 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Refinement Regulation for Accelerating Diffusion Language Model Decoding
Mar 04, 2026Diffusion language models generate text through iterative denoising under a uniform refinement rule applied to all tokens. However, tokens stabilize at different rates in practice, leading to substantial redundant refinement and motivating refinement control over the denoising process. Existing approaches typically assess refinement necessity from instantaneous, step-level signals under a fixed decoding process. In contrast, whether a token has converged is defined by how its prediction changes along its future refinement trajectory. Moreover, changing the refinement rule reshapes future refinement trajectories, which in turn determine how refinement rules should be formulated, making refinement control inherently dynamic. We propose \emph{Progressive Refinement Regulation} (PRR), a progressive, trajectory-grounded refinement control framework that derives a token-level notion of empirical convergence progress from full decoding rollouts. Based on this signal, PRR learns a lightweight token-wise controller to regulate refinement via temperature-based distribution shaping under a progressive self-evolving training scheme. Experiments show that PRR substantially accelerates diffusion language model decoding while preserving generation quality.
Playing Non-Embedded Card-Based Games with Reinforcement Learning
Apr 07, 2025Significant progress has been made in AI for games, including board games, MOBA, and RTS games. However, complex agents are typically developed in an embedded manner, directly accessing game state information, unlike human players who rely on noisy visual data, leading to unfair competition. Developing complex non-embedded agents remains challenging, especially in card-based RTS games with complex features and large state spaces. We propose a non-embedded offline reinforcement learning training strategy using visual inputs to achieve real-time autonomous gameplay in the RTS game Clash Royale. Due to the lack of a object detection dataset for this game, we designed an efficient generative object detection dataset for training. We extract features using state-of-the-art object detection and optical character recognition models. Our method enables real-time image acquisition, perception feature fusion, decision-making, and control on mobile devices, successfully defeating built-in AI opponents. All code is open-sourced at https://github.com/wty-yy/katacr.
* Match videos: https://www.bilibili.com/video/BV1xn4y1R7GQ, All code: https://github.com/wty-yy/katacr, Detection dataset: https://github.com/wty-yy/Clash-Royale-Detection-Dataset, Expert dataset: https://github.com/wty-yy/Clash-Royale-Replay-Dataset
MInCo: Mitigating Information Conflicts in Distracted Visual Model-based Reinforcement Learning
Apr 05, 2025



Existing visual model-based reinforcement learning (MBRL) algorithms with observation reconstruction often suffer from information conflicts, making it difficult to learn compact representations and hence result in less robust policies, especially in the presence of task-irrelevant visual distractions. In this paper, we first reveal that the information conflicts in current visual MBRL algorithms stem from visual representation learning and latent dynamics modeling with an information-theoretic perspective. Based on this finding, we present a new algorithm to resolve information conflicts for visual MBRL, named MInCo, which mitigates information conflicts by leveraging negative-free contrastive learning, aiding in learning invariant representation and robust policies despite noisy observations. To prevent the dominance of visual representation learning, we introduce time-varying reweighting to bias the learning towards dynamics modeling as training proceeds. We evaluate our method on several robotic control tasks with dynamic background distractions. Our experiments demonstrate that MInCo learns invariant representations against background noise and consistently outperforms current state-of-the-art visual MBRL methods. Code is available at https://github.com/ShiguangSun/minco.
