 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpotServe: Serving Generative Large Language Models on Preemptible Instances
Nov 27, 2023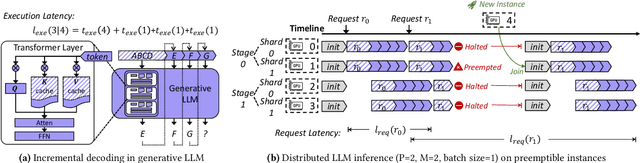

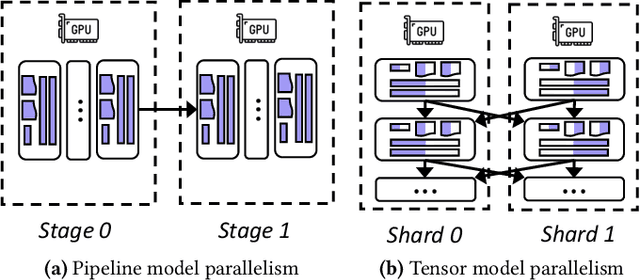
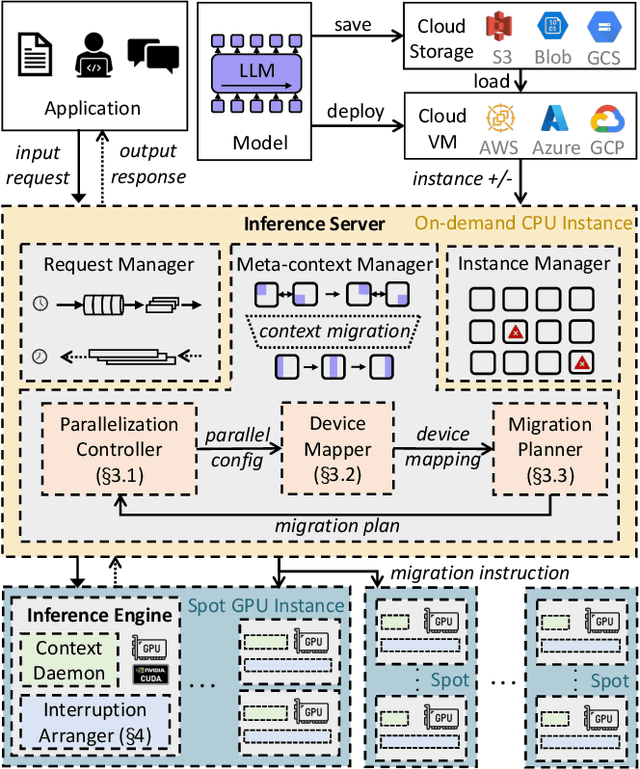
The high computational and memory requirements of generative large language models (LLMs) make it challenging to serve them cheaply. This paper aims to reduce the monetary cost for serving LLMs by leveraging preemptible GPU instances on modern clouds, which offer accesses to spare GPUs at a much cheaper price than regular instances but may be preempted by the cloud at any time. Serving LLMs on preemptible instances requires addressing challenges induced by frequent instance preemptions and the necessity of migrating instances to handle these preemptions. This paper presents SpotServe, the first distributed LLM serving system on preemptible instances. Several key techniques in SpotServe realize fast and reliable serving of generative LLMs on cheap preemptible instances. First, SpotServe dynamically adapts the LLM parallelization configuration for dynamic instance availability and fluctuating workload, while balancing the trade-off among the overall throughput, inference latency and monetary costs. Second, to minimize the cost of migrating instances for dynamic reparallelization, the task of migrating instances is formulated as a bipartite graph matching problem, which uses the Kuhn-Munkres algorithm to identify an optimal migration plan that minimizes communications. Finally, to take advantage of the grace period offered by modern clouds, we introduce stateful inference recovery, a new inference mechanism that commits inference progress at a much finer granularity and allows SpotServe to cheaply resume inference upon preemption. We evaluate on real spot instance preemption traces and various popular LLMs and show that SpotServe can reduce the P99 tail latency by 2.4 - 9.1x compared with the best existing LLM serving systems. We also show that SpotServe can leverage the price advantage of preemptive instances, saving 54% monetary cost compared with only using on-demand instances.