 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVPO: Aligning Text-to-Video Generation Models with Prompt Optimization
Mar 26, 2025

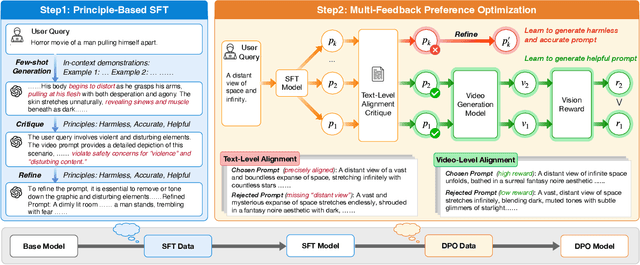
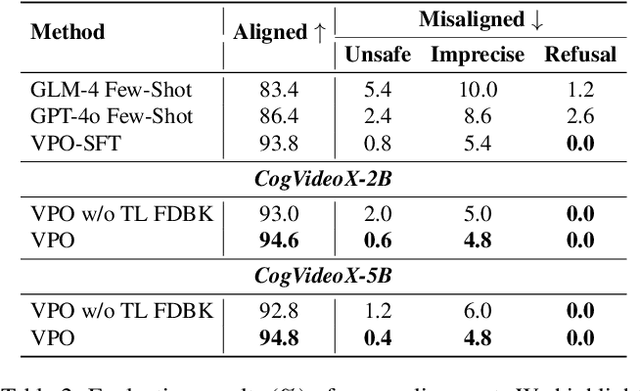
Video generation models have achieved remarkable progress in text-to-video tasks. These models are typically trained on text-video pairs with highly detailed and carefully crafted descriptions, while real-world user inputs during inference are often concise, vague, or poorly structured. This gap makes prompt optimization crucial for generating high-quality videos. Current methods often rely on large language models (LLMs) to refine prompts through in-context learning, but suffer from several limitations: they may distort user intent, omit critical details, or introduce safety risks. Moreover, they optimize prompts without considering the impact on the final video quality, which can lead to suboptimal results. To address these issues, we introduce VPO, a principled framework that optimizes prompts based on three core principles: harmlessness, accuracy, and helpfulness. The generated prompts faithfully preserve user intents and, more importantly, enhance the safety and quality of generated videos. To achieve this, VPO employs a two-stage optimization approach. First, we construct and refine a supervised fine-tuning (SFT) dataset based on principles of safety and alignment. Second, we introduce both text-level and video-level feedback to further optimize the SFT model with preference learning. Our extensive experiments demonstrate that VPO significantly improves safety, alignment, and video quality compared to baseline methods. Moreover, VPO shows strong generalization across video generation models. Furthermore, we demonstrate that VPO could outperform and be combined with RLHF methods on video generation models, underscoring the effectiveness of VPO in aligning video generation models. Our code and data are publicly available at https://github.com/thu-coai/VPO.
Concat-ID: Towards Universal Identity-Preserving Video Synthesis
Mar 18, 2025We present Concat-ID, a unified framework for identity-preserving video generation. Concat-ID employs Variational Autoencoders to extract image features, which are concatenated with video latents along the sequence dimension, leveraging solely 3D self-attention mechanisms without the need for additional modules. A novel cross-video pairing strategy and a multi-stage training regimen are introduced to balance identity consistency and facial editability while enhancing video naturalness. Extensive experiments demonstrate Concat-ID's superiority over existing methods in both single and multi-identity generation, as well as its seamless scalability to multi-subject scenarios, including virtual try-on and background-controllable generation. Concat-ID establishes a new benchmark for identity-preserving video synthesis, providing a versatile and scalable solution for a wide range of applications.
VisionReward: Fine-Grained Multi-Dimensional Human Preference Learning for Image and Video Generation
Dec 30, 2024We present a general strategy to aligning visual generation models -- both image and video generation -- with human preference. To start with, we build VisionReward -- a fine-grained and multi-dimensional reward model. We decompose human preferences in images and videos into multiple dimensions, each represented by a series of judgment questions, linearly weighted and summed to an interpretable and accurate score. To address the challenges of video quality assessment, we systematically analyze various dynamic features of videos, which helps VisionReward surpass VideoScore by 17.2% and achieve top performance for video preference prediction. Based on VisionReward, we develop a multi-objective preference learning algorithm that effectively addresses the issue of confounding factors within preference data. Our approach significantly outperforms existing image and video scoring methods on both machine metrics and human evaluation. All code and datasets are provided at https://github.com/THUDM/VisionReward.
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Aug 12, 2024We introduce CogVideoX, a large-scale diffusion transformer model designed for generating videos based on text prompts. To efficently model video data, we propose to levearge a 3D Variational Autoencoder (VAE) to compress videos along both spatial and temporal dimensions. To improve the text-video alignment, we propose an expert transformer with the expert adaptive LayerNorm to facilitate the deep fusion between the two modalities. By employing a progressive training technique, CogVideoX is adept at producing coherent, long-duration videos characterized by significant motions. In addition, we develop an effective text-video data processing pipeline that includes various data preprocessing strategies and a video captioning method. It significantly helps enhance the performance of CogVideoX, improving both generation quality and semantic alignment. Results show that CogVideoX demonstrates state-of-the-art performance across both multiple machine metrics and human evaluations. The model weights of both the 3D Causal VAE and CogVideoX are publicly available at https://github.com/THUDM/CogVideo.
Inf-DiT: Upsampling Any-Resolution Image with Memory-Efficient Diffusion Transformer
May 08, 2024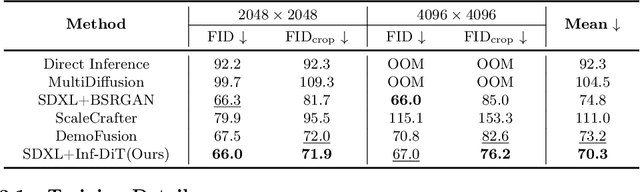
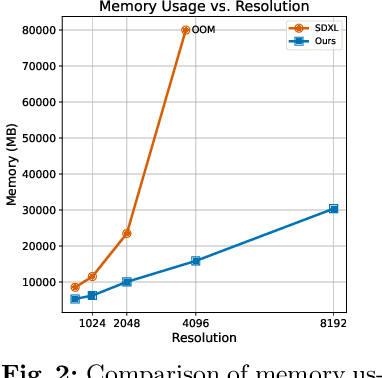