Enhancing Decision Transformer with Diffusion-Based Trajectory Branch Generation
Nov 18, 2024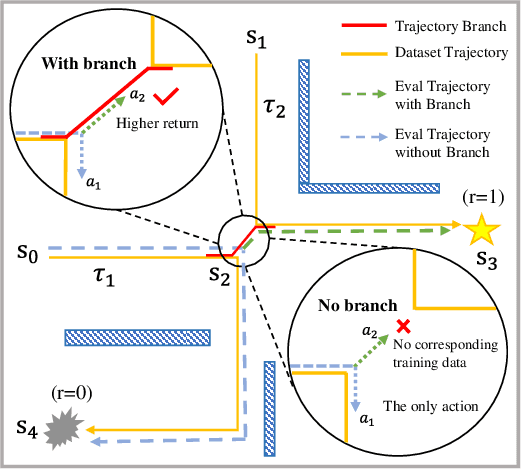
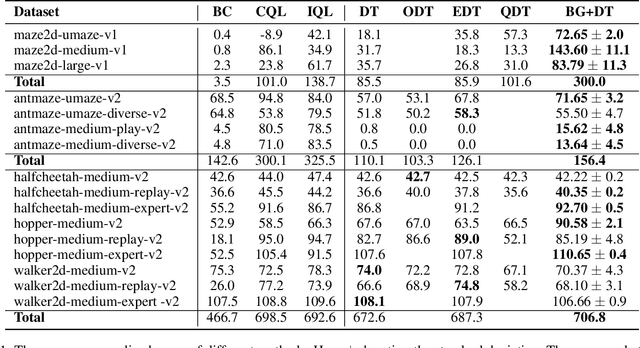
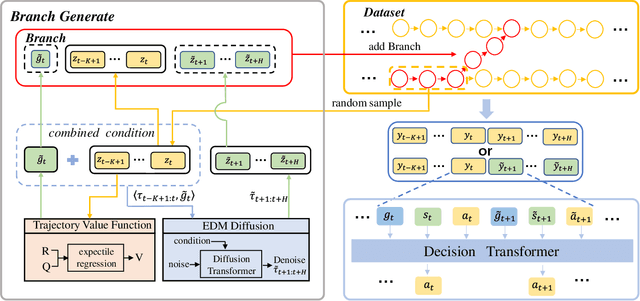
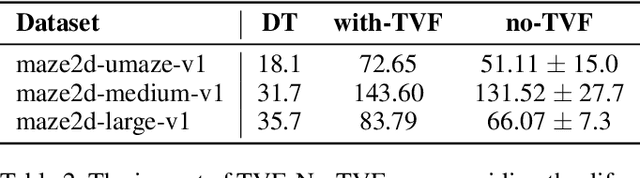
Decision Transformer (DT) can learn effective policy from offline datasets by converting the offline reinforcement learning (RL) into a supervised sequence modeling task, where the trajectory elements are generated auto-regressively conditioned on the return-to-go (RTG).However, the sequence modeling learning approach tends to learn policies that converge on the sub-optimal trajectories within the dataset, for lack of bridging data to move to better trajectories, even if the condition is set to the highest RTG.To address this issue, we introduce Diffusion-Based Trajectory Branch Generation (BG), which expands the trajectories of the dataset with branches generated by a diffusion model.The trajectory branch is generated based on the segment of the trajectory within the dataset, and leads to trajectories with higher returns.We concatenate the generated branch with the trajectory segment as an expansion of the trajectory.After expanding, DT has more opportunities to learn policies to move to better trajectories, preventing it from converging to the sub-optimal trajectories.Empirically, after processing with BG, DT outperforms state-of-the-art sequence modeling methods on D4RL benchmark, demonstrating the effectiveness of adding branches to the dataset without further modifications.
Grounded Answers for Multi-agent Decision-making Problem through Generative World Model
Oct 03, 2024


Recent progress in generative models has stimulated significant innovations in many fields, such as image generation and chatbots. Despite their success, these models often produce sketchy and misleading solutions for complex multi-agent decision-making problems because they miss the trial-and-error experience and reasoning as humans. To address this limitation, we explore a paradigm that integrates a language-guided simulator into the multi-agent reinforcement learning pipeline to enhance the generated answer. The simulator is a world model that separately learns dynamics and reward, where the dynamics model comprises an image tokenizer as well as a causal transformer to generate interaction transitions autoregressively, and the reward model is a bidirectional transformer learned by maximizing the likelihood of trajectories in the expert demonstrations under language guidance. Given an image of the current state and the task description, we use the world model to train the joint policy and produce the image sequence as the answer by running the converged policy on the dynamics model. The empirical results demonstrate that this framework can improve the answers for multi-agent decision-making problems by showing superior performance on the training and unseen tasks of the StarCraft Multi-Agent Challenge benchmark. In particular, it can generate consistent interaction sequences and explainable reward functions at interaction states, opening the path for training generative models of the future.
