 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRRAttention: Dynamic Block Sparse Attention via Per-Head Round-Robin Shifts for Long-Context Inference
Feb 05, 2026The quadratic complexity of attention mechanisms poses a critical bottleneck for large language models processing long contexts. While dynamic sparse attention methods offer input-adaptive efficiency, they face fundamental trade-offs: requiring preprocessing, lacking global evaluation, violating query independence, or incurring high computational overhead. We present RRAttention, a novel dynamic sparse attention method that simultaneously achieves all desirable properties through a head \underline{r}ound-\underline{r}obin (RR) sampling strategy. By rotating query sampling positions across attention heads within each stride, RRAttention maintains query independence while enabling efficient global pattern discovery with stride-level aggregation. Our method reduces complexity from $O(L^2)$ to $O(L^2/S^2)$ and employs adaptive Top-$τ$ selection for optimal sparsity. Extensive experiments on natural language understanding (HELMET) and multimodal video comprehension (Video-MME) demonstrate that RRAttention recovers over 99\% of full attention performance while computing only half of the attention blocks, achieving 2.4$\times$ speedup at 128K context length and outperforming existing dynamic sparse attention methods.
A Unified Sparse Attention via Multi-Granularity Compression
Dec 16, 2025



Efficient long-context understanding and reasoning are increasingly vital for large language model (LLM) applications such as multi-turn dialogue and program analysis. However, the core self-attention mechanism scales quadratically with sequence length, creating a fundamental computational bottleneck. Existing sparse attention methods alleviate this issue but face trade-offs: training-based methods are costly and cannot be directly applied as acceleration plugins for other models, while inference-time methods often compromise efficiency or cross-modal generality. To address these limitations, we present UniSparse, a unified mechanism that introduces the notion of composite tokens--compact representations that aggregate multi-granularity contextual information. Building on this abstraction, UniSparse dynamically constructs sparse attention through multi-granularity compression and block-level selection, enabling efficient and hardware-friendly execution on GPU. Across multiple modalities and tasks ranging from synthetic benchmarks to real-world applications, UniSparse consistently surpasses state-of-the-art sparse attention methods (e.g., MInference, XAttention, FlexPrefill) in both accuracy and efficiency, achieving $\ge$ 99% of full-attention accuracy and up to 2.61$\times$ faster attention computation than FlashAttention.
Gaussian Invariant Markov Chain Monte Carlo
Jun 26, 2025We develop sampling methods, which consist of Gaussian invariant versions of random walk Metropolis (RWM), Metropolis adjusted Langevin algorithm (MALA) and second order Hessian or Manifold MALA. Unlike standard RWM and MALA we show that Gaussian invariant sampling can lead to ergodic estimators with improved statistical efficiency. This is due to a remarkable property of Gaussian invariance that allows us to obtain exact analytical solutions to the Poisson equation for Gaussian targets. These solutions can be used to construct efficient and easy to use control variates for variance reduction of estimators under any intractable target. We demonstrate the new samplers and estimators in several examples, including high dimensional targets in latent Gaussian models where we compare against several advanced methods and obtain state-of-the-art results. We also provide theoretical results regarding geometric ergodicity, and an optimal scaling analysis that shows the dependence of the optimal acceptance rate on the Gaussianity of the target.
HeteroSpec: Leveraging Contextual Heterogeneity for Efficient Speculative Decoding
May 19, 2025Autoregressive decoding, the standard approach for Large Language Model (LLM) inference, remains a significant bottleneck due to its sequential nature. While speculative decoding algorithms mitigate this inefficiency through parallel verification, they fail to exploit the inherent heterogeneity in linguistic complexity, a key factor leading to suboptimal resource allocation. We address this by proposing HeteroSpec, a heterogeneity-adaptive speculative decoding framework that dynamically optimizes computational resource allocation based on linguistic context complexity. HeteroSpec introduces two key mechanisms: (1) A novel cumulative meta-path Top-$K$ entropy metric for efficiently identifying predictable contexts. (2) A dynamic resource allocation strategy based on data-driven entropy partitioning, enabling adaptive speculative expansion and pruning tailored to local context difficulty. Evaluated on five public benchmarks and four models, HeteroSpec achieves an average speedup of 4.26$\times$. It consistently outperforms state-of-the-art EAGLE-3 across speedup rates, average acceptance length, and verification cost. Notably, HeteroSpec requires no draft model retraining, incurs minimal overhead, and is orthogonal to other acceleration techniques. It demonstrates enhanced acceleration with stronger draft models, establishing a new paradigm for context-aware LLM inference acceleration.
SampleAttention: Near-Lossless Acceleration of Long Context LLM Inference with Adaptive Structured Sparse Attention
Jun 28, 2024Large language models (LLMs) now support extremely long context windows, but the quadratic complexity of vanilla attention results in significantly long Time-to-First-Token (TTFT) latency. Existing approaches to address this complexity require additional pretraining or finetuning, and often sacrifice model accuracy. In this paper, we first provide both theoretical and empirical foundations for near-lossless sparse attention. We find dynamically capturing head-specific sparse patterns at runtime with low overhead is crucial. To address this, we propose SampleAttention, an adaptive structured and near-lossless sparse attention. Leveraging observed significant sparse patterns, SampleAttention attends to a fixed percentage of adjacent tokens to capture local window patterns, and employs a two-stage query-guided key-value filtering approach, which adaptively select a minimum set of key-values with low overhead, to capture column stripe patterns. Comprehensive evaluations show that SampleAttention can seamlessly replace vanilla attention in off-the-shelf LLMs with nearly no accuracy loss, and reduces TTFT by up to $2.42\times$ compared with FlashAttention.
