 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMxMoE: Mixed-precision Quantization for MoE with Accuracy and Performance Co-Design
May 09, 2025



Mixture-of-Experts (MoE) models face deployment challenges due to their large parameter counts and computational demands. We explore quantization for MoE models and highlight two key insights: 1) linear blocks exhibit varying quantization sensitivity, and 2) divergent expert activation frequencies create heterogeneous computational characteristics. Based on these observations, we introduce MxMoE, a mixed-precision optimization framework for MoE models that considers both algorithmic and system perspectives. MxMoE navigates the design space defined by parameter sensitivity, expert activation dynamics, and hardware resources to derive efficient mixed-precision configurations. Additionally, MxMoE automatically generates optimized mixed-precision GroupGEMM kernels, enabling parallel execution of GEMMs with different precisions. Evaluations show that MxMoE outperforms existing methods, achieving 2.4 lower Wikitext-2 perplexity than GPTQ at 2.25-bit and delivering up to 3.4x speedup over full precision, as well as up to 29.4% speedup over uniform quantization at equivalent accuracy with 5-bit weight-activation quantization. Our code is available at https://github.com/cat538/MxMoE.
SampleAttention: Near-Lossless Acceleration of Long Context LLM Inference with Adaptive Structured Sparse Attention
Jun 28, 2024Large language models (LLMs) now support extremely long context windows, but the quadratic complexity of vanilla attention results in significantly long Time-to-First-Token (TTFT) latency. Existing approaches to address this complexity require additional pretraining or finetuning, and often sacrifice model accuracy. In this paper, we first provide both theoretical and empirical foundations for near-lossless sparse attention. We find dynamically capturing head-specific sparse patterns at runtime with low overhead is crucial. To address this, we propose SampleAttention, an adaptive structured and near-lossless sparse attention. Leveraging observed significant sparse patterns, SampleAttention attends to a fixed percentage of adjacent tokens to capture local window patterns, and employs a two-stage query-guided key-value filtering approach, which adaptively select a minimum set of key-values with low overhead, to capture column stripe patterns. Comprehensive evaluations show that SampleAttention can seamlessly replace vanilla attention in off-the-shelf LLMs with nearly no accuracy loss, and reduces TTFT by up to $2.42\times$ compared with FlashAttention.
Near-Lossless Acceleration of Long Context LLM Inference with Adaptive Structured Sparse Attention
Jun 17, 2024Large language models (LLMs) now support extremely long context windows, but the quadratic complexity of vanilla attention results in significantly long Time-to-First-Token (TTFT) latency. Existing approaches to address this complexity require additional pretraining or finetuning, and often sacrifice model accuracy. In this paper, we first provide both theoretical and empirical foundations for near-lossless sparse attention. We find dynamically capturing head-specific sparse patterns at runtime with low overhead is crucial. To address this, we propose SampleAttention, an adaptive structured and near-lossless sparse attention. Leveraging observed significant sparse patterns, SampleAttention attends to a fixed percentage of adjacent tokens to capture local window patterns, and employs a two-stage query-guided key-value filtering approach, which adaptively select a minimum set of key-values with low overhead, to capture column stripe patterns. Comprehensive evaluations show that SampleAttention can seamlessly replace vanilla attention in off-the-shelf LLMs with nearly no accuracy loss, and reduces TTFT by up to $2.42\times$ compared with FlashAttention.
SKVQ: Sliding-window Key and Value Cache Quantization for Large Language Models
May 10, 2024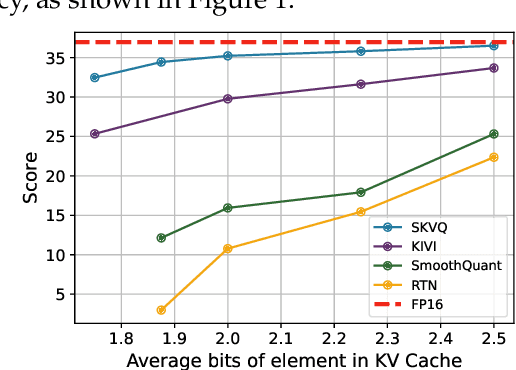
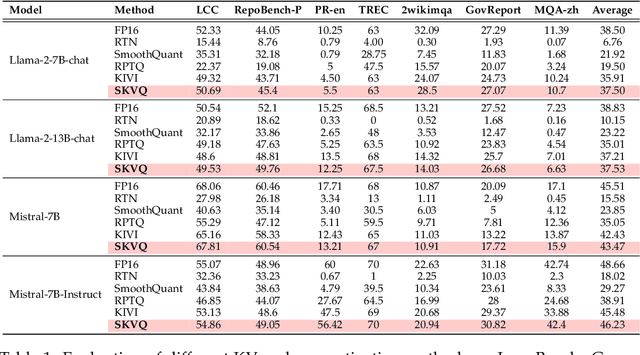
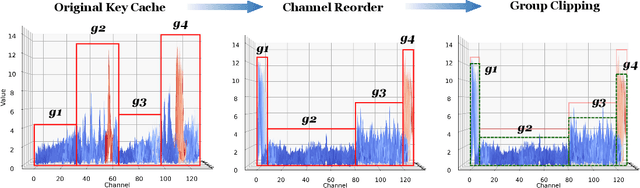
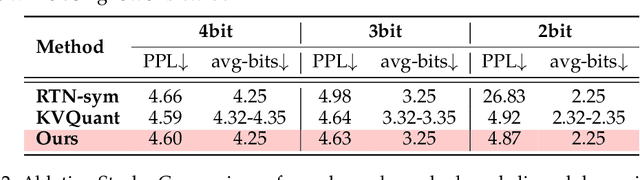
Large language models (LLMs) can now handle longer sequences of tokens, enabling complex tasks like book understanding and generating lengthy novels. However, the key-value (KV) cache required for LLMs consumes substantial memory as context length increasing, becoming the bottleneck for deployment. In this paper, we present a strategy called SKVQ, which stands for sliding-window KV cache quantization, to address the issue of extremely low bitwidth KV cache quantization. To achieve this, SKVQ rearranges the channels of the KV cache in order to improve the similarity of channels in quantization groups, and applies clipped dynamic quantization at the group level. Additionally, SKVQ ensures that the most recent window tokens in the KV cache are preserved with high precision. This helps maintain the accuracy of a small but important portion of the KV cache.SKVQ achieves high compression ratios while maintaining accuracy. Our evaluation on LLMs demonstrates that SKVQ surpasses previous quantization approaches, allowing for quantization of the KV cache to 2-bit keys and 1.5-bit values with minimal loss of accuracy. With SKVQ, it is possible to process context lengths of up to 1M on an 80GB memory GPU for a 7b model and up to 7 times faster decoding.
