 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePJB: A Reasoning-Aware Benchmark for Person-Job Retrieval
Mar 18, 2026As retrieval models converge on generic benchmarks, the pressing question is no longer "who scores higher" but rather "where do systems fail, and why?" Person-job matching is a domain that urgently demands such diagnostic capability -- it requires systems not only to verify explicit constraints but also to perform skill-transfer inference and job-competency reasoning, yet existing benchmarks provide no systematic diagnostic support for this task. We introduce PJB (Person-Job Benchmark), a reasoning-aware retrieval evaluation dataset that uses complete job descriptions as queries and complete resumes as documents, defines relevance through job-competency judgment, is grounded in real-world recruitment data spanning six industry domains and nearly 200,000 resumes, and upgrades evaluation from "who scores higher" to "where do systems differ, and why" through domain-family and reasoning-type diagnostic labels. Diagnostic experiments using dense retrieval reveal that performance heterogeneity across industry domains far exceeds the gains from module upgrades for the same model, indicating that aggregate scores alone can severely mislead optimization decisions. At the module level, reranking yields stable improvements while query understanding not only fails to help but actually degrades overall performance when combined with reranking -- the two modules face fundamentally different improvement bottlenecks. The value of PJB lies not in yet another leaderboard of average scores, but in providing recruitment retrieval systems with a capability map that pinpoints where to invest.
CRE-T1 Preview Technical Report: Beyond Contrastive Learning for Reasoning-Intensive Retrieval
Mar 18, 2026The central challenge of reasoning-intensive retrieval lies in identifying implicitreasoning relationships between queries and documents, rather than superficial se-mantic or lexical similarity. The contrastive learning paradigm is fundamentallya static representation consolidation technique: during training, it encodes hier-archical relevance concepts into fixed geometric structures in the vector space,and at inference time it cannot dynamically adjust relevance judgments accord-ing to the specific reasoning demands of each query. Consequently, performancedegrades noticeably when vocabulary mismatch exists between queries and doc-uments or when implicit reasoning is required to establish relevance. This pa-per proposes Thought 1 (T1), a generative retrieval model that shifts relevancemodeling from static alignment to dynamic reasoning. On the query side, T1 dy-namically generates intermediate reasoning trajectories for each query to bridgeimplicit reasoning relationships and uses <embtoken> as a semantic aggregationpoint for the reasoning output. On the document side, it employs an instruction+ text + <embtoken> encoding format to support high-throughput indexing. Tointernalize dynamic reasoning capabilities into vector representations, we adopt athree-stage training curriculum and introduce GRPO in the third stage, enablingthe model to learn optimal derivation strategies for different queries through trial-and-error reinforcement learning. On the BRIGHT benchmark, T1-4B exhibitsstrong performance under the original query setting, outperforming larger modelstrained with contrastive learning overall, and achieving performance comparableto multi-stage retrieval pipelines. The results demonstrate that replacing static rep-resentation alignment with dynamic reasoning generation can effectively improvereasoning-intensive retrieval performance.
CubeComposer: Spatio-Temporal Autoregressive 4K 360° Video Generation from Perspective Video
Mar 04, 2026Generating high-quality 360° panoramic videos from perspective input is one of the crucial applications for virtual reality (VR), whereby high-resolution videos are especially important for immersive experience. Existing methods are constrained by computational limitations of vanilla diffusion models, only supporting $\leq$ 1K resolution native generation and relying on suboptimal post super-resolution to increase resolution. We introduce CubeComposer, a novel spatio-temporal autoregressive diffusion model that natively generates 4K-resolution 360° videos. By decomposing videos into cubemap representations with six faces, CubeComposer autoregressively synthesizes content in a well-planned spatio-temporal order, reducing memory demands while enabling high-resolution output. Specifically, to address challenges in multi-dimensional autoregression, we propose: (1) a spatio-temporal autoregressive strategy that orchestrates 360° video generation across cube faces and time windows for coherent synthesis; (2) a cube face context management mechanism, equipped with a sparse context attention design to improve efficiency; and (3) continuity-aware techniques, including cube-aware positional encoding, padding, and blending to eliminate boundary seams. Extensive experiments on benchmark datasets demonstrate that CubeComposer outperforms state-of-the-art methods in native resolution and visual quality, supporting practical VR application scenarios. Project page: https://lg-li.github.io/project/cubecomposer
Time-Scaling Is What Agents Need Now
Jan 06, 2026Early artificial intelligence paradigms exhibited separated cognitive functions: Neural Networks focused on "perception-representation," Reinforcement Learning on "decision-making-behavior," and Symbolic AI on "knowledge-reasoning." With Transformer-based large models and world models, these paradigms are converging into cognitive agents with closed-loop "perception-decision-action" capabilities. Humans solve complex problems under limited cognitive resources through temporalized sequential reasoning. Language relies on problem space search for deep semantic reasoning. While early large language models (LLMs) could generate fluent text, they lacked robust semantic reasoning capabilities. Prompting techniques like Chain-of-Thought (CoT) and Tree-of-Thought (ToT) extended reasoning paths by making intermediate steps explicit. Recent models like DeepSeek-R1 enhanced performance through explicit reasoning trajectories. However, these methods have limitations in search completeness and efficiency. This highlights the need for "Time-Scaling"--the systematic extension and optimization of an agent's ability to unfold reasoning over time. Time-Scaling refers to architectural design utilizing extended temporal pathways, enabling deeper problem space exploration, dynamic strategy adjustment, and enhanced metacognitive control, paralleling human sequential reasoning under cognitive constraints. It represents a critical frontier for enhancing deep reasoning and problem-solving without proportional increases in static model parameters. Advancing intelligent agent capabilities requires placing Time-Scaling principles at the forefront, positioning explicit temporal reasoning management as foundational.
