' ability to understand and answer why, what, and how questions in scholarly contexts. We also define an elaborate LLM-human interaction annotation framework to support large-scale labeling and quality control. Following the LLM-as-a-Judge paradigm, we develop a scalable framework that evaluates models on correctness-completeness and conciseness, with high agreement to human judgment. Experiments reveal that even the strongest models (GPT-5) achieve only 68.2% correctness-completeness, dropping to 37.46% after conciseness adjustment, highlighting substantial gaps in precise academic paper understanding. Our code and data are available at https://rpc-bench.github.io/.
Handling Students Dropouts in an LLM-driven Interactive Online Course Using Language Models
Aug 24, 2025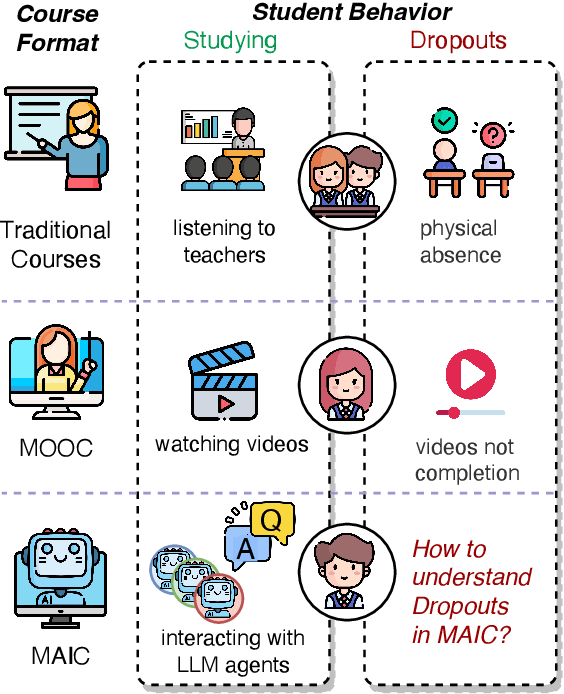
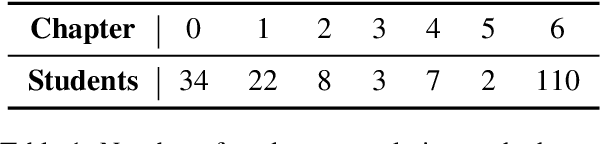
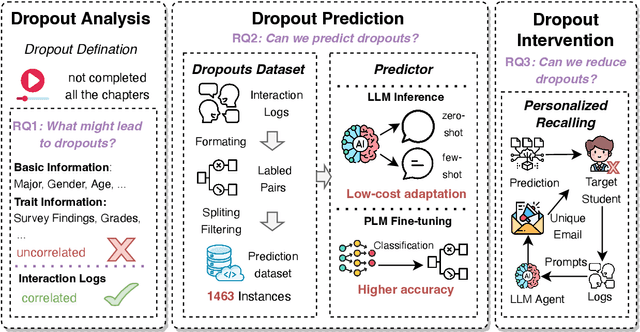
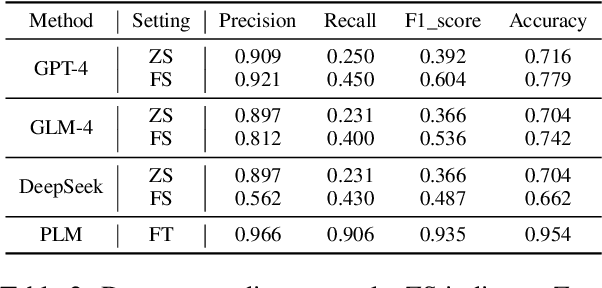
Interactive online learning environments, represented by Massive AI-empowered Courses (MAIC), leverage LLM-driven multi-agent systems to transform passive MOOCs into dynamic, text-based platforms, enhancing interactivity through LLMs. This paper conducts an empirical study on a specific MAIC course to explore three research questions about dropouts in these interactive online courses: (1) What factors might lead to dropouts? (2) Can we predict dropouts? (3) Can we reduce dropouts? We analyze interaction logs to define dropouts and identify contributing factors. Our findings reveal strong links between dropout behaviors and textual interaction patterns. We then propose a course-progress-adaptive dropout prediction framework (CPADP) to predict dropouts with at most 95.4% accuracy. Based on this, we design a personalized email recall agent to re-engage at-risk students. Applied in the deployed MAIC system with over 3,000 students, the feasibility and effectiveness of our approach have been validated on students with diverse backgrounds.
