 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCogVLM2: Visual Language Models for Image and Video Understanding
Aug 29, 2024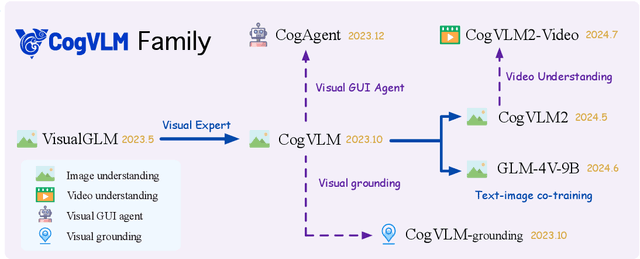

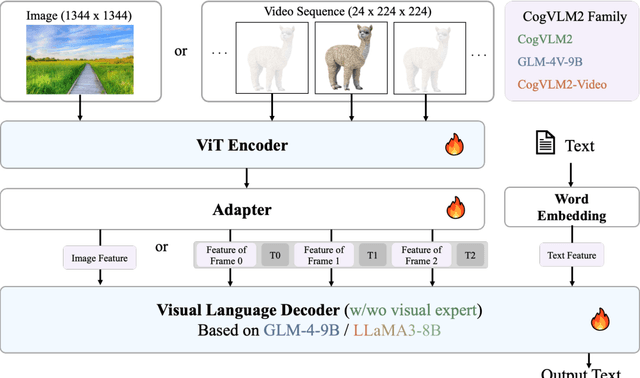
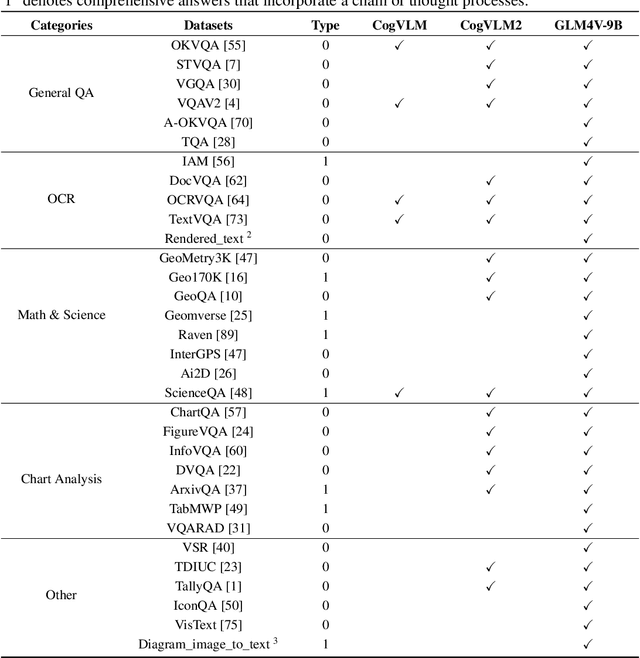
Beginning with VisualGLM and CogVLM, we are continuously exploring VLMs in pursuit of enhanced vision-language fusion, efficient higher-resolution architecture, and broader modalities and applications. Here we propose the CogVLM2 family, a new generation of visual language models for image and video understanding including CogVLM2, CogVLM2-Video and GLM-4V. As an image understanding model, CogVLM2 inherits the visual expert architecture with improved training recipes in both pre-training and post-training stages, supporting input resolution up to $1344 \times 1344$ pixels. As a video understanding model, CogVLM2-Video integrates multi-frame input with timestamps and proposes automated temporal grounding data construction. Notably, CogVLM2 family has achieved state-of-the-art results on benchmarks like MMBench, MM-Vet, TextVQA, MVBench and VCGBench. All models are open-sourced in https://github.com/THUDM/CogVLM2 and https://github.com/THUDM/GLM-4, contributing to the advancement of the field.