ToonComposer: Streamlining Cartoon Production with Generative Post-Keyframing
Aug 14, 2025
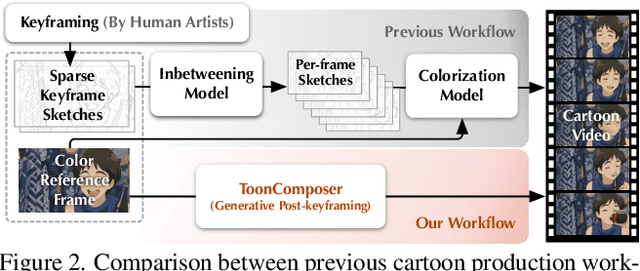
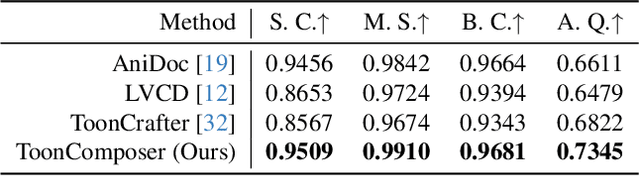
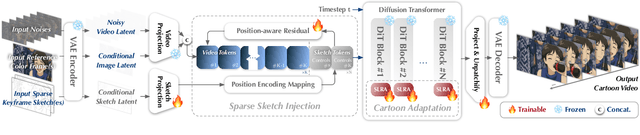
Traditional cartoon and anime production involves keyframing, inbetweening, and colorization stages, which require intensive manual effort. Despite recent advances in AI, existing methods often handle these stages separately, leading to error accumulation and artifacts. For instance, inbetweening approaches struggle with large motions, while colorization methods require dense per-frame sketches. To address this, we introduce ToonComposer, a generative model that unifies inbetweening and colorization into a single post-keyframing stage. ToonComposer employs a sparse sketch injection mechanism to provide precise control using keyframe sketches. Additionally, it uses a cartoon adaptation method with the spatial low-rank adapter to tailor a modern video foundation model to the cartoon domain while keeping its temporal prior intact. Requiring as few as a single sketch and a colored reference frame, ToonComposer excels with sparse inputs, while also supporting multiple sketches at any temporal location for more precise motion control. This dual capability reduces manual workload and improves flexibility, empowering artists in real-world scenarios. To evaluate our model, we further created PKBench, a benchmark featuring human-drawn sketches that simulate real-world use cases. Our evaluation demonstrates that ToonComposer outperforms existing methods in visual quality, motion consistency, and production efficiency, offering a superior and more flexible solution for AI-assisted cartoon production.