LecEval: An Automated Metric for Multimodal Knowledge Acquisition in Multimedia Learning
May 04, 2025Evaluating the quality of slide-based multimedia instruction is challenging. Existing methods like manual assessment, reference-based metrics, and large language model evaluators face limitations in scalability, context capture, or bias. In this paper, we introduce LecEval, an automated metric grounded in Mayer's Cognitive Theory of Multimedia Learning, to evaluate multimodal knowledge acquisition in slide-based learning. LecEval assesses effectiveness using four rubrics: Content Relevance (CR), Expressive Clarity (EC), Logical Structure (LS), and Audience Engagement (AE). We curate a large-scale dataset of over 2,000 slides from more than 50 online course videos, annotated with fine-grained human ratings across these rubrics. A model trained on this dataset demonstrates superior accuracy and adaptability compared to existing metrics, bridging the gap between automated and human assessments. We release our dataset and toolkits at https://github.com/JoylimJY/LecEval.
From MOOC to MAIC: Reshaping Online Teaching and Learning through LLM-driven Agents
Sep 05, 2024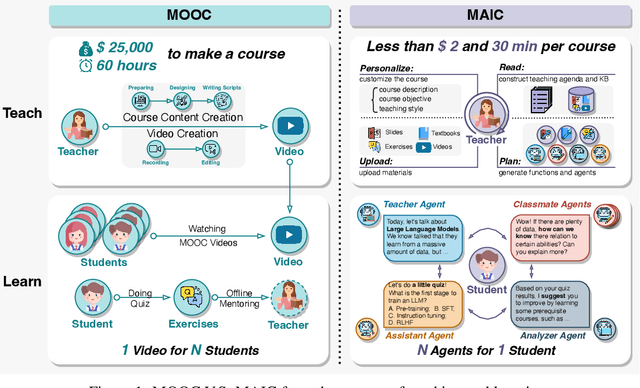

Since the first instances of online education, where courses were uploaded to accessible and shared online platforms, this form of scaling the dissemination of human knowledge to reach a broader audience has sparked extensive discussion and widespread adoption. Recognizing that personalized learning still holds significant potential for improvement, new AI technologies have been continuously integrated into this learning format, resulting in a variety of educational AI applications such as educational recommendation and intelligent tutoring. The emergence of intelligence in large language models (LLMs) has allowed for these educational enhancements to be built upon a unified foundational model, enabling deeper integration. In this context, we propose MAIC (Massive AI-empowered Course), a new form of online education that leverages LLM-driven multi-agent systems to construct an AI-augmented classroom, balancing scalability with adaptivity. Beyond exploring the conceptual framework and technical innovations, we conduct preliminary experiments at Tsinghua University, one of China's leading universities. Drawing from over 100,000 learning records of more than 500 students, we obtain a series of valuable observations and initial analyses. This project will continue to evolve, ultimately aiming to establish a comprehensive open platform that supports and unifies research, technology, and applications in exploring the possibilities of online education in the era of large model AI. We envision this platform as a collaborative hub, bringing together educators, researchers, and innovators to collectively explore the future of AI-driven online education.
