 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCubeComposer: Spatio-Temporal Autoregressive 4K 360° Video Generation from Perspective Video
Mar 04, 2026Generating high-quality 360° panoramic videos from perspective input is one of the crucial applications for virtual reality (VR), whereby high-resolution videos are especially important for immersive experience. Existing methods are constrained by computational limitations of vanilla diffusion models, only supporting $\leq$ 1K resolution native generation and relying on suboptimal post super-resolution to increase resolution. We introduce CubeComposer, a novel spatio-temporal autoregressive diffusion model that natively generates 4K-resolution 360° videos. By decomposing videos into cubemap representations with six faces, CubeComposer autoregressively synthesizes content in a well-planned spatio-temporal order, reducing memory demands while enabling high-resolution output. Specifically, to address challenges in multi-dimensional autoregression, we propose: (1) a spatio-temporal autoregressive strategy that orchestrates 360° video generation across cube faces and time windows for coherent synthesis; (2) a cube face context management mechanism, equipped with a sparse context attention design to improve efficiency; and (3) continuity-aware techniques, including cube-aware positional encoding, padding, and blending to eliminate boundary seams. Extensive experiments on benchmark datasets demonstrate that CubeComposer outperforms state-of-the-art methods in native resolution and visual quality, supporting practical VR application scenarios. Project page: https://lg-li.github.io/project/cubecomposer
ToonComposer: Streamlining Cartoon Production with Generative Post-Keyframing
Aug 14, 2025
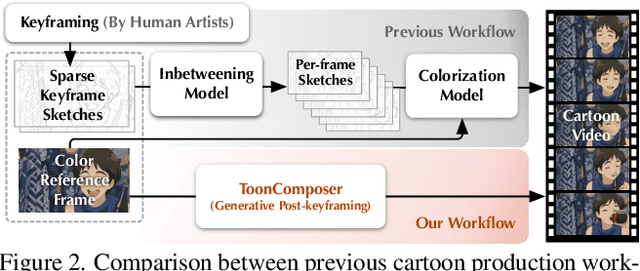
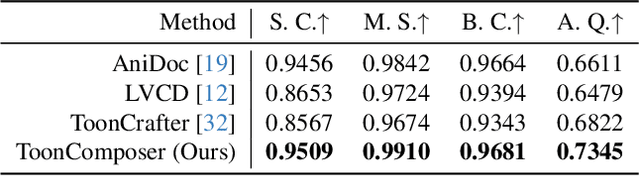
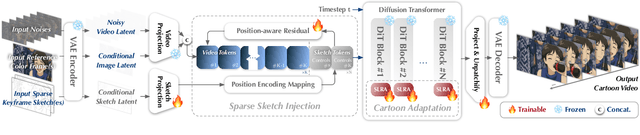
Traditional cartoon and anime production involves keyframing, inbetweening, and colorization stages, which require intensive manual effort. Despite recent advances in AI, existing methods often handle these stages separately, leading to error accumulation and artifacts. For instance, inbetweening approaches struggle with large motions, while colorization methods require dense per-frame sketches. To address this, we introduce ToonComposer, a generative model that unifies inbetweening and colorization into a single post-keyframing stage. ToonComposer employs a sparse sketch injection mechanism to provide precise control using keyframe sketches. Additionally, it uses a cartoon adaptation method with the spatial low-rank adapter to tailor a modern video foundation model to the cartoon domain while keeping its temporal prior intact. Requiring as few as a single sketch and a colored reference frame, ToonComposer excels with sparse inputs, while also supporting multiple sketches at any temporal location for more precise motion control. This dual capability reduces manual workload and improves flexibility, empowering artists in real-world scenarios. To evaluate our model, we further created PKBench, a benchmark featuring human-drawn sketches that simulate real-world use cases. Our evaluation demonstrates that ToonComposer outperforms existing methods in visual quality, motion consistency, and production efficiency, offering a superior and more flexible solution for AI-assisted cartoon production.
