 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge6Bit-Diffusion: Inference-Time Mixed-Precision Quantization for Video Diffusion Models
Mar 19, 2026Diffusion transformers have demonstrated remarkable capabilities in generating videos. However, their practical deployment is severely constrained by high memory usage and computational cost. Post-Training Quantization provides a practical way to reduce memory usage and boost computation speed. Existing quantization methods typically apply a static bit-width allocation, overlooking the quantization difficulty of activations across diffusion timesteps, leading to a suboptimal trade-off between efficiency and quality. In this paper, we propose a inference time NVFP4/INT8 Mixed-Precision Quantization framework. We find a strong linear correlation between a block's input-output difference and the quantization sensitivity of its internal linear layers. Based on this insight, we design a lightweight predictor that dynamically allocates NVFP4 to temporally stable layers to maximize memory compression, while selectively preserving INT8 for volatile layers to ensure robustness. This adaptive precision strategy enables aggressive quantization without compromising generation quality. Beside this, we observe that the residual between the input and output of a Transformer block exhibits high temporal consistency across timesteps. Leveraging this temporal redundancy, we introduce Temporal Delta Cache (TDC) to skip computations for these invariant blocks, further reducing the computational cost. Extensive experiments demonstrate that our method achieves 1.92$\times$ end-to-end acceleration and 3.32$\times$ memory reduction, setting a new baseline for efficient inference in Video DiTs.
MxMoE: Mixed-precision Quantization for MoE with Accuracy and Performance Co-Design
May 09, 2025



Mixture-of-Experts (MoE) models face deployment challenges due to their large parameter counts and computational demands. We explore quantization for MoE models and highlight two key insights: 1) linear blocks exhibit varying quantization sensitivity, and 2) divergent expert activation frequencies create heterogeneous computational characteristics. Based on these observations, we introduce MxMoE, a mixed-precision optimization framework for MoE models that considers both algorithmic and system perspectives. MxMoE navigates the design space defined by parameter sensitivity, expert activation dynamics, and hardware resources to derive efficient mixed-precision configurations. Additionally, MxMoE automatically generates optimized mixed-precision GroupGEMM kernels, enabling parallel execution of GEMMs with different precisions. Evaluations show that MxMoE outperforms existing methods, achieving 2.4 lower Wikitext-2 perplexity than GPTQ at 2.25-bit and delivering up to 3.4x speedup over full precision, as well as up to 29.4% speedup over uniform quantization at equivalent accuracy with 5-bit weight-activation quantization. Our code is available at https://github.com/cat538/MxMoE.
SKVQ: Sliding-window Key and Value Cache Quantization for Large Language Models
May 10, 2024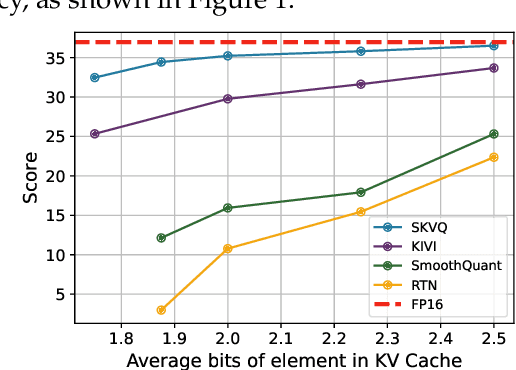
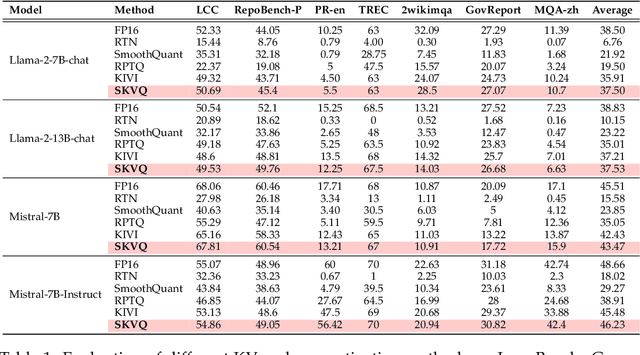
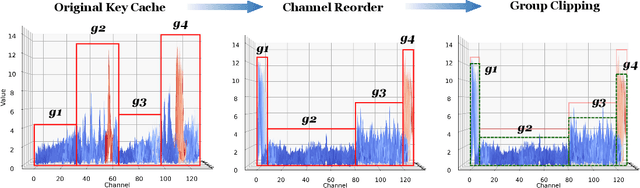
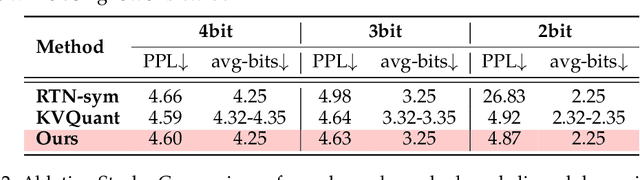
Large language models (LLMs) can now handle longer sequences of tokens, enabling complex tasks like book understanding and generating lengthy novels. However, the key-value (KV) cache required for LLMs consumes substantial memory as context length increasing, becoming the bottleneck for deployment. In this paper, we present a strategy called SKVQ, which stands for sliding-window KV cache quantization, to address the issue of extremely low bitwidth KV cache quantization. To achieve this, SKVQ rearranges the channels of the KV cache in order to improve the similarity of channels in quantization groups, and applies clipped dynamic quantization at the group level. Additionally, SKVQ ensures that the most recent window tokens in the KV cache are preserved with high precision. This helps maintain the accuracy of a small but important portion of the KV cache.SKVQ achieves high compression ratios while maintaining accuracy. Our evaluation on LLMs demonstrates that SKVQ surpasses previous quantization approaches, allowing for quantization of the KV cache to 2-bit keys and 1.5-bit values with minimal loss of accuracy. With SKVQ, it is possible to process context lengths of up to 1M on an 80GB memory GPU for a 7b model and up to 7 times faster decoding.
WKVQuant: Quantizing Weight and Key/Value Cache for Large Language Models Gains More
Feb 20, 2024Large Language Models (LLMs) face significant deployment challenges due to their substantial memory requirements and the computational demands of auto-regressive text generation process. This paper addresses these challenges by focusing on the quantization of LLMs, a technique that reduces memory consumption by converting model parameters and activations into low-bit integers. We critically analyze the existing quantization approaches, identifying their limitations in balancing the accuracy and efficiency of the quantized LLMs. To advance beyond these limitations, we propose WKVQuant, a PTQ framework especially designed for quantizing weights and the key/value (KV) cache of LLMs. Specifically, we incorporates past-only quantization to improve the computation of attention. Additionally, we introduce two-dimensional quantization strategy to handle the distribution of KV cache, along with a cross-block reconstruction regularization for parameter optimization. Experiments show that WKVQuant achieves almost comparable memory savings to weight-activation quantization, while also approaching the performance of weight-only quantization.