 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Video Diffusion Policy: A 3D Spatio-Temporal-Aware Video Action Model
Apr 03, 2026Robotic manipulation requires understanding both the 3D spatial structure of the environment and its temporal evolution, yet most existing policies overlook one or both. They typically rely on 2D visual observations and backbones pretrained on static image--text pairs, resulting in high data requirements and limited understanding of environment dynamics. To address this, we introduce MV-VDP, a multi-view video diffusion policy that jointly models the 3D spatio-temporal state of the environment. The core idea is to simultaneously predict multi-view heatmap videos and RGB videos, which 1) align the representation format of video pretraining with action finetuning, and 2) specify not only what actions the robot should take, but also how the environment is expected to evolve in response to those actions. Extensive experiments show that MV-VDP enables data-efficient, robust, generalizable, and interpretable manipulation. With only ten demonstration trajectories and without additional pretraining, MV-VDP successfully performs complex real-world tasks, demonstrates strong robustness across a range of model hyperparameters, generalizes to out-of-distribution settings, and predicts realistic future videos. Experiments on Meta-World and real-world robotic platforms demonstrate that MV-VDP consistently outperforms video-prediction--based, 3D-based, and vision--language--action models, establishing a new state of the art in data-efficient multi-task manipulation.
MathPhys-Guided Coarse-to-Fine Anomaly Synthesis with SQE-Driven Bi-Level Optimization for Anomaly Detection
Apr 17, 2025Anomaly detection is a crucial task in computer vision, yet collecting real-world defect images is inherently difficult due to the rarity and unpredictability of anomalies. Consequently, researchers have turned to synthetic methods for training data augmentation. However, existing synthetic strategies (e.g., naive cut-and-paste or inpainting) overlook the underlying physical causes of defects, leading to inconsistent, low-fidelity anomalies that hamper model generalization to real-world complexities. In this thesis, we introduced a novel pipeline that generates synthetic anomalies through Math-Physics model guidance, refines them via a Coarse-to-Fine approach and employs a bi-level optimization strategy with a Synthesis Quality Estimator(SQE). By incorporating physical modeling of cracks, corrosion, and deformation, our method produces realistic defect masks, which are subsequently enhanced in two phases. The first stage (npcF) enforces a PDE-based consistency to achieve a globally coherent anomaly structure, while the second stage (npcF++) further improves local fidelity using wavelet transforms and boundary synergy blocks. Additionally, we leverage SQE-driven weighting, ensuring that high-quality synthetic samples receive greater emphasis during training. To validate our approach, we conducted comprehensive experiments on three widely adopted industrial anomaly detection benchmarks: MVTec AD, VisA, and BTAD. Across these datasets, the proposed pipeline achieves state-of-the-art (SOTA) results in both image-AUROC and pixel-AUROC, confirming the effectiveness of our MaPhC2F and BiSQAD.
Bootstrapped Model Predictive Control
Mar 24, 2025



Model Predictive Control (MPC) has been demonstrated to be effective in continuous control tasks. When a world model and a value function are available, planning a sequence of actions ahead of time leads to a better policy. Existing methods typically obtain the value function and the corresponding policy in a model-free manner. However, we find that such an approach struggles with complex tasks, resulting in poor policy learning and inaccurate value estimation. To address this problem, we leverage the strengths of MPC itself. In this work, we introduce Bootstrapped Model Predictive Control (BMPC), a novel algorithm that performs policy learning in a bootstrapped manner. BMPC learns a network policy by imitating an MPC expert, and in turn, uses this policy to guide the MPC process. Combined with model-based TD-learning, our policy learning yields better value estimation and further boosts the efficiency of MPC. We also introduce a lazy reanalyze mechanism, which enables computationally efficient imitation learning. Our method achieves superior performance over prior works on diverse continuous control tasks. In particular, on challenging high-dimensional locomotion tasks, BMPC significantly improves data efficiency while also enhancing asymptotic performance and training stability, with comparable training time and smaller network sizes. Code is available at https://github.com/wertyuilife2/bmpc.
