 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Multimodal Large Language Models on Cognitive Biases in Chinese Short-Video Misinformation
Jan 10, 2026Short-video platforms have become major channels for misinformation, where deceptive claims frequently leverage visual experiments and social cues. While Multimodal Large Language Models (MLLMs) have demonstrated impressive reasoning capabilities, their robustness against misinformation entangled with cognitive biases remains under-explored. In this paper, we introduce a comprehensive evaluation framework using a high-quality, manually annotated dataset of 200 short videos spanning four health domains. This dataset provides fine-grained annotations for three deceptive patterns, experimental errors, logical fallacies, and fabricated claims, each verified by evidence such as national standards and academic literature. We evaluate eight frontier MLLMs across five modality settings. Experimental results demonstrate that Gemini-2.5-Pro achieves the highest performance in the multimodal setting with a belief score of 71.5/100, while o3 performs the worst at 35.2. Furthermore, we investigate social cues that induce false beliefs in videos and find that models are susceptible to biases like authoritative channel IDs.
Extendable Long-Horizon Planning via Hierarchical Multiscale Diffusion
Mar 25, 2025



This paper tackles a novel problem, extendable long-horizon planning-enabling agents to plan trajectories longer than those in training data without compounding errors. To tackle this, we propose the Hierarchical Multiscale Diffuser (HM-Diffuser) and Progressive Trajectory Extension (PTE), an augmentation method that iteratively generates longer trajectories by stitching shorter ones. HM-Diffuser trains on these extended trajectories using a hierarchical structure, efficiently handling tasks across multiple temporal scales. Additionally, we introduce Adaptive Plan Pondering and the Recursive HM-Diffuser, which consolidate hierarchical layers into a single model to process temporal scales recursively. Experimental results demonstrate the effectiveness of our approach, advancing diffusion-based planners for scalable long-horizon planning.
Signage-Aware Exploration in Open World using Venue Maps
Oct 14, 2024
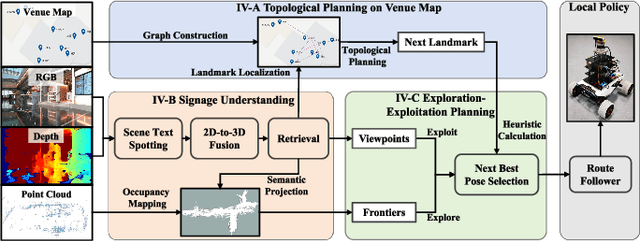
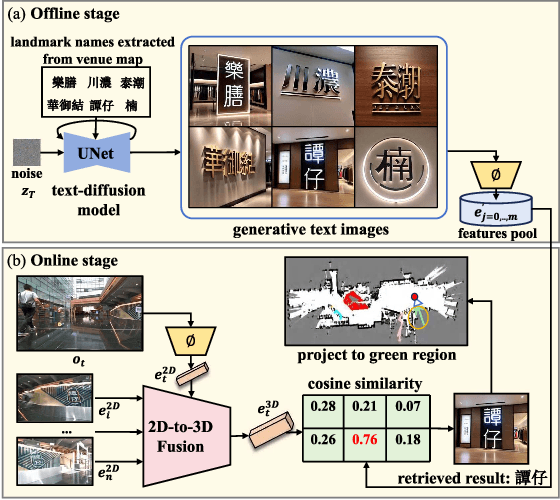
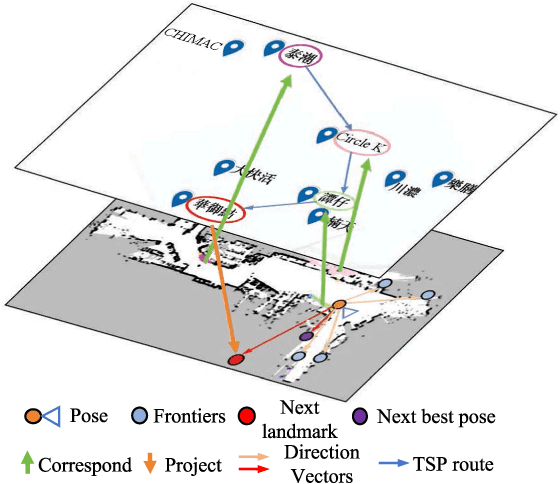
Current exploration methods struggle to search for shops in unknown open-world environments due to a lack of prior knowledge and text recognition capabilities. Venue maps offer valuable information that can aid exploration planning by correlating scene signage with map data. However, the arbitrary shapes and styles of the text on signage, along with multi-view inconsistencies, pose significant challenges for accurate recognition by robots. Additionally, the discrepancies between real-world environments and venue maps hinder the incorporation of text information into planners. This paper introduces a novel signage-aware exploration system to address these challenges, enabling the robot to utilize venue maps effectively. We propose a signage understanding method that accurately detects and recognizes the text on signage using a diffusion-based text instance retrieval method combined with a 2D-to-3D semantic fusion strategy. Furthermore, we design a venue map-guided exploration-exploitation planner that balances exploration in unknown regions using a directional heuristic derived from venue maps with exploitation to get close and adjust orientation for better recognition. Experiments in large-scale shopping malls demonstrate our method's superior signage recognition accuracy and coverage efficiency, outperforming state-of-the-art scene text spotting methods and traditional exploration methods.