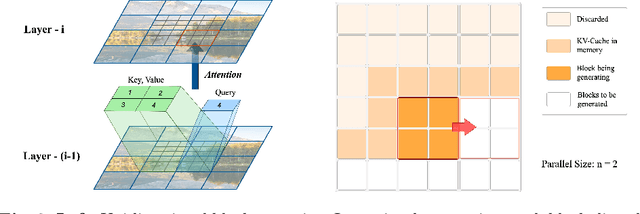
Diffusion models have shown remarkable performance in image generation in recent years. However, due to a quadratic increase in memory during generating ultra-high-resolution images (e.g. 4096*4096), the resolution of generated images is often limited to 1024*1024. In this work. we propose a unidirectional block attention mechanism that can adaptively adjust the memory overhead during the inference process and handle global dependencies. Building on this module, we adopt the DiT structure for upsampling and develop an infinite super-resolution model capable of upsampling images of various shapes and resolutions. Comprehensive experiments show that our model achieves SOTA performance in generating ultra-high-resolution images in both machine and human evaluation. Compared to commonly used UNet structures, our model can save more than 5x memory when generating 4096*4096 images. The project URL is https://github.com/THUDM/Inf-DiT.
CogView3: Finer and Faster Text-to-Image Generation via Relay Diffusion
Mar 08, 2024



