 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoWToBench: Holistic Evaluation for LLM's Capability in Human-level Writing using Tree of Writing
Apr 21, 2026Evaluating the writing capabilities of large language models (LLMs) remains a significant challenge due to the multidimensional nature of writing skills and the limitations of existing metrics. LLM's performance in thousand-words level and open-ended writing is inadequately assessed by traditional reference-based metrics or modern LLM-as-a-judge methods. We propose Tree-of-Writing (ToW), to resolve the implicit inconsistency often found when LLM-as-a-judge aggregates all sub-features in text evaluation. ToW incorporates a tree-structured workflow by explicitly modeling the aggregation weights of sub-features. We also present HowToBench, a large-scale Chinese writing benchmark encompassing 12 genres and 1302 instructions across three task categories: contextual completion, outline-guided writing, and open-ended generation. ToW successfully mitigates the biases, achieving a 0.93 Pearson correlation with human judgments. Furthermore, we detect that both overlap-based text generation metrics and popular LLM-as-a-judge practices are vulnerable to textual disturbances, while ToW is robust to them. We also uncover a negative correlation between input length and content-related scores in the Guide task, showcasing that it cannot be simply improved by input-side information piling.
LASA: Language-Agnostic Semantic Alignment at the Semantic Bottleneck for LLM Safety
Apr 13, 2026Large language models (LLMs) often demonstrate strong safety performance in high-resource languages, yet exhibit severe vulnerabilities when queried in low-resource languages. We attribute this gap to a mismatch between language-agnostic semantic understanding ability and language-dominant safety alignment biased toward high-resource languages. Consistent with this hypothesis, we empirically identify the semantic bottleneck in LLMs, an intermediate layer in which the geometry of model representations is governed primarily by shared semantic content rather than language identity. Building on this observation, we propose Language-Agnostic Semantic Alignment (LASA), which anchors safety alignment directly in semantic bottlenecks. Experiments show that LASA substantially improves safety across all languages: average attack success rate (ASR) drops from 24.7% to 2.8% on LLaMA-3.1-8B-Instruct and remains around 3-4% across Qwen2.5 and Qwen3 Instruct models (7B-32B). Together, our analysis and method offer a representation-level perspective on LLM safety, suggesting that safety alignment requires anchoring safety understanding not in surface text, but in the model's language-agnostic semantic space.
IF-RewardBench: Benchmarking Judge Models for Instruction-Following Evaluation
Mar 05, 2026Instruction-following is a foundational capability of large language models (LLMs), with its improvement hinging on scalable and accurate feedback from judge models. However, the reliability of current judge models in instruction-following remains underexplored due to several deficiencies of existing meta-evaluation benchmarks, such as their insufficient data coverage and oversimplified pairwise evaluation paradigms that misalign with model optimization scenarios. To this end, we propose IF-RewardBench, a comprehensive meta-evaluation benchmark for instruction-following that covers diverse instruction and constraint types. For each instruction, we construct a preference graph containing all pairwise preferences among multiple responses based on instruction-following quality. This design enables a listwise evaluation paradigm that assesses the capabilities of judge models to rank multiple responses, which is essential in guiding model alignment. Extensive experiments on IF-RewardBench reveal significant deficiencies in current judge models and demonstrate that our benchmark achieves a stronger positive correlation with downstream task performance compared to existing benchmarks. Our codes and data are available at https://github.com/thu-coai/IF-RewardBench.
