 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClover: Regressive Lightweight Speculative Decoding with Sequential Knowledge
May 01, 2024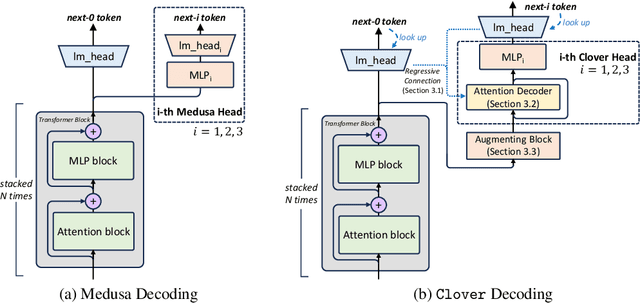
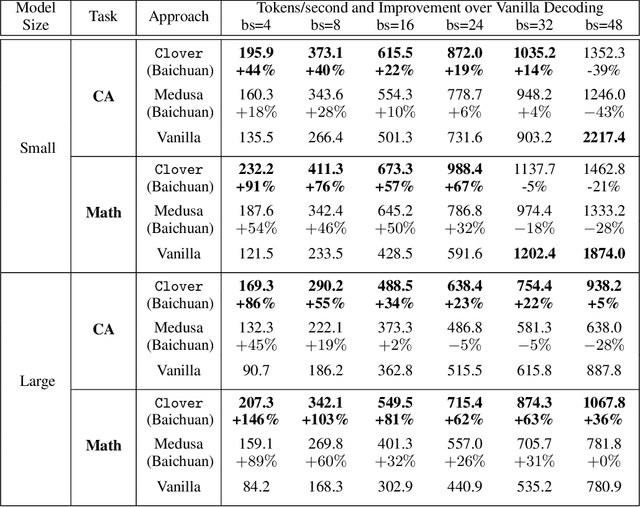
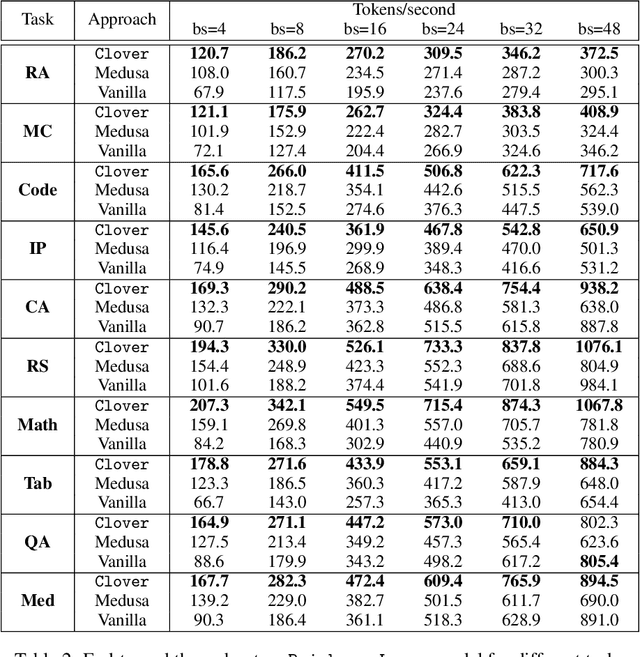
Large language models (LLMs) suffer from low efficiency as the mismatch between the requirement of auto-regressive decoding and the design of most contemporary GPUs. Specifically, billions to trillions of parameters must be loaded to the GPU cache through its limited memory bandwidth for computation, but only a small batch of tokens is actually computed. Consequently, the GPU spends most of its time on memory transfer instead of computation. Recently, parallel decoding, a type of speculative decoding algorithms, is becoming more popular and has demonstrated impressive efficiency improvement in generation. It introduces extra decoding heads to large models, enabling them to predict multiple subsequent tokens simultaneously and verify these candidate continuations in a single decoding step. However, this approach deviates from the training objective of next token prediction used during pre-training, resulting in a low hit rate for candidate tokens. In this paper, we propose a new speculative decoding algorithm, Clover, which integrates sequential knowledge into the parallel decoding process. This enhancement improves the hit rate of speculators and thus boosts the overall efficiency. Clover transmits the sequential knowledge from pre-speculated tokens via the Regressive Connection, then employs an Attention Decoder to integrate these speculated tokens. Additionally, Clover incorporates an Augmenting Block that modifies the hidden states to better align with the purpose of speculative generation rather than next token prediction. The experiment results demonstrate that Clover outperforms the baseline by up to 91% on Baichuan-Small and 146% on Baichuan-Large, respectively, and exceeds the performance of the previously top-performing method, Medusa, by up to 37% on Baichuan-Small and 57% on Baichuan-Large, respectively.
