 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Patch Fusion With Class Token Enhancement for Weakly Supervised Semantic Segmentation
Jan 21, 2026Weakly Supervised Semantic Segmentation (WSSS), which relies only on image-level labels, has attracted significant attention for its cost-effectiveness and scalability. Existing methods mainly enhance inter-class distinctions and employ data augmentation to mitigate semantic ambiguity and reduce spurious activations. However, they often neglect the complex contextual dependencies among image patches, resulting in incomplete local representations and limited segmentation accuracy. To address these issues, we propose the Context Patch Fusion with Class Token Enhancement (CPF-CTE) framework, which exploits contextual relations among patches to enrich feature representations and improve segmentation. At its core, the Contextual-Fusion Bidirectional Long Short-Term Memory (CF-BiLSTM) module captures spatial dependencies between patches and enables bidirectional information flow, yielding a more comprehensive understanding of spatial correlations. This strengthens feature learning and segmentation robustness. Moreover, we introduce learnable class tokens that dynamically encode and refine class-specific semantics, enhancing discriminative capability. By effectively integrating spatial and semantic cues, CPF-CTE produces richer and more accurate representations of image content. Extensive experiments on PASCAL VOC 2012 and MS COCO 2014 validate that CPF-CTE consistently surpasses prior WSSS methods.
Handling Students Dropouts in an LLM-driven Interactive Online Course Using Language Models
Aug 24, 2025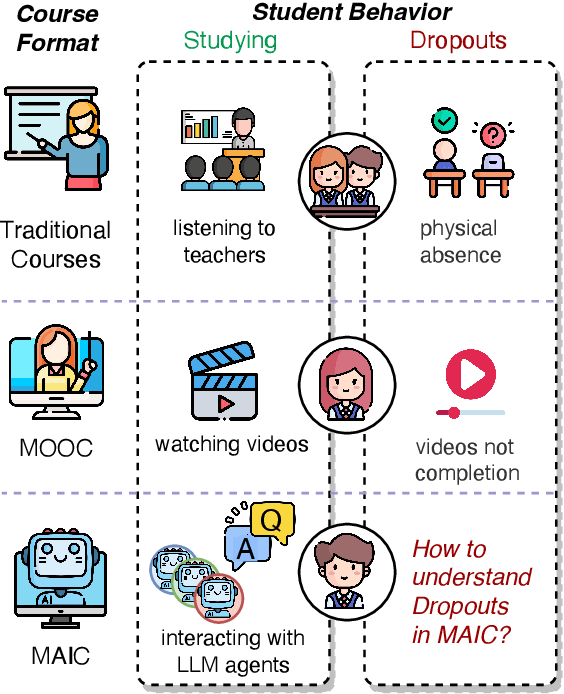
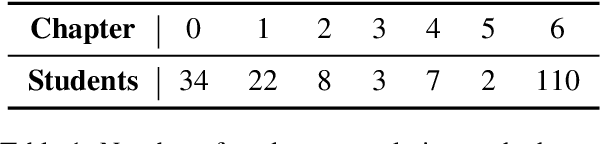
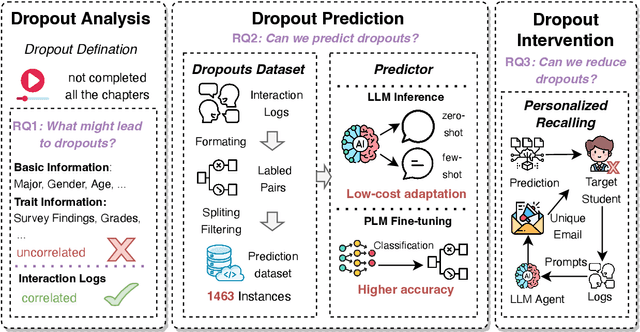
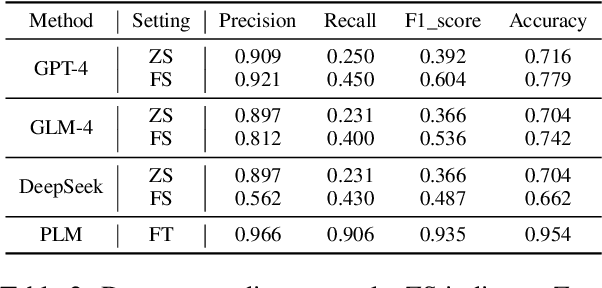
Interactive online learning environments, represented by Massive AI-empowered Courses (MAIC), leverage LLM-driven multi-agent systems to transform passive MOOCs into dynamic, text-based platforms, enhancing interactivity through LLMs. This paper conducts an empirical study on a specific MAIC course to explore three research questions about dropouts in these interactive online courses: (1) What factors might lead to dropouts? (2) Can we predict dropouts? (3) Can we reduce dropouts? We analyze interaction logs to define dropouts and identify contributing factors. Our findings reveal strong links between dropout behaviors and textual interaction patterns. We then propose a course-progress-adaptive dropout prediction framework (CPADP) to predict dropouts with at most 95.4% accuracy. Based on this, we design a personalized email recall agent to re-engage at-risk students. Applied in the deployed MAIC system with over 3,000 students, the feasibility and effectiveness of our approach have been validated on students with diverse backgrounds.
A Solution-based LLM API-using Methodology for Academic Information Seeking
May 24, 2024Applying large language models (LLMs) for academic API usage shows promise in reducing researchers' academic information seeking efforts. However, current LLM API-using methods struggle with complex API coupling commonly encountered in academic queries. To address this, we introduce SoAy, a solution-based LLM API-using methodology for academic information seeking. It uses code with a solution as the reasoning method, where a solution is a pre-constructed API calling sequence. The addition of the solution reduces the difficulty for the model to understand the complex relationships between APIs. Code improves the efficiency of reasoning. To evaluate SoAy, we introduce SoAyBench, an evaluation benchmark accompanied by SoAyEval, built upon a cloned environment of APIs from AMiner. Experimental results demonstrate a 34.58-75.99\% performance improvement compared to state-of-the-art LLM API-based baselines. All datasets, codes, tuned models, and deployed online services are publicly accessible at https://github.com/RUCKBReasoning/SoAy.