 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLA2: Sparse-Linear Attention with Learnable Routing and QAT
Feb 13, 2026Sparse-Linear Attention (SLA) combines sparse and linear attention to accelerate diffusion models and has shown strong performance in video generation. However, (i) SLA relies on a heuristic split that assigns computations to the sparse or linear branch based on attention-weight magnitude, which can be suboptimal. Additionally, (ii) after formally analyzing the attention error in SLA, we identify a mismatch between SLA and a direct decomposition into sparse and linear attention. We propose SLA2, which introduces (I) a learnable router that dynamically selects whether each attention computation should use sparse or linear attention, (II) a more faithful and direct sparse-linear attention formulation that uses a learnable ratio to combine the sparse and linear attention branches, and (III) a sparse + low-bit attention design, where low-bit attention is introduced via quantization-aware fine-tuning to reduce quantization error. Experiments show that on video diffusion models, SLA2 can achieve 97% attention sparsity and deliver an 18.6x attention speedup while preserving generation quality.
Flash Sparse Attention: An Alternative Efficient Implementation of Native Sparse Attention Kernel
Aug 25, 2025Recent progress in sparse attention mechanisms has demonstrated strong potential for reducing the computational cost of long-context training and inference in large language models (LLMs). Native Sparse Attention (NSA), a state-of-the-art approach, introduces natively trainable, hardware-aligned sparse attention that delivers substantial system-level performance gains while maintaining accuracy comparable to full attention. However, the kernel implementation of NSA relies on a query-grouping strategy that is efficient only with large Grouped Query Attention (GQA) sizes, whereas modern LLMs typically adopt much smaller GQA groups, which limits the applicability of this sparse algorithmic advance. In this work, we propose Flash Sparse Attention (FSA), which includes an alternative kernel design that enables efficient NSA computation across a wide range of popular LLMs with varied smaller GQA group sizes on modern GPUs. Compared to vanilla NSA kernel implementation, our empirical evaluation demonstrates that FSA achieves (i) up to 3.5$\times$ and on average 1.6$\times$ kernel-level latency reduction, (ii) up to 1.25$\times$ and 1.09$\times$ on average end-to-end training speedup on state-of-the-art LLMs, and (iii) up to 1.36$\times$ and 1.11$\times$ on average end-to-end prefill speedup on state-of-the-art LLMs. The source code is open-sourced and publicly available at https://github.com/Relaxed-System-Lab/Flash-Sparse-Attention.
Thinking Short and Right Over Thinking Long: Serving LLM Reasoning Efficiently and Accurately
May 19, 2025Recent advances in test-time scaling suggest that Large Language Models (LLMs) can gain better capabilities by generating Chain-of-Thought reasoning (analogous to human thinking) to respond a given request, and meanwhile exploring more reasoning branches (i.e., generating multiple responses and ensembling them) can improve the final output quality. However, when incorporating the two scaling dimensions, we find that the system efficiency is dampened significantly for two reasons. Firstly, the time cost to generate the final output increases substantially as many reasoning branches would be trapped in the over-thinking dilemma, producing excessively long responses. Secondly, generating multiple reasoning branches for each request increases memory consumption, which is unsuitable for LLM serving since we can only batch a limited number of requests to process simultaneously. To address this, we present SART, a serving framework for efficient and accurate LLM reasoning. The essential idea is to manage the thinking to be short and right, rather than long. For one thing, we devise a redundant sampling with early stopping approach based on empirical observations and theoretic analysis, which increases the likelihood of obtaining short-thinking responses when sampling reasoning branches. For another, we propose to dynamically prune low-quality branches so that only right-thinking branches are maintained, reducing the memory consumption and allowing us to batch more requests. Experimental results demonstrate that SART not only improves the accuracy of LLM reasoning but also enhances the serving efficiency, outperforming existing methods by up to 28.2 times and on average 15.7 times in terms of efficiency when achieving the same level of accuracy.