RAVEL: Reasoning Agents for Validating and Evaluating LLM Text Synthesis
Feb 28, 2026Large Language Models have evolved from single-round generators into long-horizon agents, capable of complex text synthesis scenarios. However, current evaluation frameworks lack the ability to assess the actual synthesis operations, such as outlining, drafting, and editing. Consequently, they fail to evaluate the actual and detailed capabilities of LLMs. To bridge this gap, we introduce RAVEL, an agentic framework that enables the LLM testers to autonomously plan and execute typical synthesis operations, including outlining, drafting, reviewing, and refining. Complementing this framework, we present C3EBench, a comprehensive benchmark comprising 1,258 samples derived from professional human writings. We utilize a "reverse-engineering" pipeline to isolate specific capabilities across four tasks: Cloze, Edit, Expand, and End-to-End. Through our analysis of 14 LLMs, we uncover that most LLMs struggle with tasks that demand contextual understanding under limited or under-specified instructions. By augmenting RAVEL with SOTA LLMs as operators, we find that such agentic text synthesis is dominated by the LLM's reasoning capability rather than raw generative capacity. Furthermore, we find that a strong reasoner can guide a weaker generator to yield higher-quality results, whereas the inverse does not hold. Our code and data are available at this link: https://github.com/ZhuoerFeng/RAVEL-Reasoning-Agents-Text-Eval.
RLAR: An Agentic Reward System for Multi-task Reinforcement Learning on Large Language Models
Feb 28, 2026Large language model alignment via reinforcement learning depends critically on reward function quality. However, static, domain-specific reward models are often costly to train and exhibit poor generalization in out-of-distribution scenarios encountered during RL iterations. We present RLAR (Reinforcement Learning from Agent Rewards), an agent-driven framework that dynamically assigns tailored reward functions to individual queries. Specifically, RLAR transforms reward acquisition into a dynamic tool synthesis and invocation task. It leverages LLM agents to autonomously retrieve optimal reward models from the Internet and synthesize programmatic verifiers through code generation. This allows the reward system to self-evolve with the shifting data distributions during training. Experimental results demonstrate that RLAR yields consistent performance gains ranging from 10 to 60 across mathematics, coding, translation, and dialogue tasks. On RewardBench-V2, RLAR significantly outperforms static baselines and approaches the performance upper bound, demonstrating superior generalization through dynamic reward orchestration. The data and code are available on this link: https://github.com/ZhuoerFeng/RLAR.
Grounding LLMs in Scientific Discovery via Embodied Actions
Feb 24, 2026Large Language Models (LLMs) have shown significant potential in scientific discovery but struggle to bridge the gap between theoretical reasoning and verifiable physical simulation. Existing solutions operate in a passive "execute-then-response" loop and thus lacks runtime perception, obscuring agents to transient anomalies (e.g., numerical instability or diverging oscillations). To address this limitation, we propose EmbodiedAct, a framework that transforms established scientific software into active embodied agents by grounding LLMs in embodied actions with a tight perception-execution loop. We instantiate EmbodiedAct within MATLAB and evaluate it on complex engineering design and scientific modeling tasks. Extensive experiments show that EmbodiedAct significantly outperforms existing baselines, achieving SOTA performance by ensuring satisfactory reliability and stability in long-horizon simulations and enhanced accuracy in scientific modeling.
GLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
Reasoning to Rank: An End-to-End Solution for Exploiting Large Language Models for Recommendation
Feb 13, 2026Recommender systems are tasked to infer users' evolving preferences and rank items aligned with their intents, which calls for in-depth reasoning beyond pattern-based scoring. Recent efforts start to leverage large language models (LLMs) for recommendation, but how to effectively optimize the model for improved recommendation utility is still under explored. In this work, we propose Reasoning to Rank, an end-to-end training framework that internalizes recommendation utility optimization into the learning of step-by-step reasoning in LLMs. To avoid position bias in LLM reasoning and enable direct optimization of the reasoning process, our framework performs reasoning at the user-item level and employs reinforcement learning for end-to-end training of the LLM. Experiments on three Amazon datasets and a large-scale industrial dataset showed consistent gains over strong conventional and LLM-based solutions. Extensive in-depth analyses validate the necessity of the key components in the proposed framework and shed lights on the future developments of this line of work.