IC-Custom: Diverse Image Customization via In-Context Learning
Jul 02, 2025Image customization, a crucial technique for industrial media production, aims to generate content that is consistent with reference images. However, current approaches conventionally separate image customization into position-aware and position-free customization paradigms and lack a universal framework for diverse customization, limiting their applications across various scenarios. To overcome these limitations, we propose IC-Custom, a unified framework that seamlessly integrates position-aware and position-free image customization through in-context learning. IC-Custom concatenates reference images with target images to a polyptych, leveraging DiT's multi-modal attention mechanism for fine-grained token-level interactions. We introduce the In-context Multi-Modal Attention (ICMA) mechanism with learnable task-oriented register tokens and boundary-aware positional embeddings to enable the model to correctly handle different task types and distinguish various inputs in polyptych configurations. To bridge the data gap, we carefully curated a high-quality dataset of 12k identity-consistent samples with 8k from real-world sources and 4k from high-quality synthetic data, avoiding the overly glossy and over-saturated synthetic appearance. IC-Custom supports various industrial applications, including try-on, accessory placement, furniture arrangement, and creative IP customization. Extensive evaluations on our proposed ProductBench and the publicly available DreamBench demonstrate that IC-Custom significantly outperforms community workflows, closed-source models, and state-of-the-art open-source approaches. IC-Custom achieves approximately 73% higher human preference across identity consistency, harmonicity, and text alignment metrics, while training only 0.4% of the original model parameters. Project page: https://liyaowei-stu.github.io/project/IC_Custom
Cobra: Efficient Line Art COlorization with BRoAder References
Apr 16, 2025The comic production industry requires reference-based line art colorization with high accuracy, efficiency, contextual consistency, and flexible control. A comic page often involves diverse characters, objects, and backgrounds, which complicates the coloring process. Despite advancements in diffusion models for image generation, their application in line art colorization remains limited, facing challenges related to handling extensive reference images, time-consuming inference, and flexible control. We investigate the necessity of extensive contextual image guidance on the quality of line art colorization. To address these challenges, we introduce Cobra, an efficient and versatile method that supports color hints and utilizes over 200 reference images while maintaining low latency. Central to Cobra is a Causal Sparse DiT architecture, which leverages specially designed positional encodings, causal sparse attention, and Key-Value Cache to effectively manage long-context references and ensure color identity consistency. Results demonstrate that Cobra achieves accurate line art colorization through extensive contextual reference, significantly enhancing inference speed and interactivity, thereby meeting critical industrial demands. We release our codes and models on our project page: https://zhuang2002.github.io/Cobra/.
BlobCtrl: A Unified and Flexible Framework for Element-level Image Generation and Editing
Mar 17, 2025Element-level visual manipulation is essential in digital content creation, but current diffusion-based methods lack the precision and flexibility of traditional tools. In this work, we introduce BlobCtrl, a framework that unifies element-level generation and editing using a probabilistic blob-based representation. By employing blobs as visual primitives, our approach effectively decouples and represents spatial location, semantic content, and identity information, enabling precise element-level manipulation. Our key contributions include: 1) a dual-branch diffusion architecture with hierarchical feature fusion for seamless foreground-background integration; 2) a self-supervised training paradigm with tailored data augmentation and score functions; and 3) controllable dropout strategies to balance fidelity and diversity. To support further research, we introduce BlobData for large-scale training and BlobBench for systematic evaluation. Experiments show that BlobCtrl excels in various element-level manipulation tasks while maintaining computational efficiency, offering a practical solution for precise and flexible visual content creation. Project page: https://liyaowei-stu.github.io/project/BlobCtrl/
NVComposer: Boosting Generative Novel View Synthesis with Multiple Sparse and Unposed Images
Dec 04, 2024



Recent advancements in generative models have significantly improved novel view synthesis (NVS) from multi-view data. However, existing methods depend on external multi-view alignment processes, such as explicit pose estimation or pre-reconstruction, which limits their flexibility and accessibility, especially when alignment is unstable due to insufficient overlap or occlusions between views. In this paper, we propose NVComposer, a novel approach that eliminates the need for explicit external alignment. NVComposer enables the generative model to implicitly infer spatial and geometric relationships between multiple conditional views by introducing two key components: 1) an image-pose dual-stream diffusion model that simultaneously generates target novel views and condition camera poses, and 2) a geometry-aware feature alignment module that distills geometric priors from dense stereo models during training. Extensive experiments demonstrate that NVComposer achieves state-of-the-art performance in generative multi-view NVS tasks, removing the reliance on external alignment and thus improving model accessibility. Our approach shows substantial improvements in synthesis quality as the number of unposed input views increases, highlighting its potential for more flexible and accessible generative NVS systems.