Imagine, Initialize, and Explore: An Effective Exploration Method in Multi-Agent Reinforcement Learning
Mar 01, 2024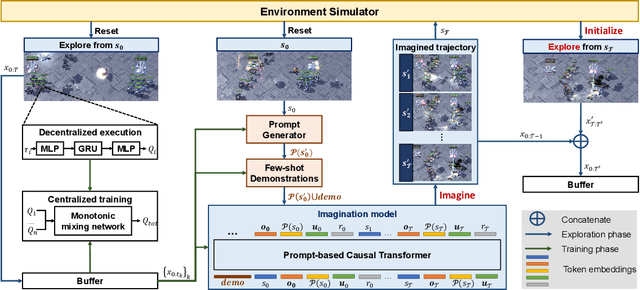
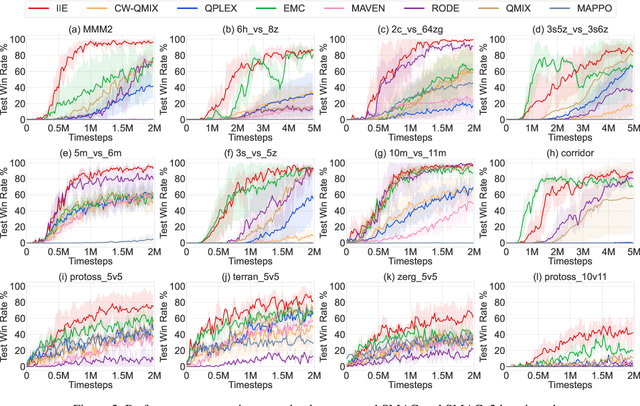
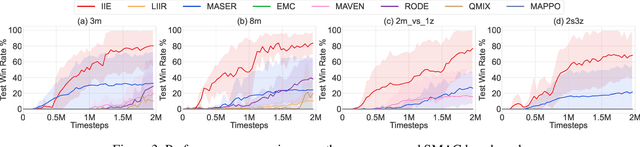
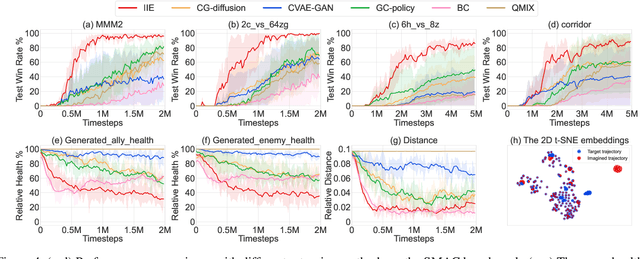
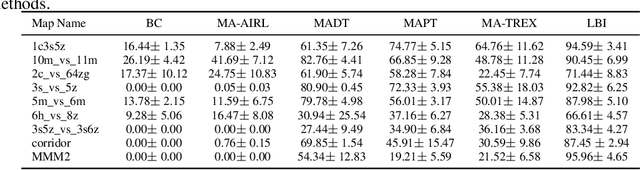
Effective exploration is crucial to discovering optimal strategies for multi-agent reinforcement learning (MARL) in complex coordination tasks. Existing methods mainly utilize intrinsic rewards to enable committed exploration or use role-based learning for decomposing joint action spaces instead of directly conducting a collective search in the entire action-observation space. However, they often face challenges obtaining specific joint action sequences to reach successful states in long-horizon tasks. To address this limitation, we propose Imagine, Initialize, and Explore (IIE), a novel method that offers a promising solution for efficient multi-agent exploration in complex scenarios. IIE employs a transformer model to imagine how the agents reach a critical state that can influence each other's transition functions. Then, we initialize the environment at this state using a simulator before the exploration phase. We formulate the imagination as a sequence modeling problem, where the states, observations, prompts, actions, and rewards are predicted autoregressively. The prompt consists of timestep-to-go, return-to-go, influence value, and one-shot demonstration, specifying the desired state and trajectory as well as guiding the action generation. By initializing agents at the critical states, IIE significantly increases the likelihood of discovering potentially important under-explored regions. Despite its simplicity, empirical results demonstrate that our method outperforms multi-agent exploration baselines on the StarCraft Multi-Agent Challenge (SMAC) and SMACv2 environments. Particularly, IIE shows improved performance in the sparse-reward SMAC tasks and produces more effective curricula over the initialized states than other generative methods, such as CVAE-GAN and diffusion models.