R-Eval: A Unified Toolkit for Evaluating Domain Knowledge of Retrieval Augmented Large Language Models
Jun 17, 2024Large language models have achieved remarkable success on general NLP tasks, but they may fall short for domain-specific problems. Recently, various Retrieval-Augmented Large Language Models (RALLMs) are proposed to address this shortcoming. However, existing evaluation tools only provide a few baselines and evaluate them on various domains without mining the depth of domain knowledge. In this paper, we address the challenges of evaluating RALLMs by introducing the R-Eval toolkit, a Python toolkit designed to streamline the evaluation of different RAG workflows in conjunction with LLMs. Our toolkit, which supports popular built-in RAG workflows and allows for the incorporation of customized testing data on the specific domain, is designed to be user-friendly, modular, and extensible. We conduct an evaluation of 21 RALLMs across three task levels and two representative domains, revealing significant variations in the effectiveness of RALLMs across different tasks and domains. Our analysis emphasizes the importance of considering both task and domain requirements when choosing a RAG workflow and LLM combination. We are committed to continuously maintaining our platform at https://github.com/THU-KEG/R-Eval to facilitate both the industry and the researchers.
A Solution-based LLM API-using Methodology for Academic Information Seeking
May 24, 2024Applying large language models (LLMs) for academic API usage shows promise in reducing researchers' academic information seeking efforts. However, current LLM API-using methods struggle with complex API coupling commonly encountered in academic queries. To address this, we introduce SoAy, a solution-based LLM API-using methodology for academic information seeking. It uses code with a solution as the reasoning method, where a solution is a pre-constructed API calling sequence. The addition of the solution reduces the difficulty for the model to understand the complex relationships between APIs. Code improves the efficiency of reasoning. To evaluate SoAy, we introduce SoAyBench, an evaluation benchmark accompanied by SoAyEval, built upon a cloned environment of APIs from AMiner. Experimental results demonstrate a 34.58-75.99\% performance improvement compared to state-of-the-art LLM API-based baselines. All datasets, codes, tuned models, and deployed online services are publicly accessible at https://github.com/RUCKBReasoning/SoAy.
GKD: A General Knowledge Distillation Framework for Large-scale Pre-trained Language Model
Jun 11, 2023



Currently, the reduction in the parameter scale of large-scale pre-trained language models (PLMs) through knowledge distillation has greatly facilitated their widespread deployment on various devices. However, the deployment of knowledge distillation systems faces great challenges in real-world industrial-strength applications, which require the use of complex distillation methods on even larger-scale PLMs (over 10B), limited by memory on GPUs and the switching of methods. To overcome these challenges, we propose GKD, a general knowledge distillation framework that supports distillation on larger-scale PLMs using various distillation methods. With GKD, developers can build larger distillation models on memory-limited GPUs and easily switch and combine different distillation methods within a single framework. Experimental results show that GKD can support the distillation of at least 100B-scale PLMs and 25 mainstream methods on 8 NVIDIA A100 (40GB) GPUs.
Are Intermediate Layers and Labels Really Necessary? A General Language Model Distillation Method
Jun 11, 2023



The large scale of pre-trained language models poses a challenge for their deployment on various devices, with a growing emphasis on methods to compress these models, particularly knowledge distillation. However, current knowledge distillation methods rely on the model's intermediate layer features and the golden labels (also called hard labels), which usually require aligned model architecture and enough labeled data respectively. Moreover, the parameters of vocabulary are usually neglected in existing methods. To address these problems, we propose a general language model distillation (GLMD) method that performs two-stage word prediction distillation and vocabulary compression, which is simple and surprisingly shows extremely strong performance. Specifically, GLMD supports more general application scenarios by eliminating the constraints of dimension and structure between models and the need for labeled datasets through the absence of intermediate layers and golden labels. Meanwhile, based on the long-tailed distribution of word frequencies in the data, GLMD designs a strategy of vocabulary compression through decreasing vocabulary size instead of dimensionality. Experimental results show that our method outperforms 25 state-of-the-art methods on the SuperGLUE benchmark, achieving an average score that surpasses the best method by 3%.