Uni-ISP: Unifying the Learning of ISPs from Multiple Cameras
Jun 03, 2024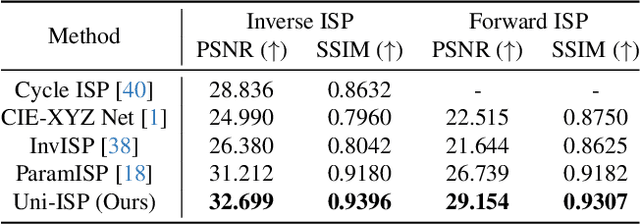
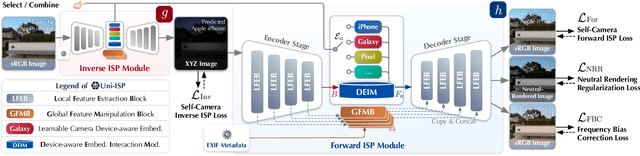
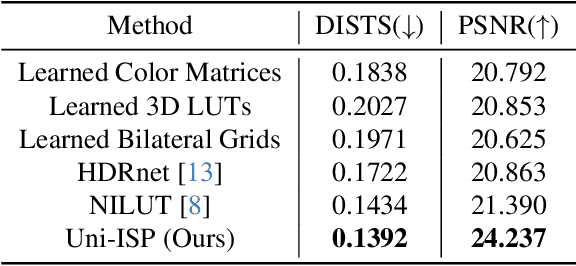

Modern end-to-end image signal processors (ISPs) can learn complex mappings from RAW/XYZ data to sRGB (or inverse), opening new possibilities in image processing. However, as the diversity of camera models continues to expand, developing and maintaining individual ISPs is not sustainable in the long term, which inherently lacks versatility, hindering the adaptability to multiple camera models. In this paper, we propose a novel pipeline, Uni-ISP, which unifies the learning of ISPs from multiple cameras, offering an accurate and versatile processor to multiple camera models. The core of Uni-ISP is leveraging device-aware embeddings through learning inverse/forward ISPs and its special training scheme. By doing so, Uni-ISP not only improves the performance of inverse/forward ISPs but also unlocks a variety of new applications inaccessible to existing learned ISPs. Moreover, since there is no dataset synchronously captured by multiple cameras for training, we construct a real-world 4K dataset, FiveCam, comprising more than 2,400 pairs of sRGB-RAW images synchronously captured by five smartphones. We conducted extensive experiments demonstrating Uni-ISP's accuracy in inverse/forward ISPs (with improvements of +1.5dB/2.4dB PSNR), its versatility in enabling new applications, and its adaptability to new camera models.
Computational Spectral Imaging with Unified Encoding Model: A Comparative Study and Beyond
Dec 20, 2023Computational spectral imaging is drawing increasing attention owing to the snapshot advantage, and amplitude, phase, and wavelength encoding systems are three types of representative implementations. Fairly comparing and understanding the performance of these systems is essential, but challenging due to the heterogeneity in encoding design. To overcome this limitation, we propose the unified encoding model (UEM) that covers all physical systems using the three encoding types. Specifically, the UEM comprises physical amplitude, physical phase, and physical wavelength encoding models that can be combined with a digital decoding model in a joint encoder-decoder optimization framework to compare the three systems under a unified experimental setup fairly. Furthermore, we extend the UEMs to ideal versions, namely, ideal amplitude, ideal phase, and ideal wavelength encoding models, which are free from physical constraints, to explore the full potential of the three types of computational spectral imaging systems. Finally, we conduct a holistic comparison of the three types of computational spectral imaging systems and provide valuable insights for designing and exploiting these systems in the future.
Reconstruct-and-Generate Diffusion Model for Detail-Preserving Image Denoising
Sep 19, 2023



Image denoising is a fundamental and challenging task in the field of computer vision. Most supervised denoising methods learn to reconstruct clean images from noisy inputs, which have intrinsic spectral bias and tend to produce over-smoothed and blurry images. Recently, researchers have explored diffusion models to generate high-frequency details in image restoration tasks, but these models do not guarantee that the generated texture aligns with real images, leading to undesirable artifacts. To address the trade-off between visual appeal and fidelity of high-frequency details in denoising tasks, we propose a novel approach called the Reconstruct-and-Generate Diffusion Model (RnG). Our method leverages a reconstructive denoising network to recover the majority of the underlying clean signal, which serves as the initial estimation for subsequent steps to maintain fidelity. Additionally, it employs a diffusion algorithm to generate residual high-frequency details, thereby enhancing visual quality. We further introduce a two-stage training scheme to ensure effective collaboration between the reconstructive and generative modules of RnG. To reduce undesirable texture introduced by the diffusion model, we also propose an adaptive step controller that regulates the number of inverse steps applied by the diffusion model, allowing control over the level of high-frequency details added to each patch as well as saving the inference computational cost. Through our proposed RnG, we achieve a better balance between perception and distortion. We conducted extensive experiments on both synthetic and real denoising datasets, validating the superiority of the proposed approach.