LeRF: Learning Resampling Function for Adaptive and Efficient Image Interpolation
Jul 13, 2024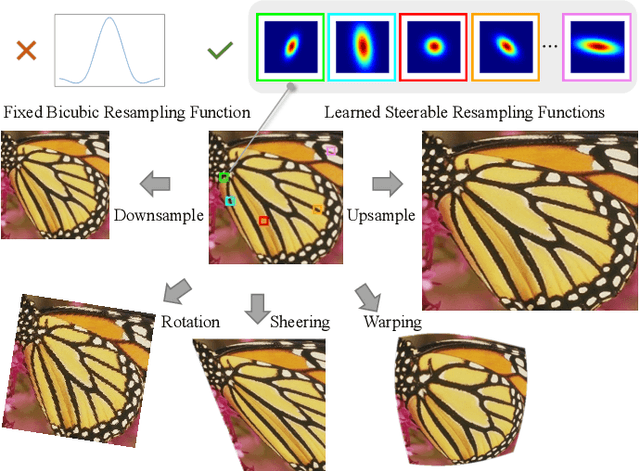

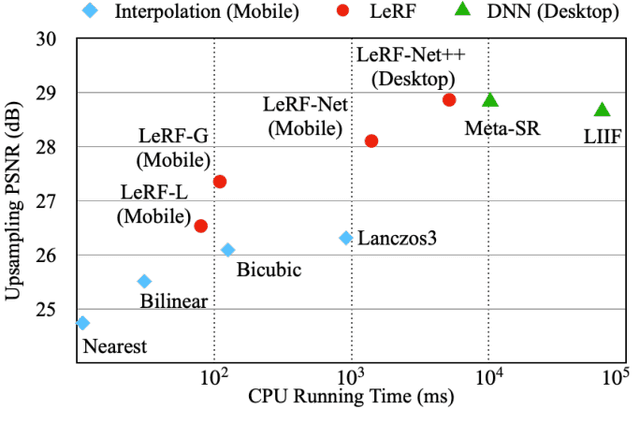
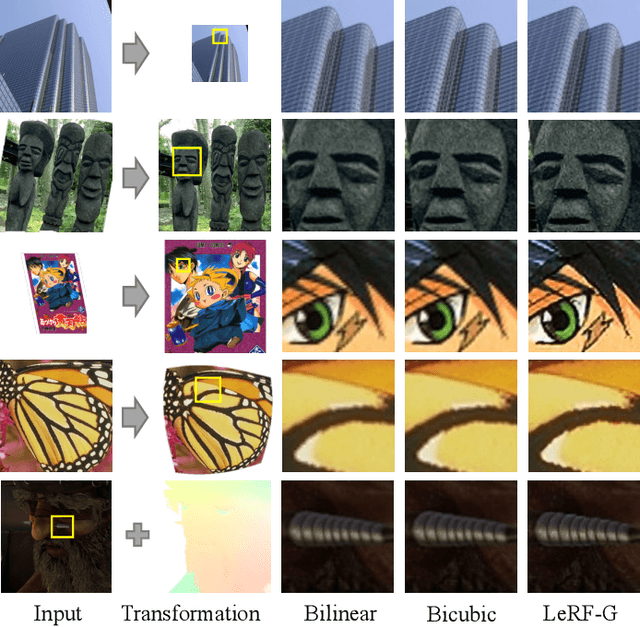
Image resampling is a basic technique that is widely employed in daily applications, such as camera photo editing. Recent deep neural networks (DNNs) have made impressive progress in performance by introducing learned data priors. Still, these methods are not the perfect substitute for interpolation, due to the drawbacks in efficiency and versatility. In this work, we propose a novel method of Learning Resampling Function (termed LeRF), which takes advantage of both the structural priors learned by DNNs and the locally continuous assumption of interpolation. Specifically, LeRF assigns spatially varying resampling functions to input image pixels and learns to predict the hyper-parameters that determine the shapes of these resampling functions with a neural network. Based on the formulation of LeRF, we develop a family of models, including both efficiency-orientated and performance-orientated ones. To achieve interpolation-level efficiency, we adopt look-up tables (LUTs) to accelerate the inference of the learned neural network. Furthermore, we design a directional ensemble strategy and edge-sensitive indexing patterns to better capture local structures. On the other hand, to obtain DNN-level performance, we propose an extension of LeRF to enable it in cooperation with pre-trained upsampling models for cascaded resampling. Extensive experiments show that the efficiency-orientated version of LeRF runs as fast as interpolation, generalizes well to arbitrary transformations, and outperforms interpolation significantly, e.g., up to 3dB PSNR gain over Bicubic for x2 upsampling on Manga109. Besides, the performance-orientated version of LeRF reaches comparable performance with existing DNNs at much higher efficiency, e.g., less than 25% running time on a desktop GPU.
SampleAttention: Near-Lossless Acceleration of Long Context LLM Inference with Adaptive Structured Sparse Attention