Can independent Metropolis beat crude Monte Carlo?
Jun 25, 2024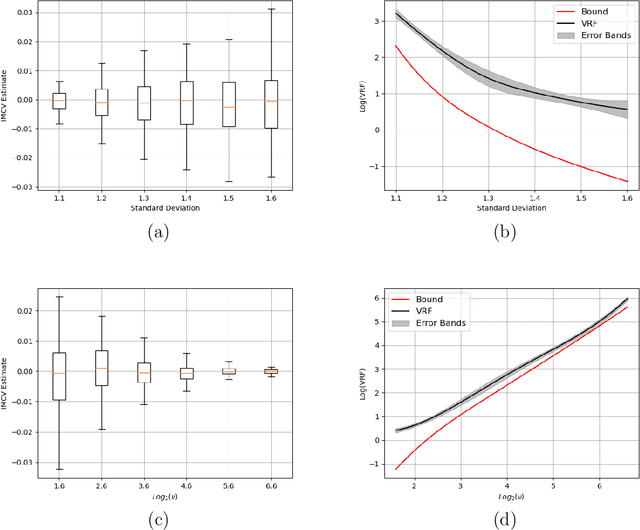
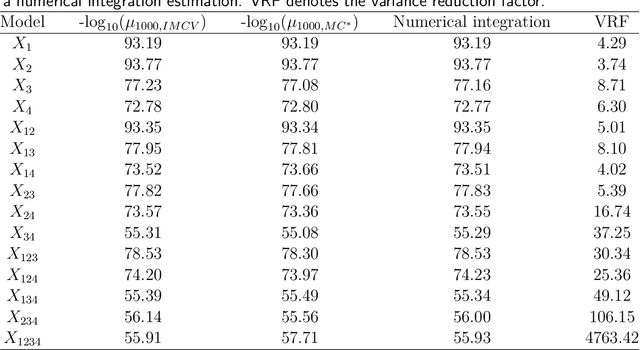
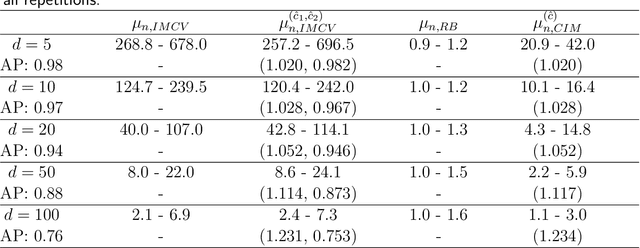
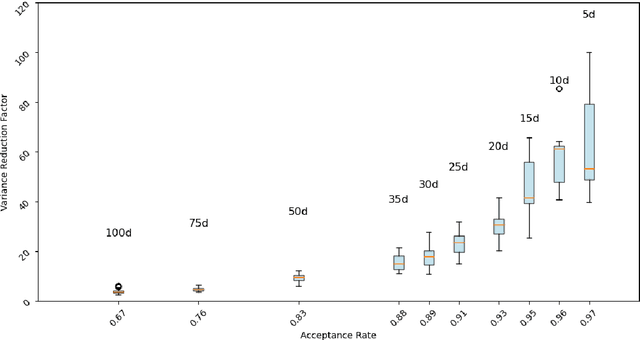
Assume that we would like to estimate the expected value of a function $F$ with respect to a density $\pi$. We prove that if $\pi$ is close enough under KL divergence to another density $q$, an independent Metropolis sampler estimator that obtains samples from $\pi$ with proposal density $q$, enriched with a variance reduction computational strategy based on control variates, achieves smaller asymptotic variance than that of the crude Monte Carlo estimator. The control variates construction requires no extra computational effort but assumes that the expected value of $F$ under $q$ is analytically available. We illustrate this result by calculating the marginal likelihood in a linear regression model with prior-likelihood conflict and a non-conjugate prior. Furthermore, we propose an adaptive independent Metropolis algorithm that adapts the proposal density such that its KL divergence with the target is being reduced. We demonstrate its applicability in a Bayesian logistic and Gaussian process regression problems and we rigorously justify our asymptotic arguments under easily verifiable and essentially minimal conditions.
Near-Lossless Acceleration of Long Context LLM Inference with Adaptive Structured Sparse Attention
Jun 17, 2024Large language models (LLMs) now support extremely long context windows, but the quadratic complexity of vanilla attention results in significantly long Time-to-First-Token (TTFT) latency. Existing approaches to address this complexity require additional pretraining or finetuning, and often sacrifice model accuracy. In this paper, we first provide both theoretical and empirical foundations for near-lossless sparse attention. We find dynamically capturing head-specific sparse patterns at runtime with low overhead is crucial. To address this, we propose SampleAttention, an adaptive structured and near-lossless sparse attention. Leveraging observed significant sparse patterns, SampleAttention attends to a fixed percentage of adjacent tokens to capture local window patterns, and employs a two-stage query-guided key-value filtering approach, which adaptively select a minimum set of key-values with low overhead, to capture column stripe patterns. Comprehensive evaluations show that SampleAttention can seamlessly replace vanilla attention in off-the-shelf LLMs with nearly no accuracy loss, and reduces TTFT by up to $2.42\times$ compared with FlashAttention.