SpotServe: Serving Generative Large Language Models on Preemptible Instances
Nov 27, 2023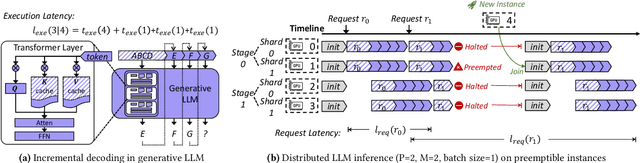

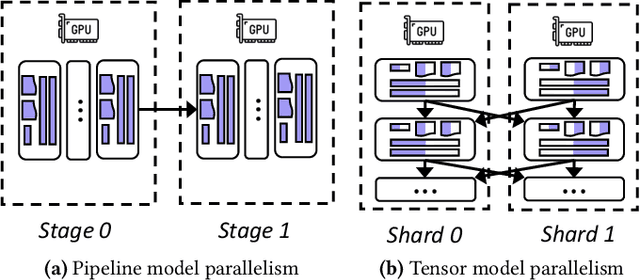
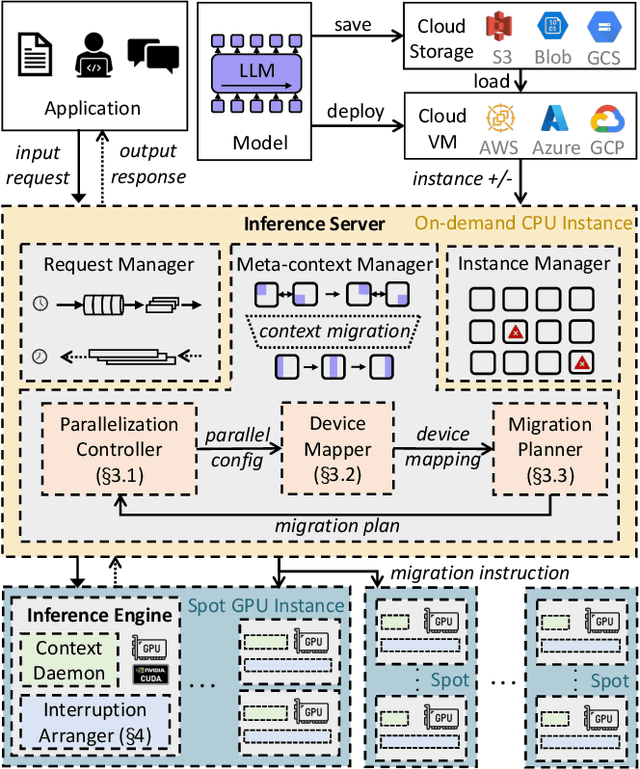
The high computational and memory requirements of generative large language models (LLMs) make it challenging to serve them cheaply. This paper aims to reduce the monetary cost for serving LLMs by leveraging preemptible GPU instances on modern clouds, which offer accesses to spare GPUs at a much cheaper price than regular instances but may be preempted by the cloud at any time. Serving LLMs on preemptible instances requires addressing challenges induced by frequent instance preemptions and the necessity of migrating instances to handle these preemptions. This paper presents SpotServe, the first distributed LLM serving system on preemptible instances. Several key techniques in SpotServe realize fast and reliable serving of generative LLMs on cheap preemptible instances. First, SpotServe dynamically adapts the LLM parallelization configuration for dynamic instance availability and fluctuating workload, while balancing the trade-off among the overall throughput, inference latency and monetary costs. Second, to minimize the cost of migrating instances for dynamic reparallelization, the task of migrating instances is formulated as a bipartite graph matching problem, which uses the Kuhn-Munkres algorithm to identify an optimal migration plan that minimizes communications. Finally, to take advantage of the grace period offered by modern clouds, we introduce stateful inference recovery, a new inference mechanism that commits inference progress at a much finer granularity and allows SpotServe to cheaply resume inference upon preemption. We evaluate on real spot instance preemption traces and various popular LLMs and show that SpotServe can reduce the P99 tail latency by 2.4 - 9.1x compared with the best existing LLM serving systems. We also show that SpotServe can leverage the price advantage of preemptive instances, saving 54% monetary cost compared with only using on-demand instances.
Galvatron: Efficient Transformer Training over Multiple GPUs Using Automatic Parallelism
Nov 25, 2022



Transformer models have achieved state-of-the-art performance on various domains of applications and gradually becomes the foundations of the advanced large deep learning (DL) models. However, how to train these models over multiple GPUs efficiently is still challenging due to a large number of parallelism choices. Existing DL systems either rely on manual efforts to make distributed training plans or apply parallelism combinations within a very limited search space. In this approach, we propose Galvatron, a new system framework that incorporates multiple popular parallelism dimensions and automatically finds the most efficient hybrid parallelism strategy. To better explore such a rarely huge search space, we 1) involve a decision tree to make decomposition and pruning based on some reasonable intuitions, and then 2) design a dynamic programming search algorithm to generate the optimal plan. Evaluations on four representative Transformer workloads show that Galvatron could perform automatically distributed training with different GPU memory budgets. Among all evluated scenarios, Galvatron always achieves superior system throughput compared to previous work with limited parallelism.