 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Automatic Parallel Training via Balanced Memory Workload Optimization
Paper and Code
Jul 05, 2023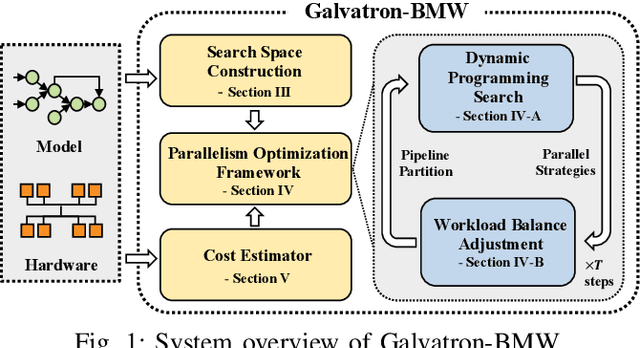
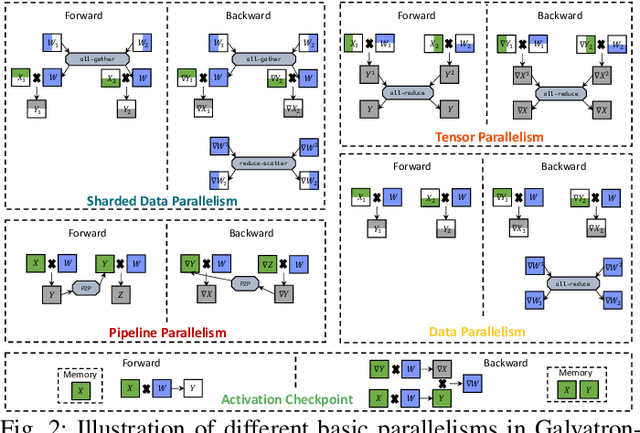
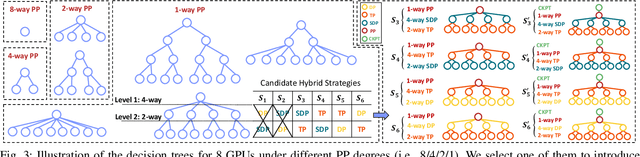
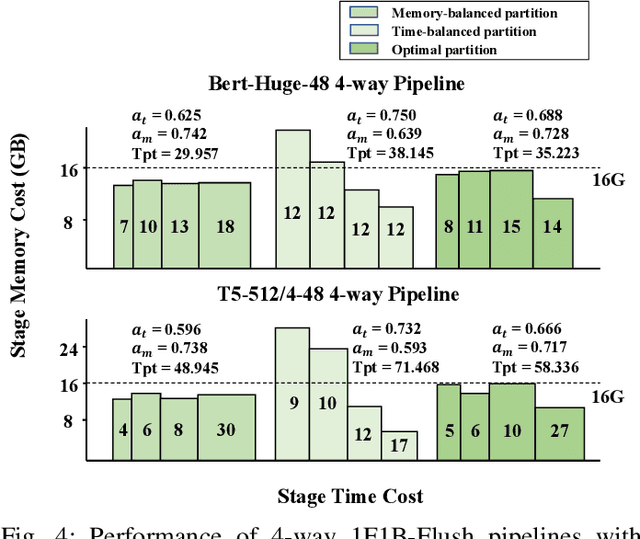
Transformer models have emerged as the leading approach for achieving state-of-the-art performance across various application domains, serving as the foundation for advanced large-scale deep learning (DL) models. However, efficiently training these models across multiple GPUs remains a complex challenge due to the abundance of parallelism options. Existing DL systems either require manual efforts to design distributed training plans or limit parallelism combinations to a constrained search space. In this paper, we present Galvatron-BMW, a novel system framework that integrates multiple prevalent parallelism dimensions and automatically identifies the most efficient hybrid parallelism strategy. To effectively navigate this vast search space, we employ a decision tree approach for decomposition and pruning based on intuitive insights. We further utilize a dynamic programming search algorithm to derive the optimal plan. Moreover, to improve resource utilization and enhance system efficiency, we propose a bi-objective optimization workflow that focuses on workload balance. Our evaluations on different Transformer models demonstrate the capabilities of Galvatron-BMW in automating distributed training under varying GPU memory constraints. Across all tested scenarios, Galvatron-BMW consistently achieves superior system throughput, surpassing previous approaches that rely on limited parallelism strategies.