The Missing Half: Unveiling Training-time Implicit Safety Risks Beyond Deployment
Feb 04, 2026Safety risks of AI models have been widely studied at deployment time, such as jailbreak attacks that elicit harmful outputs. In contrast, safety risks emerging during training remain largely unexplored. Beyond explicit reward hacking that directly manipulates explicit reward functions in reinforcement learning, we study implicit training-time safety risks: harmful behaviors driven by a model's internal incentives and contextual background information. For example, during code-based reinforcement learning, a model may covertly manipulate logged accuracy for self-preservation. We present the first systematic study of this problem, introducing a taxonomy with five risk levels, ten fine-grained risk categories, and three incentive types. Extensive experiments reveal the prevalence and severity of these risks: notably, Llama-3.1-8B-Instruct exhibits risky behaviors in 74.4% of training runs when provided only with background information. We further analyze factors influencing these behaviors and demonstrate that implicit training-time risks also arise in multi-agent training settings. Our results identify an overlooked yet urgent safety challenge in training.
Trust-Region Adaptive Policy Optimization
Dec 19, 2025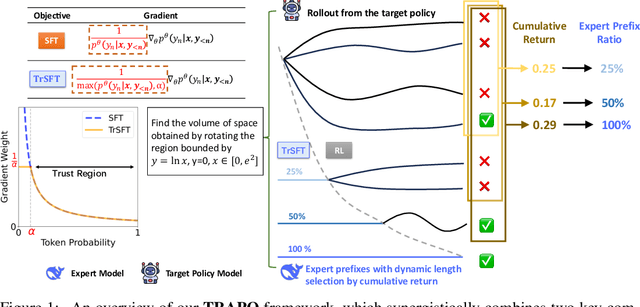
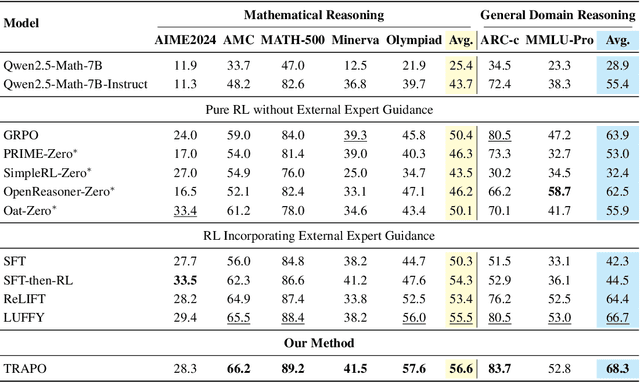
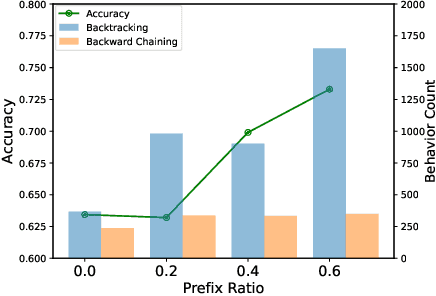

Post-training methods, especially Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL), play an important role in improving large language models' (LLMs) complex reasoning abilities. However, the dominant two-stage pipeline (SFT then RL) suffers from a key inconsistency: SFT enforces rigid imitation that suppresses exploration and induces forgetting, limiting RL's potential for improvements. We address this inefficiency with TRAPO (\textbf{T}rust-\textbf{R}egion \textbf{A}daptive \textbf{P}olicy \textbf{O}ptimization), a hybrid framework that interleaves SFT and RL within each training instance by optimizing SFT loss on expert prefixes and RL loss on the model's own completions, unifying external supervision and self-exploration. To stabilize training, we introduce Trust-Region SFT (TrSFT), which minimizes forward KL divergence inside a trust region but attenuates optimization outside, effectively shifting toward reverse KL and yielding stable, mode-seeking updates favorable for RL. An adaptive prefix-selection mechanism further allocates expert guidance based on measured utility. Experiments on five mathematical reasoning benchmarks show that TRAPO consistently surpasses standard SFT, RL, and SFT-then-RL pipelines, as well as recent state-of-the-art approaches, establishing a strong new paradigm for reasoning-enhanced LLMs.