Jun 28, 2024Large language models (LLMs) now support extremely long context windows, but the quadratic complexity of vanilla attention results in significantly long Time-to-First-Token (TTFT) latency. Existing approaches to address this complexity require additional pretraining or finetuning, and often sacrifice model accuracy. In this paper, we first provide both theoretical and empirical foundations for near-lossless sparse attention. We find dynamically capturing head-specific sparse patterns at runtime with low overhead is crucial. To address this, we propose SampleAttention, an adaptive structured and near-lossless sparse attention. Leveraging observed significant sparse patterns, SampleAttention attends to a fixed percentage of adjacent tokens to capture local window patterns, and employs a two-stage query-guided key-value filtering approach, which adaptively select a minimum set of key-values with low overhead, to capture column stripe patterns. Comprehensive evaluations show that SampleAttention can seamlessly replace vanilla attention in off-the-shelf LLMs with nearly no accuracy loss, and reduces TTFT by up to $2.42\times$ compared with FlashAttention.
Near-Lossless Acceleration of Long Context LLM Inference with Adaptive Structured Sparse Attention
Jun 17, 2024Large language models (LLMs) now support extremely long context windows, but the quadratic complexity of vanilla attention results in significantly long Time-to-First-Token (TTFT) latency. Existing approaches to address this complexity require additional pretraining or finetuning, and often sacrifice model accuracy. In this paper, we first provide both theoretical and empirical foundations for near-lossless sparse attention. We find dynamically capturing head-specific sparse patterns at runtime with low overhead is crucial. To address this, we propose SampleAttention, an adaptive structured and near-lossless sparse attention. Leveraging observed significant sparse patterns, SampleAttention attends to a fixed percentage of adjacent tokens to capture local window patterns, and employs a two-stage query-guided key-value filtering approach, which adaptively select a minimum set of key-values with low overhead, to capture column stripe patterns. Comprehensive evaluations show that SampleAttention can seamlessly replace vanilla attention in off-the-shelf LLMs with nearly no accuracy loss, and reduces TTFT by up to $2.42\times$ compared with FlashAttention.