MGARD: A multigrid framework for high-performance, error-controlled data compression and refactoring
Jan 11, 2024We describe MGARD, a software providing MultiGrid Adaptive Reduction for floating-point scientific data on structured and unstructured grids. With exceptional data compression capability and precise error control, MGARD addresses a wide range of requirements, including storage reduction, high-performance I/O, and in-situ data analysis. It features a unified application programming interface (API) that seamlessly operates across diverse computing architectures. MGARD has been optimized with highly-tuned GPU kernels and efficient memory and device management mechanisms, ensuring scalable and rapid operations.
* 20 pages, 8 figures
Spatiotemporally adaptive compression for scientific dataset with feature preservation -- a case study on simulation data with extreme climate events analysis
Jan 06, 2024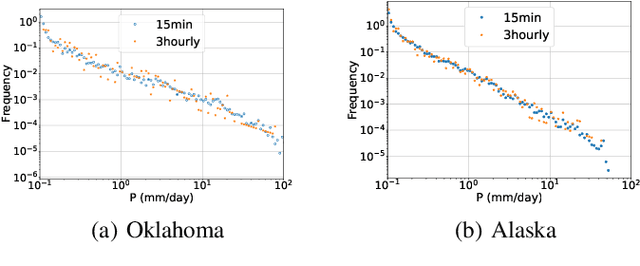
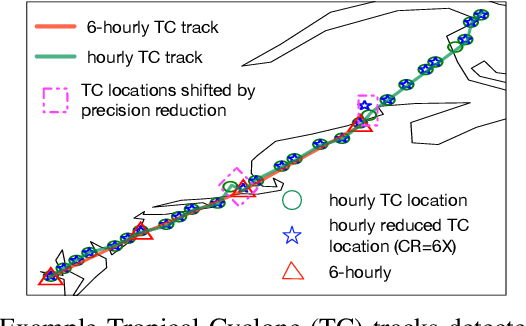
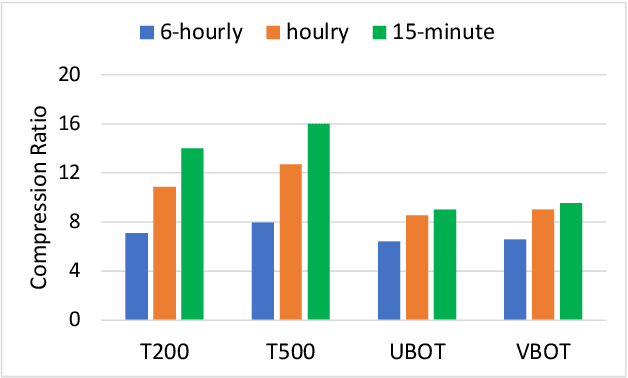
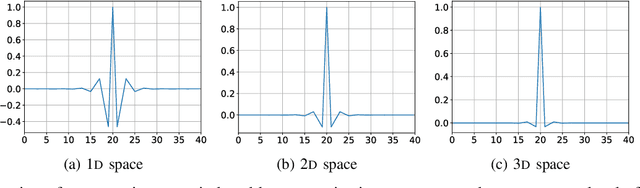
Scientific discoveries are increasingly constrained by limited storage space and I/O capacities. For time-series simulations and experiments, their data often need to be decimated over timesteps to accommodate storage and I/O limitations. In this paper, we propose a technique that addresses storage costs while improving post-analysis accuracy through spatiotemporal adaptive, error-controlled lossy compression. We investigate the trade-off between data precision and temporal output rates, revealing that reducing data precision and increasing timestep frequency lead to more accurate analysis outcomes. Additionally, we integrate spatiotemporal feature detection with data compression and demonstrate that performing adaptive error-bounded compression in higher dimensional space enables greater compression ratios, leveraging the error propagation theory of a transformation-based compressor. To evaluate our approach, we conduct experiments using the well-known E3SM climate simulation code and apply our method to compress variables used for cyclone tracking. Our results show a significant reduction in storage size while enhancing the quality of cyclone tracking analysis, both quantitatively and qualitatively, in comparison to the prevalent timestep decimation approach. Compared to three state-of-the-art lossy compressors lacking feature preservation capabilities, our adaptive compression framework improves perfectly matched cases in TC tracking by 26.4-51.3% at medium compression ratios and by 77.3-571.1% at large compression ratios, with a merely 5-11% computational overhead.