Improving Automatic Parallel Training via Balanced Memory Workload Optimization
Jul 05, 2023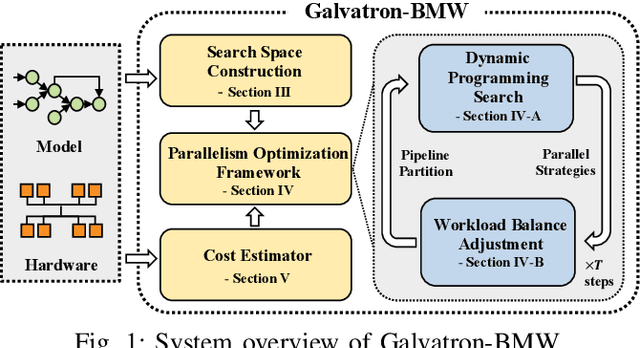
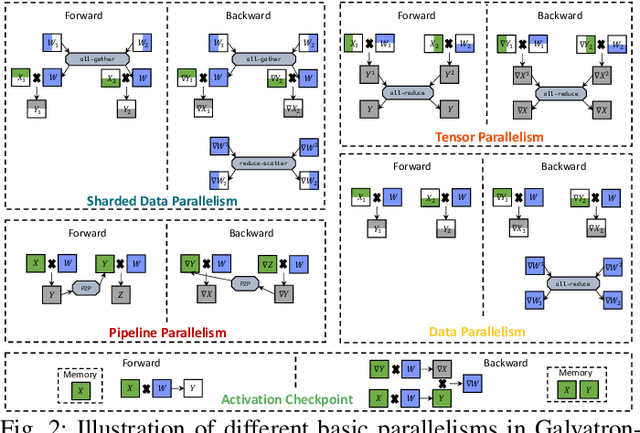
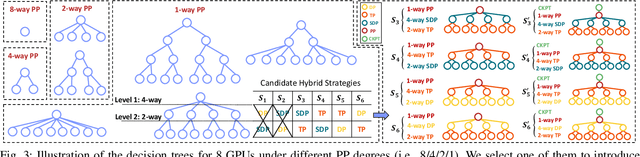
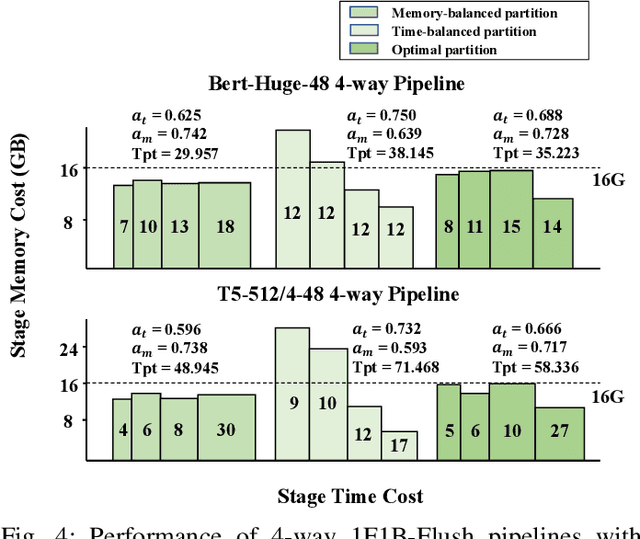
Transformer models have emerged as the leading approach for achieving state-of-the-art performance across various application domains, serving as the foundation for advanced large-scale deep learning (DL) models. However, efficiently training these models across multiple GPUs remains a complex challenge due to the abundance of parallelism options. Existing DL systems either require manual efforts to design distributed training plans or limit parallelism combinations to a constrained search space. In this paper, we present Galvatron-BMW, a novel system framework that integrates multiple prevalent parallelism dimensions and automatically identifies the most efficient hybrid parallelism strategy. To effectively navigate this vast search space, we employ a decision tree approach for decomposition and pruning based on intuitive insights. We further utilize a dynamic programming search algorithm to derive the optimal plan. Moreover, to improve resource utilization and enhance system efficiency, we propose a bi-objective optimization workflow that focuses on workload balance. Our evaluations on different Transformer models demonstrate the capabilities of Galvatron-BMW in automating distributed training under varying GPU memory constraints. Across all tested scenarios, Galvatron-BMW consistently achieves superior system throughput, surpassing previous approaches that rely on limited parallelism strategies.
Galvatron: Efficient Transformer Training over Multiple GPUs Using Automatic Parallelism
Nov 25, 2022



Transformer models have achieved state-of-the-art performance on various domains of applications and gradually becomes the foundations of the advanced large deep learning (DL) models. However, how to train these models over multiple GPUs efficiently is still challenging due to a large number of parallelism choices. Existing DL systems either rely on manual efforts to make distributed training plans or apply parallelism combinations within a very limited search space. In this approach, we propose Galvatron, a new system framework that incorporates multiple popular parallelism dimensions and automatically finds the most efficient hybrid parallelism strategy. To better explore such a rarely huge search space, we 1) involve a decision tree to make decomposition and pruning based on some reasonable intuitions, and then 2) design a dynamic programming search algorithm to generate the optimal plan. Evaluations on four representative Transformer workloads show that Galvatron could perform automatically distributed training with different GPU memory budgets. Among all evluated scenarios, Galvatron always achieves superior system throughput compared to previous work with limited parallelism.