PlanDQ: Hierarchical Plan Orchestration via D-Conductor and Q-Performer
Jun 10, 2024
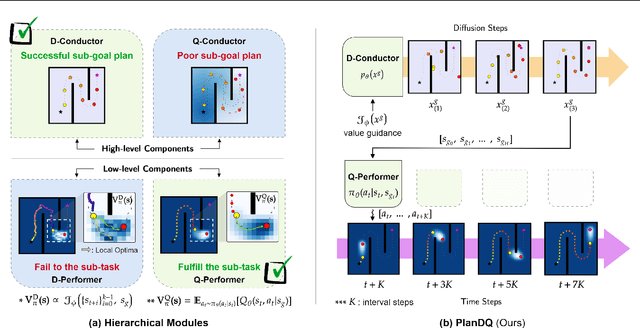
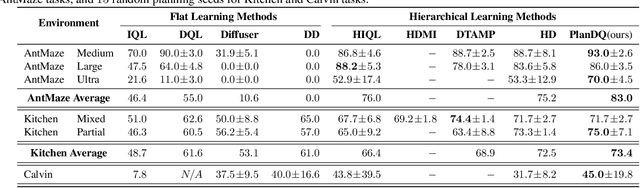
Despite the recent advancements in offline RL, no unified algorithm could achieve superior performance across a broad range of tasks. Offline \textit{value function learning}, in particular, struggles with sparse-reward, long-horizon tasks due to the difficulty of solving credit assignment and extrapolation errors that accumulates as the horizon of the task grows.~On the other hand, models that can perform well in long-horizon tasks are designed specifically for goal-conditioned tasks, which commonly perform worse than value function learning methods on short-horizon, dense-reward scenarios. To bridge this gap, we propose a hierarchical planner designed for offline RL called PlanDQ. PlanDQ incorporates a diffusion-based planner at the high level, named D-Conductor, which guides the low-level policy through sub-goals. At the low level, we used a Q-learning based approach called the Q-Performer to accomplish these sub-goals. Our experimental results suggest that PlanDQ can achieve superior or competitive performance on D4RL continuous control benchmark tasks as well as AntMaze, Kitchen, and Calvin as long-horizon tasks.
SCALE: Self-Correcting Visual Navigation for Mobile Robots via Anti-Novelty Estimation
Apr 16, 2024Although visual navigation has been extensively studied using deep reinforcement learning, online learning for real-world robots remains a challenging task. Recent work directly learned from offline dataset to achieve broader generalization in the real-world tasks, which, however, faces the out-of-distribution (OOD) issue and potential robot localization failures in a given map for unseen observation. This significantly drops the success rates and even induces collision. In this paper, we present a self-correcting visual navigation method, SCALE, that can autonomously prevent the robot from the OOD situations without human intervention. Specifically, we develop an image-goal conditioned offline reinforcement learning method based on implicit Q-learning (IQL). When facing OOD observation, our novel localization recovery method generates the potential future trajectories by learning from the navigation affordance, and estimates the future novelty via random network distillation (RND). A tailored cost function searches for the candidates with the least novelty that can lead the robot to the familiar places. We collect offline data and conduct evaluation experiments in three real-world urban scenarios. Experiment results show that SCALE outperforms the previous state-of-the-art methods for open-world navigation with a unique capability of localization recovery, significantly reducing the need for human intervention. Code is available at https://github.com/KubeEdge4Robotics/ScaleNav.
Simple Hierarchical Planning with Diffusion
Jan 05, 2024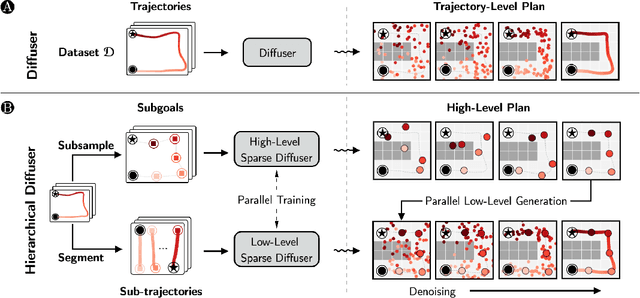
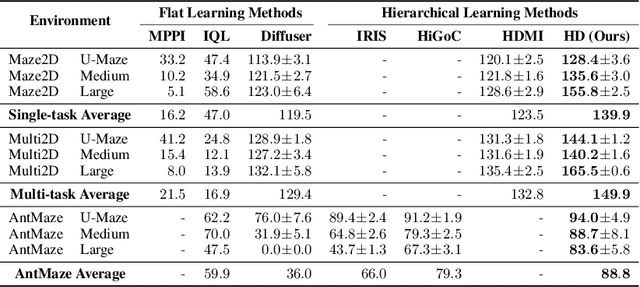
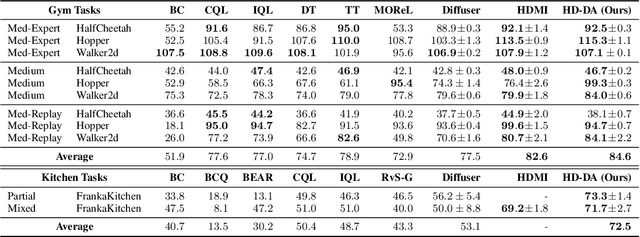
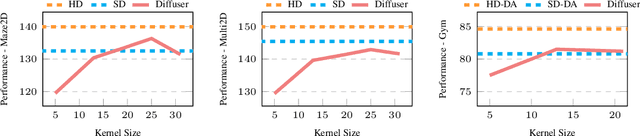