Friend or Foe? Harnessing Controllable Overfitting for Anomaly Detection
Nov 30, 2024



Overfitting has long been stigmatized as detrimental to model performance, especially in the context of anomaly detection. Our work challenges this conventional view by introducing a paradigm shift, recasting overfitting as a controllable and strategic mechanism for enhancing model discrimination capabilities. In this paper, we present Controllable Overfitting-based Anomaly Detection (COAD), a novel framework designed to leverage overfitting for optimized anomaly detection. We propose the Aberrance Retention Quotient (ARQ), a novel metric that systematically quantifies the extent of overfitting, enabling the identification of an optimal "golden overfitting interval." Within this interval, overfitting is leveraged to significantly amplify the model's sensitivity to anomalous patterns, while preserving generalization to normal samples. Additionally, we present the Relative Anomaly Distribution Index (RADI), an innovative metric designed to complement AUROC pixel by providing a more versatile and theoretically robust framework for assessing model performance. RADI leverages ARQ to track and evaluate how overfitting impacts anomaly detection, offering an integrated approach to understanding the relationship between overfitting dynamics and model efficacy. Our theoretical work also rigorously validates the use of Gaussian noise in pseudo anomaly synthesis, providing the foundation for its broader applicability across diverse domains. Empirical evaluations demonstrate that our controllable overfitting method not only achieves State of the Art (SOTA) performance in both one-class and multi-class anomaly detection tasks but also redefines overfitting from a modeling challenge into a powerful tool for optimizing anomaly detection.
STEP: Enhancing Video-LLMs' Compositional Reasoning by Spatio-Temporal Graph-guided Self-Training
Nov 29, 2024Video Large Language Models (Video-LLMs) have recently shown strong performance in basic video understanding tasks, such as captioning and coarse-grained question answering, but struggle with compositional reasoning that requires multi-step spatio-temporal inference across object relations, interactions, and events. The hurdles to enhancing this capability include extensive manual labor, the lack of spatio-temporal compositionality in existing data and the absence of explicit reasoning supervision. In this paper, we propose STEP, a novel graph-guided self-training method that enables Video-LLMs to generate reasoning-rich fine-tuning data from any raw videos to improve itself. Specifically, we first induce Spatio-Temporal Scene Graph (STSG) representation of diverse videos to capture fine-grained, multi-granular video semantics. Then, the STSGs guide the derivation of multi-step reasoning Question-Answer (QA) data with Chain-of-Thought (CoT) rationales. Both answers and rationales are integrated as training objective, aiming to enhance model's reasoning abilities by supervision over explicit reasoning steps. Experimental results demonstrate the effectiveness of STEP across models of varying scales, with a significant 21.3\% improvement in tasks requiring three or more reasoning steps. Furthermore, it achieves superior performance with a minimal amount of self-generated rationale-enriched training samples in both compositional reasoning and comprehensive understanding benchmarks, highlighting the broad applicability and vast potential.
Enhancing Decision Transformer with Diffusion-Based Trajectory Branch Generation
Nov 18, 2024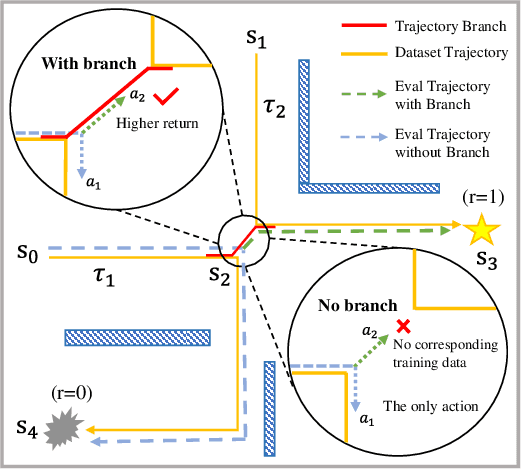
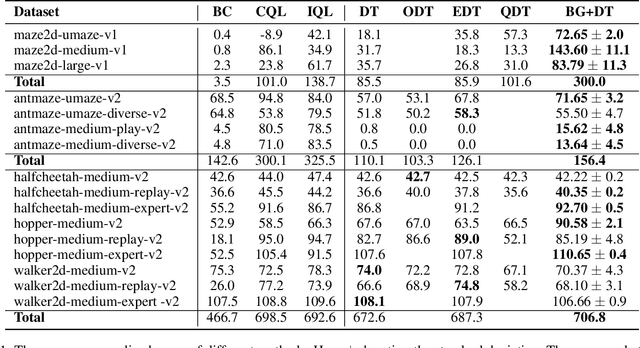
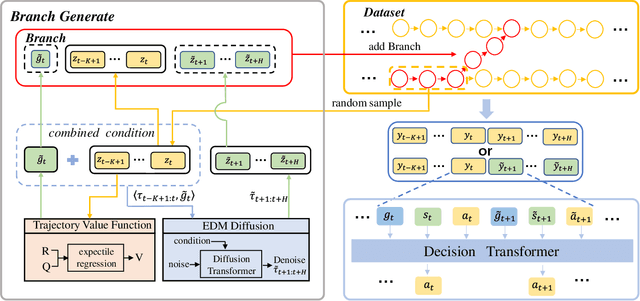
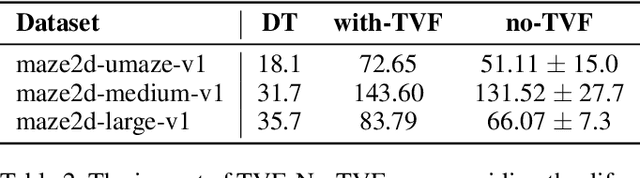