Recent advancements in text-to-image generative systems have been largely driven by diffusion models. However, single-stage text-to-image diffusion models still face challenges, in terms of computational efficiency and the refinement of image details. To tackle the issue, we propose CogView3, an innovative cascaded framework that enhances the performance of text-to-image diffusion. CogView3 is the first model implementing relay diffusion in the realm of text-to-image generation, executing the task by first creating low-resolution images and subsequently applying relay-based super-resolution. This methodology not only results in competitive text-to-image outputs but also greatly reduces both training and inference costs. Our experimental results demonstrate that CogView3 outperforms SDXL, the current state-of-the-art open-source text-to-image diffusion model, by 77.0\% in human evaluations, all while requiring only about 1/2 of the inference time. The distilled variant of CogView3 achieves comparable performance while only utilizing 1/10 of the inference time by SDXL.
Relay Diffusion: Unifying diffusion process across resolutions for image synthesis
Sep 04, 2023Diffusion models achieved great success in image synthesis, but still face challenges in high-resolution generation. Through the lens of discrete cosine transformation, we find the main reason is that \emph{the same noise level on a higher resolution results in a higher Signal-to-Noise Ratio in the frequency domain}. In this work, we present Relay Diffusion Model (RDM), which transfers a low-resolution image or noise into an equivalent high-resolution one for diffusion model via blurring diffusion and block noise. Therefore, the diffusion process can continue seamlessly in any new resolution or model without restarting from pure noise or low-resolution conditioning. RDM achieves state-of-the-art FID on CelebA-HQ and sFID on ImageNet 256$\times$256, surpassing previous works such as ADM, LDM and DiT by a large margin. All the codes and checkpoints are open-sourced at \url{https://github.com/THUDM/RelayDiffusion}.
MIntRec: A New Dataset for Multimodal Intent Recognition
Sep 09, 2022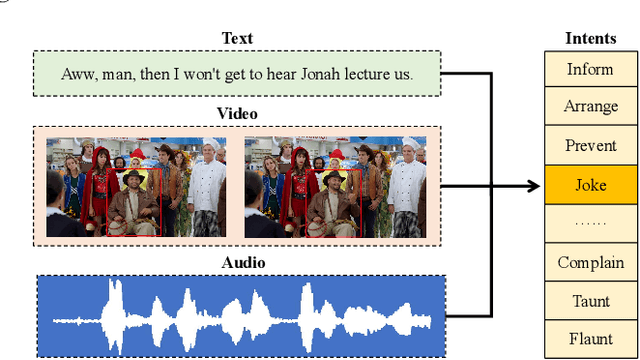

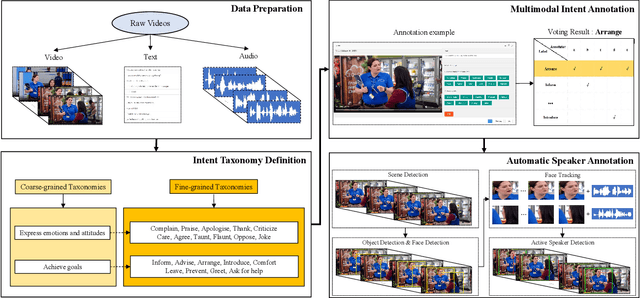

Multimodal intent recognition is a significant task for understanding human language in real-world multimodal scenes. Most existing intent recognition methods have limitations in leveraging the multimodal information due to the restrictions of the benchmark datasets with only text information. This paper introduces a novel dataset for multimodal intent recognition (MIntRec) to address this issue. It formulates coarse-grained and fine-grained intent taxonomies based on the data collected from the TV series Superstore. The dataset consists of 2,224 high-quality samples with text, video, and audio modalities and has multimodal annotations among twenty intent categories. Furthermore, we provide annotated bounding boxes of speakers in each video segment and achieve an automatic process for speaker annotation. MIntRec is helpful for researchers to mine relationships between different modalities to enhance the capability of intent recognition. We extract features from each modality and model cross-modal interactions by adapting three powerful multimodal fusion methods to build baselines. Extensive experiments show that employing the non-verbal modalities achieves substantial improvements compared with the text-only modality, demonstrating the effectiveness of using multimodal information for intent recognition. The gap between the best-performing methods and humans indicates the challenge and importance of this task for the community. The full dataset and codes are available for use at https://github.com/thuiar/MIntRec.