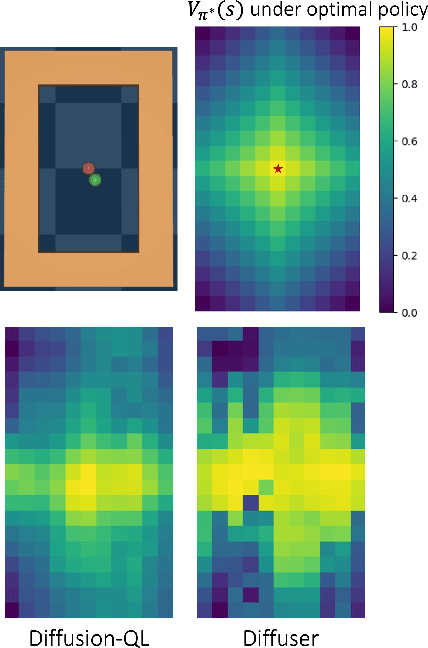
Diffusion-based generative methods have proven effective in modeling trajectories with offline datasets. However, they often face computational challenges and can falter in generalization, especially in capturing temporal abstractions for long-horizon tasks. To overcome this, we introduce the Hierarchical Diffuser, a simple, fast, yet surprisingly effective planning method combining the advantages of hierarchical and diffusion-based planning. Our model adopts a "jumpy" planning strategy at the higher level, which allows it to have a larger receptive field but at a lower computational cost -- a crucial factor for diffusion-based planning methods, as we have empirically verified. Additionally, the jumpy sub-goals guide our low-level planner, facilitating a fine-tuning stage and further improving our approach's effectiveness. We conducted empirical evaluations on standard offline reinforcement learning benchmarks, demonstrating our method's superior performance and efficiency in terms of training and planning speed compared to the non-hierarchical Diffuser as well as other hierarchical planning methods. Moreover, we explore our model's generalization capability, particularly on how our method improves generalization capabilities on compositional out-of-distribution tasks.
Learning Exhaustive Correlation for Spectral Super-Resolution: Where Unified Spatial-Spectral Attention Meets Mutual Linear Dependence
Dec 20, 2023Spectral super-resolution from the easily obtainable RGB image to hyperspectral image (HSI) has drawn increasing interest in the field of computational photography. The crucial aspect of spectral super-resolution lies in exploiting the correlation within HSIs. However, two types of bottlenecks in existing Transformers limit performance improvement and practical applications. First, existing Transformers often separately emphasize either spatial-wise or spectral-wise correlation, disrupting the 3D features of HSI and hindering the exploitation of unified spatial-spectral correlation. Second, the existing self-attention mechanism learns the correlation between pairs of tokens and captures the full-rank correlation matrix, leading to its inability to establish mutual linear dependence among multiple tokens. To address these issues, we propose a novel Exhaustive Correlation Transformer (ECT) for spectral super-resolution. First, we propose a Spectral-wise Discontinuous 3D (SD3D) splitting strategy, which models unified spatial-spectral correlation by simultaneously utilizing spatial-wise continuous splitting and spectral-wise discontinuous splitting. Second, we propose a Dynamic Low-Rank Mapping (DLRM) model, which captures mutual linear dependence among multiple tokens through a dynamically calculated low-rank dependence map. By integrating unified spatial-spectral attention with mutual linear dependence, our ECT can establish exhaustive correlation within HSI. The experimental results on both simulated and real data indicate that our method achieves state-of-the-art performance. Codes and pretrained models will be available later.