Decision Transformer (DT) can learn effective policy from offline datasets by converting the offline reinforcement learning (RL) into a supervised sequence modeling task, where the trajectory elements are generated auto-regressively conditioned on the return-to-go (RTG).However, the sequence modeling learning approach tends to learn policies that converge on the sub-optimal trajectories within the dataset, for lack of bridging data to move to better trajectories, even if the condition is set to the highest RTG.To address this issue, we introduce Diffusion-Based Trajectory Branch Generation (BG), which expands the trajectories of the dataset with branches generated by a diffusion model.The trajectory branch is generated based on the segment of the trajectory within the dataset, and leads to trajectories with higher returns.We concatenate the generated branch with the trajectory segment as an expansion of the trajectory.After expanding, DT has more opportunities to learn policies to move to better trajectories, preventing it from converging to the sub-optimal trajectories.Empirically, after processing with BG, DT outperforms state-of-the-art sequence modeling methods on D4RL benchmark, demonstrating the effectiveness of adding branches to the dataset without further modifications.
Grounded Answers for Multi-agent Decision-making Problem through Generative World Model
Oct 03, 2024


Recent progress in generative models has stimulated significant innovations in many fields, such as image generation and chatbots. Despite their success, these models often produce sketchy and misleading solutions for complex multi-agent decision-making problems because they miss the trial-and-error experience and reasoning as humans. To address this limitation, we explore a paradigm that integrates a language-guided simulator into the multi-agent reinforcement learning pipeline to enhance the generated answer. The simulator is a world model that separately learns dynamics and reward, where the dynamics model comprises an image tokenizer as well as a causal transformer to generate interaction transitions autoregressively, and the reward model is a bidirectional transformer learned by maximizing the likelihood of trajectories in the expert demonstrations under language guidance. Given an image of the current state and the task description, we use the world model to train the joint policy and produce the image sequence as the answer by running the converged policy on the dynamics model. The empirical results demonstrate that this framework can improve the answers for multi-agent decision-making problems by showing superior performance on the training and unseen tasks of the StarCraft Multi-Agent Challenge benchmark. In particular, it can generate consistent interaction sequences and explainable reward functions at interaction states, opening the path for training generative models of the future.
Momentor: Advancing Video Large Language Model with Fine-Grained Temporal Reasoning
Feb 18, 2024



Large Language Models (LLMs) demonstrate remarkable proficiency in comprehending and handling text-based tasks. Many efforts are being made to transfer these attributes to video modality, which are termed Video-LLMs. However, existing Video-LLMs can only capture the coarse-grained semantics and are unable to effectively handle tasks related to comprehension or localization of specific video segments. In light of these challenges, we propose Momentor, a Video-LLM capable of accomplishing fine-grained temporal understanding tasks. To support the training of Momentor, we design an automatic data generation engine to construct Moment-10M, a large-scale video instruction dataset with segment-level instruction data. We train Momentor on Moment-10M, enabling it to perform segment-level reasoning and localization. Zero-shot evaluations on several tasks demonstrate that Momentor excels in fine-grained temporally grounded comprehension and localization.