BlobCtrl: A Unified and Flexible Framework for Element-level Image Generation and Editing
Mar 17, 2025Element-level visual manipulation is essential in digital content creation, but current diffusion-based methods lack the precision and flexibility of traditional tools. In this work, we introduce BlobCtrl, a framework that unifies element-level generation and editing using a probabilistic blob-based representation. By employing blobs as visual primitives, our approach effectively decouples and represents spatial location, semantic content, and identity information, enabling precise element-level manipulation. Our key contributions include: 1) a dual-branch diffusion architecture with hierarchical feature fusion for seamless foreground-background integration; 2) a self-supervised training paradigm with tailored data augmentation and score functions; and 3) controllable dropout strategies to balance fidelity and diversity. To support further research, we introduce BlobData for large-scale training and BlobBench for systematic evaluation. Experiments show that BlobCtrl excels in various element-level manipulation tasks while maintaining computational efficiency, offering a practical solution for precise and flexible visual content creation. Project page: https://liyaowei-stu.github.io/project/BlobCtrl/
S3Editor: A Sparse Semantic-Disentangled Self-Training Framework for Face Video Editing
Apr 11, 2024Face attribute editing plays a pivotal role in various applications. However, existing methods encounter challenges in achieving high-quality results while preserving identity, editing faithfulness, and temporal consistency. These challenges are rooted in issues related to the training pipeline, including limited supervision, architecture design, and optimization strategy. In this work, we introduce S3Editor, a Sparse Semantic-disentangled Self-training framework for face video editing. S3Editor is a generic solution that comprehensively addresses these challenges with three key contributions. Firstly, S3Editor adopts a self-training paradigm to enhance the training process through semi-supervision. Secondly, we propose a semantic disentangled architecture with a dynamic routing mechanism that accommodates diverse editing requirements. Thirdly, we present a structured sparse optimization schema that identifies and deactivates malicious neurons to further disentangle impacts from untarget attributes. S3Editor is model-agnostic and compatible with various editing approaches. Our extensive qualitative and quantitative results affirm that our approach significantly enhances identity preservation, editing fidelity, as well as temporal consistency.
Navigate Biopsy with Ultrasound under Augmented Reality Device: Towards Higher System Performance
Feb 04, 2024
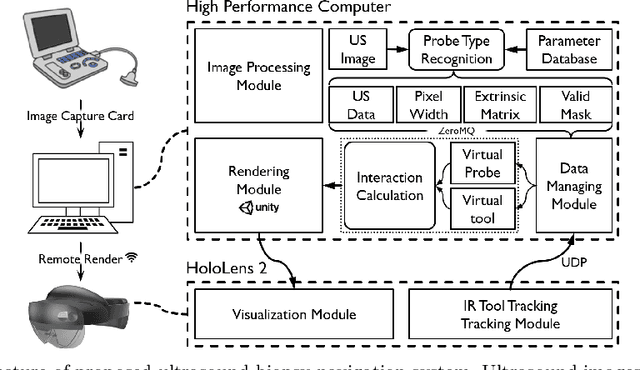
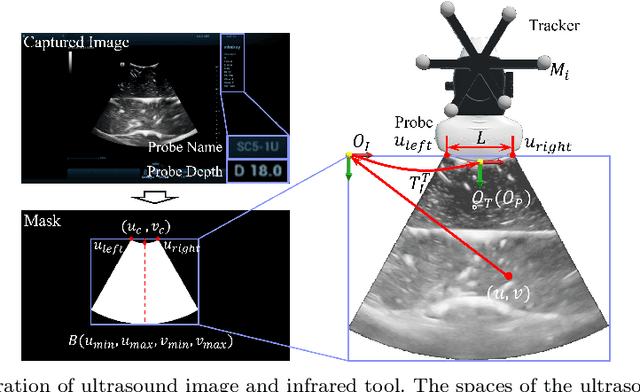
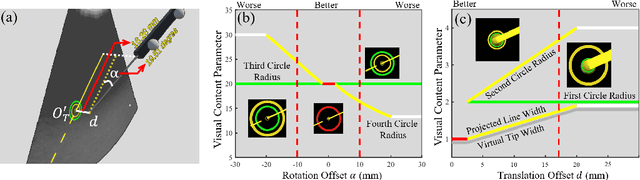
Purpose: Biopsies play a crucial role in determining the classification and staging of tumors. Ultrasound is frequently used in this procedure to provide real-time anatomical information. Using augmented reality (AR), surgeons can visualize ultrasound data and spatial navigation information seamlessly integrated with real tissues. This innovation facilitates faster and more precise biopsy operations. Methods: We developed an AR biopsy navigation system with low display latency and high accuracy. Ultrasound data is initially read by an image capture card and streamed to Unity via net communication. In Unity, navigation information is rendered and transmitted to the HoloLens 2 device using holographic remoting. Retro-reflective tool tracking is implemented on the HoloLens 2, enabling simultaneous tracking of the ultrasound probe and biopsy needle. Distinct navigation information is provided during in-plane and out-of-plane punctuation. To evaluate the effectiveness of our system, we conducted a study involving ten participants, for puncture accuracy and biopsy time, comparing to traditional methods. Results: Our proposed framework enables ultrasound visualization in AR with only $16.22\pm11.45ms$ additional latency. Navigation accuracy reached $1.23\pm 0.68mm$ in the image plane and $0.95\pm 0.70mm$ outside the image plane. Remarkably, the utilization of our system led to $98\%$ and $95\%$ success rate in out-of-plane and in-plane biopsy. Conclusion: To sum up, this paper introduces an AR-based ultrasound biopsy navigation system characterized by high navigation accuracy and minimal latency. The system provides distinct visualization contents during in-plane and out-of-plane operations according to their different characteristics. Use case study in this paper proved that our system can help young surgeons perform biopsy faster and more accurately.