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Aug 12, 2024We introduce CogVideoX, a large-scale diffusion transformer model designed for generating videos based on text prompts. To efficently model video data, we propose to levearge a 3D Variational Autoencoder (VAE) to compress videos along both spatial and temporal dimensions. To improve the text-video alignment, we propose an expert transformer with the expert adaptive LayerNorm to facilitate the deep fusion between the two modalities. By employing a progressive training technique, CogVideoX is adept at producing coherent, long-duration videos characterized by significant motions. In addition, we develop an effective text-video data processing pipeline that includes various data preprocessing strategies and a video captioning method. It significantly helps enhance the performance of CogVideoX, improving both generation quality and semantic alignment. Results show that CogVideoX demonstrates state-of-the-art performance across both multiple machine metrics and human evaluations. The model weights of both the 3D Causal VAE and CogVideoX are publicly available at https://github.com/THUDM/CogVideo.
SampleAttention: Near-Lossless Acceleration of Long Context LLM Inference with Adaptive Structured Sparse Attention
Jun 28, 2024Large language models (LLMs) now support extremely long context windows, but the quadratic complexity of vanilla attention results in significantly long Time-to-First-Token (TTFT) latency. Existing approaches to address this complexity require additional pretraining or finetuning, and often sacrifice model accuracy. In this paper, we first provide both theoretical and empirical foundations for near-lossless sparse attention. We find dynamically capturing head-specific sparse patterns at runtime with low overhead is crucial. To address this, we propose SampleAttention, an adaptive structured and near-lossless sparse attention. Leveraging observed significant sparse patterns, SampleAttention attends to a fixed percentage of adjacent tokens to capture local window patterns, and employs a two-stage query-guided key-value filtering approach, which adaptively select a minimum set of key-values with low overhead, to capture column stripe patterns. Comprehensive evaluations show that SampleAttention can seamlessly replace vanilla attention in off-the-shelf LLMs with nearly no accuracy loss, and reduces TTFT by up to $2.42\times$ compared with FlashAttention.
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Jun 18, 2024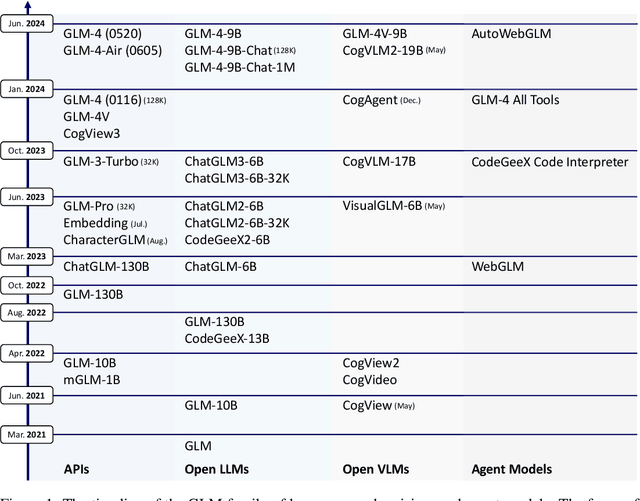
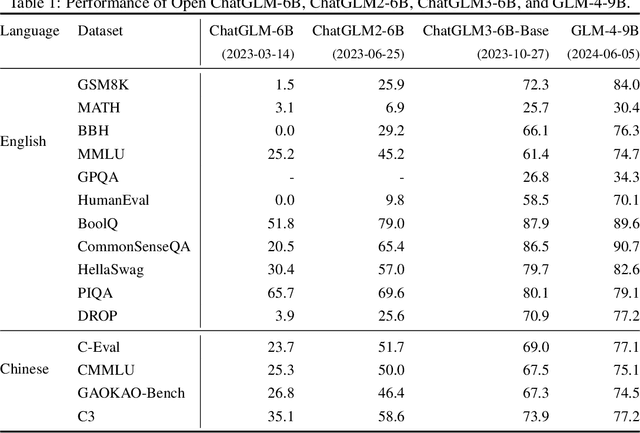
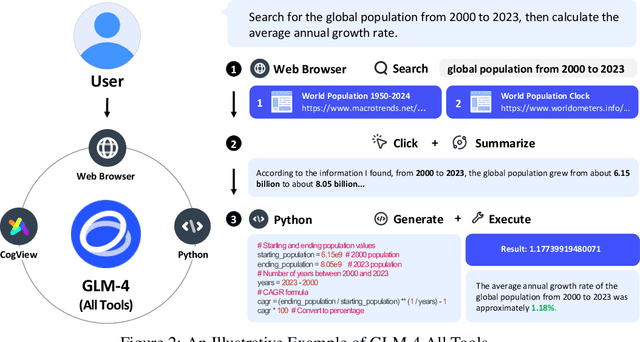
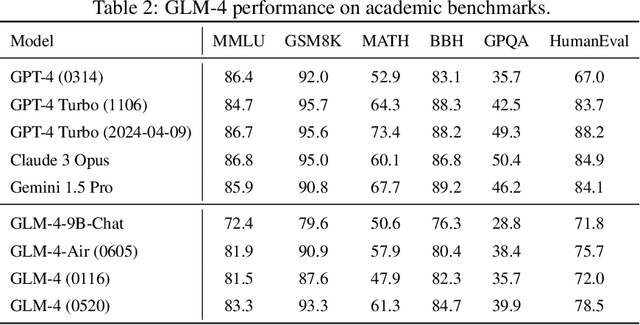