Navigate Biopsy with Ultrasound under Augmented Reality Device: Towards Higher System Performance
Feb 04, 2024
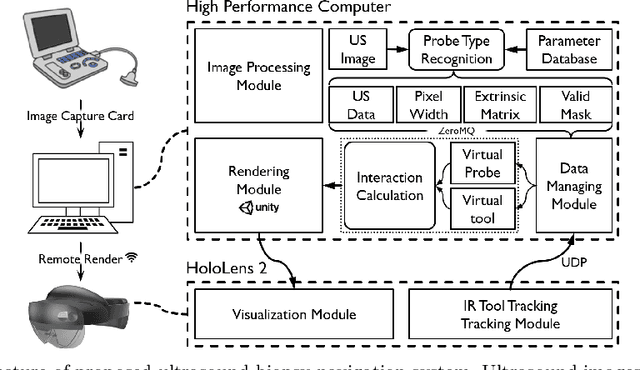
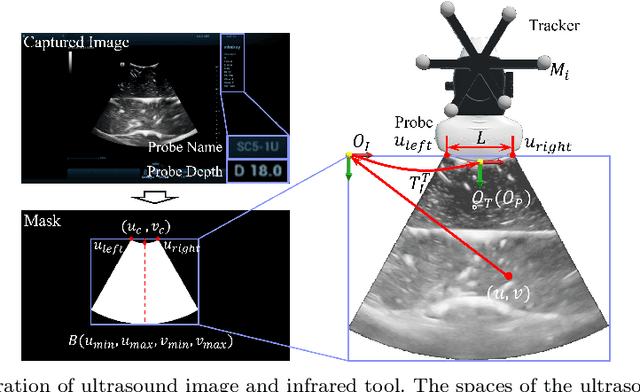
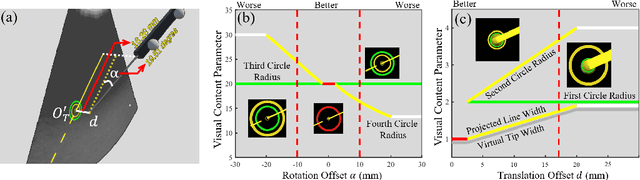
Purpose: Biopsies play a crucial role in determining the classification and staging of tumors. Ultrasound is frequently used in this procedure to provide real-time anatomical information. Using augmented reality (AR), surgeons can visualize ultrasound data and spatial navigation information seamlessly integrated with real tissues. This innovation facilitates faster and more precise biopsy operations. Methods: We developed an AR biopsy navigation system with low display latency and high accuracy. Ultrasound data is initially read by an image capture card and streamed to Unity via net communication. In Unity, navigation information is rendered and transmitted to the HoloLens 2 device using holographic remoting. Retro-reflective tool tracking is implemented on the HoloLens 2, enabling simultaneous tracking of the ultrasound probe and biopsy needle. Distinct navigation information is provided during in-plane and out-of-plane punctuation. To evaluate the effectiveness of our system, we conducted a study involving ten participants, for puncture accuracy and biopsy time, comparing to traditional methods. Results: Our proposed framework enables ultrasound visualization in AR with only $16.22\pm11.45ms$ additional latency. Navigation accuracy reached $1.23\pm 0.68mm$ in the image plane and $0.95\pm 0.70mm$ outside the image plane. Remarkably, the utilization of our system led to $98\%$ and $95\%$ success rate in out-of-plane and in-plane biopsy. Conclusion: To sum up, this paper introduces an AR-based ultrasound biopsy navigation system characterized by high navigation accuracy and minimal latency. The system provides distinct visualization contents during in-plane and out-of-plane operations according to their different characteristics. Use case study in this paper proved that our system can help young surgeons perform biopsy faster and more accurately.
EVD Surgical Guidance with Retro-Reflective Tool Tracking and Spatial Reconstruction using Head-Mounted Augmented Reality Device
Jul 03, 2023



Augmented Reality (AR) has been used to facilitate surgical guidance during External Ventricular Drain (EVD) surgery, reducing the risks of misplacement in manual operations. During this procedure, the key challenge is accurately estimating the spatial relationship between pre-operative images and actual patient anatomy in AR environment. This research proposes a novel framework utilizing Time of Flight (ToF) depth sensors integrated in commercially available AR Head Mounted Devices (HMD) for precise EVD surgical guidance. As previous studies have proven depth errors for ToF sensors, we first assessed their properties on AR-HMDs. Subsequently, a depth error model and patient-specific parameter identification method are introduced for accurate surface information. A tracking pipeline combining retro-reflective markers and point clouds is then proposed for accurate head tracking. The head surface is reconstructed using depth data for spatial registration, avoiding fixing tracking targets rigidly on the patient's skull. Firstly, $7.580\pm 1.488 mm$ depth value error was revealed on human skin, indicating the significance of depth correction. Our results showed that the error was reduced by over $85\%$ using proposed depth correction method on head phantoms in different materials. Meanwhile, the head surface reconstructed with corrected depth data achieved sub-millimetre accuracy. An experiment on sheep head revealed $0.79 mm$ reconstruction error. Furthermore, a user study was conducted for the performance in simulated EVD surgery, where five surgeons performed nine k-wire injections on a head phantom with virtual guidance. Results of this study revealed $2.09 \pm 0.16 mm$ translational accuracy and $2.97\pm 0.91$ degree orientational accuracy.