The Efficiency Spectrum of Large Language Models: An Algorithmic Survey
Dec 01, 2023
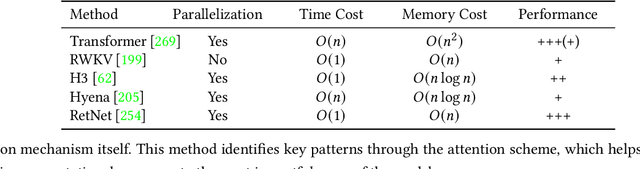
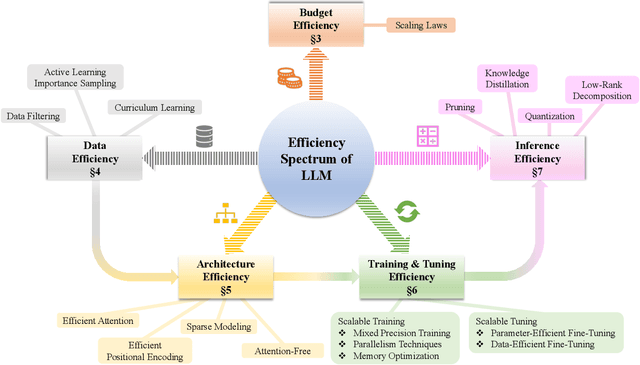
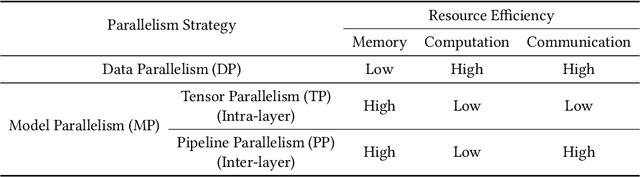
The rapid growth of Large Language Models (LLMs) has been a driving force in transforming various domains, reshaping the artificial general intelligence landscape. However, the increasing computational and memory demands of these models present substantial challenges, hindering both academic research and practical applications. To address these issues, a wide array of methods, including both algorithmic and hardware solutions, have been developed to enhance the efficiency of LLMs. This survey delivers a comprehensive review of algorithmic advancements aimed at improving LLM efficiency. Unlike other surveys that typically focus on specific areas such as training or model compression, this paper examines the multi-faceted dimensions of efficiency essential for the end-to-end algorithmic development of LLMs. Specifically, it covers various topics related to efficiency, including scaling laws, data utilization, architectural innovations, training and tuning strategies, and inference techniques. This paper aims to serve as a valuable resource for researchers and practitioners, laying the groundwork for future innovations in this critical research area. Our repository of relevant references is maintained at url{https://github.com/tding1/Efficient-LLM-Survey}.
SEED-Bench-2: Benchmarking Multimodal Large Language Models
Nov 28, 2023Multimodal large language models (MLLMs), building upon the foundation of powerful large language models (LLMs), have recently demonstrated exceptional capabilities in generating not only texts but also images given interleaved multimodal inputs (acting like a combination of GPT-4V and DALL-E 3). However, existing MLLM benchmarks remain limited to assessing only models' comprehension ability of single image-text inputs, failing to keep up with the strides made in MLLMs. A comprehensive benchmark is imperative for investigating the progress and uncovering the limitations of current MLLMs. In this work, we categorize the capabilities of MLLMs into hierarchical levels from $L_0$ to $L_4$ based on the modalities they can accept and generate, and propose SEED-Bench-2, a comprehensive benchmark that evaluates the \textbf{hierarchical} capabilities of MLLMs. Specifically, SEED-Bench-2 comprises 24K multiple-choice questions with accurate human annotations, which spans 27 dimensions, including the evaluation of both text and image generation. Multiple-choice questions with groundtruth options derived from human annotation enables an objective and efficient assessment of model performance, eliminating the need for human or GPT intervention during evaluation. We further evaluate the performance of 23 prominent open-source MLLMs and summarize valuable observations. By revealing the limitations of existing MLLMs through extensive evaluations, we aim for SEED-Bench-2 to provide insights that will motivate future research towards the goal of General Artificial Intelligence. Dataset and evaluation code are available at \href{https://github.com/AILab-CVC/SEED-Bench}