We introduce ChatGLM, an evolving family of large language models that we have been developing over time. This report primarily focuses on the GLM-4 language series, which includes GLM-4, GLM-4-Air, and GLM-4-9B. They represent our most capable models that are trained with all the insights and lessons gained from the preceding three generations of ChatGLM. To date, the GLM-4 models are pre-trained on ten trillions of tokens mostly in Chinese and English, along with a small set of corpus from 24 languages, and aligned primarily for Chinese and English usage. The high-quality alignment is achieved via a multi-stage post-training process, which involves supervised fine-tuning and learning from human feedback. Evaluations show that GLM-4 1) closely rivals or outperforms GPT-4 in terms of general metrics such as MMLU, GSM8K, MATH, BBH, GPQA, and HumanEval, 2) gets close to GPT-4-Turbo in instruction following as measured by IFEval, 3) matches GPT-4 Turbo (128K) and Claude 3 for long context tasks, and 4) outperforms GPT-4 in Chinese alignments as measured by AlignBench. The GLM-4 All Tools model is further aligned to understand user intent and autonomously decide when and which tool(s) touse -- including web browser, Python interpreter, text-to-image model, and user-defined functions -- to effectively complete complex tasks. In practical applications, it matches and even surpasses GPT-4 All Tools in tasks like accessing online information via web browsing and solving math problems using Python interpreter. Over the course, we have open-sourced a series of models, including ChatGLM-6B (three generations), GLM-4-9B (128K, 1M), GLM-4V-9B, WebGLM, and CodeGeeX, attracting over 10 million downloads on Hugging face in the year 2023 alone. The open models can be accessed through https://github.com/THUDM and https://huggingface.co/THUDM.
Near-Lossless Acceleration of Long Context LLM Inference with Adaptive Structured Sparse Attention
Jun 17, 2024Large language models (LLMs) now support extremely long context windows, but the quadratic complexity of vanilla attention results in significantly long Time-to-First-Token (TTFT) latency. Existing approaches to address this complexity require additional pretraining or finetuning, and often sacrifice model accuracy. In this paper, we first provide both theoretical and empirical foundations for near-lossless sparse attention. We find dynamically capturing head-specific sparse patterns at runtime with low overhead is crucial. To address this, we propose SampleAttention, an adaptive structured and near-lossless sparse attention. Leveraging observed significant sparse patterns, SampleAttention attends to a fixed percentage of adjacent tokens to capture local window patterns, and employs a two-stage query-guided key-value filtering approach, which adaptively select a minimum set of key-values with low overhead, to capture column stripe patterns. Comprehensive evaluations show that SampleAttention can seamlessly replace vanilla attention in off-the-shelf LLMs with nearly no accuracy loss, and reduces TTFT by up to $2.42\times$ compared with FlashAttention.