SpotServe: Serving Generative Large Language Models on Preemptible Instances
Nov 27, 2023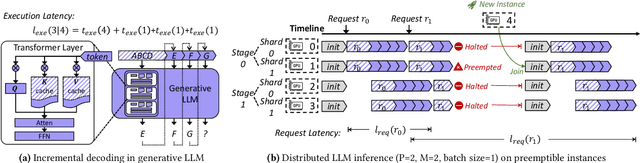

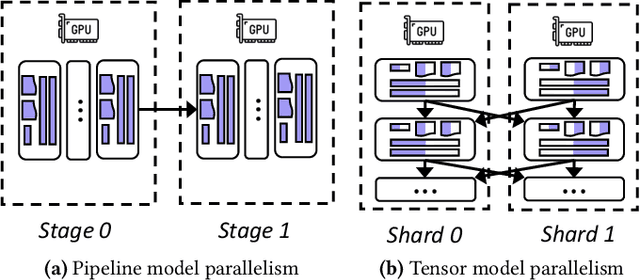
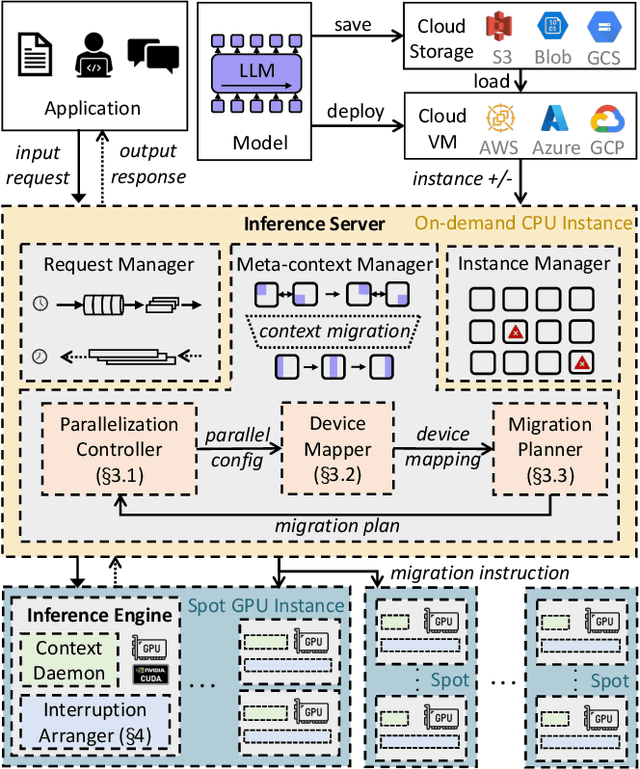
The high computational and memory requirements of generative large language models (LLMs) make it challenging to serve them cheaply. This paper aims to reduce the monetary cost for serving LLMs by leveraging preemptible GPU instances on modern clouds, which offer accesses to spare GPUs at a much cheaper price than regular instances but may be preempted by the cloud at any time. Serving LLMs on preemptible instances requires addressing challenges induced by frequent instance preemptions and the necessity of migrating instances to handle these preemptions. This paper presents SpotServe, the first distributed LLM serving system on preemptible instances. Several key techniques in SpotServe realize fast and reliable serving of generative LLMs on cheap preemptible instances. First, SpotServe dynamically adapts the LLM parallelization configuration for dynamic instance availability and fluctuating workload, while balancing the trade-off among the overall throughput, inference latency and monetary costs. Second, to minimize the cost of migrating instances for dynamic reparallelization, the task of migrating instances is formulated as a bipartite graph matching problem, which uses the Kuhn-Munkres algorithm to identify an optimal migration plan that minimizes communications. Finally, to take advantage of the grace period offered by modern clouds, we introduce stateful inference recovery, a new inference mechanism that commits inference progress at a much finer granularity and allows SpotServe to cheaply resume inference upon preemption. We evaluate on real spot instance preemption traces and various popular LLMs and show that SpotServe can reduce the P99 tail latency by 2.4 - 9.1x compared with the best existing LLM serving systems. We also show that SpotServe can leverage the price advantage of preemptive instances, saving 54% monetary cost compared with only using on-demand instances.