* 10 pages, 13 figures, 2023 IEEE International Conference on e-Science and Grid Computing
High-performance Data Management for Whole Slide Image Analysis in Digital Pathology
Aug 20, 2023When dealing with giga-pixel digital pathology in whole-slide imaging, a notable proportion of data records holds relevance during each analysis operation. For instance, when deploying an image analysis algorithm on whole-slide images (WSI), the computational bottleneck often lies in the input-output (I/O) system. This is particularly notable as patch-level processing introduces a considerable I/O load onto the computer system. However, this data management process could be further paralleled, given the typical independence of patch-level image processes across different patches. This paper details our endeavors in tackling this data access challenge by implementing the Adaptable IO System version 2 (ADIOS2). Our focus has been constructing and releasing a digital pathology-centric pipeline using ADIOS2, which facilitates streamlined data management across WSIs. Additionally, we've developed strategies aimed at curtailing data retrieval times. The performance evaluation encompasses two key scenarios: (1) a pure CPU-based image analysis scenario ("CPU scenario"), and (2) a GPU-based deep learning framework scenario ("GPU scenario"). Our findings reveal noteworthy outcomes. Under the CPU scenario, ADIOS2 showcases an impressive two-fold speed-up compared to the brute-force approach. In the GPU scenario, its performance stands on par with the cutting-edge GPU I/O acceleration framework, NVIDIA Magnum IO GPU Direct Storage (GDS). From what we know, this appears to be among the initial instances, if any, of utilizing ADIOS2 within the field of digital pathology. The source code has been made publicly available at https://github.com/hrlblab/adios.
An Accelerated Pipeline for Multi-label Renal Pathology Image Segmentation at the Whole Slide Image Level
May 23, 2023Deep-learning techniques have been used widely to alleviate the labour-intensive and time-consuming manual annotation required for pixel-level tissue characterization. Our previous study introduced an efficient single dynamic network - Omni-Seg - that achieved multi-class multi-scale pathological segmentation with less computational complexity. However, the patch-wise segmentation paradigm still applies to Omni-Seg, and the pipeline is time-consuming when providing segmentation for Whole Slide Images (WSIs). In this paper, we propose an enhanced version of the Omni-Seg pipeline in order to reduce the repetitive computing processes and utilize a GPU to accelerate the model's prediction for both better model performance and faster speed. Our proposed method's innovative contribution is two-fold: (1) a Docker is released for an end-to-end slide-wise multi-tissue segmentation for WSIs; and (2) the pipeline is deployed on a GPU to accelerate the prediction, achieving better segmentation quality in less time. The proposed accelerated implementation reduced the average processing time (at the testing stage) on a standard needle biopsy WSI from 2.3 hours to 22 minutes, using 35 WSIs from the Kidney Tissue Atlas (KPMP) Datasets. The source code and the Docker have been made publicly available at https://github.com/ddrrnn123/Omni-Seg.