 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMid-infrared laser chaos lidar
Mar 06, 2025



Chaos lidars detect targets through the cross-correlation between the back-scattered chaos signal from the target and the local reference one. Chaos lidars have excellent anti-jamming and anti-interference capabilities, owing to the random nature of chaotic oscillations. However, most chaos lidars operate in the near-infrared spectral regime, where the atmospheric attenuation is significant. Here we show a mid-infrared chaos lidar, which is suitable for long-reach ranging and imaging applications within the low-loss transmission window of the atmosphere. The proof-of-concept mid-infrared chaos lidar utilizes an interband cascade laser with optical feedback as the laser chaos source. Experimental results reveal that the chaos lidar achieves an accuracy better than 0.9 cm and a precision better than 0.3 cm for ranging distances up to 300 cm. In addition, it is found that a minimum signal-to-noise ratio of only 1 dB is required to sustain both sub-cm accuracy and sub-cm precision. This work paves the way for developing remote chaos lidar systems in the mid-infrared spectral regime.
A framework for compressing unstructured scientific data via serialization
Oct 10, 2024We present a general framework for compressing unstructured scientific data with known local connectivity. A common application is simulation data defined on arbitrary finite element meshes. The framework employs a greedy topology preserving reordering of original nodes which allows for seamless integration into existing data processing pipelines. This reordering process depends solely on mesh connectivity and can be performed offline for optimal efficiency. However, the algorithm's greedy nature also supports on-the-fly implementation. The proposed method is compatible with any compression algorithm that leverages spatial correlations within the data. The effectiveness of this approach is demonstrated on a large-scale real dataset using several compression methods, including MGARD, SZ, and ZFP.
Machine Learning Techniques for Data Reduction of Climate Applications
May 01, 2024Scientists conduct large-scale simulations to compute derived quantities-of-interest (QoI) from primary data. Often, QoI are linked to specific features, regions, or time intervals, such that data can be adaptively reduced without compromising the integrity of QoI. For many spatiotemporal applications, these QoI are binary in nature and represent presence or absence of a physical phenomenon. We present a pipelined compression approach that first uses neural-network-based techniques to derive regions where QoI are highly likely to be present. Then, we employ a Guaranteed Autoencoder (GAE) to compress data with differential error bounds. GAE uses QoI information to apply low-error compression to only these regions. This results in overall high compression ratios while still achieving downstream goals of simulation or data collections. Experimental results are presented for climate data generated from the E3SM Simulation model for downstream quantities such as tropical cyclone and atmospheric river detection and tracking. These results show that our approach is superior to comparable methods in the literature.
MGARD: A multigrid framework for high-performance, error-controlled data compression and refactoring
Jan 11, 2024We describe MGARD, a software providing MultiGrid Adaptive Reduction for floating-point scientific data on structured and unstructured grids. With exceptional data compression capability and precise error control, MGARD addresses a wide range of requirements, including storage reduction, high-performance I/O, and in-situ data analysis. It features a unified application programming interface (API) that seamlessly operates across diverse computing architectures. MGARD has been optimized with highly-tuned GPU kernels and efficient memory and device management mechanisms, ensuring scalable and rapid operations.
* 20 pages, 8 figures
Spatiotemporally adaptive compression for scientific dataset with feature preservation -- a case study on simulation data with extreme climate events analysis
Jan 06, 2024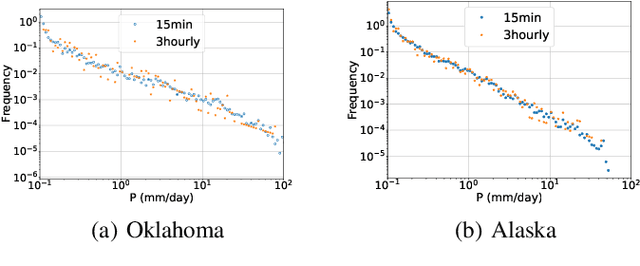
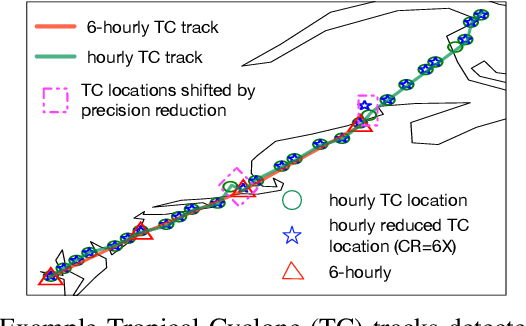
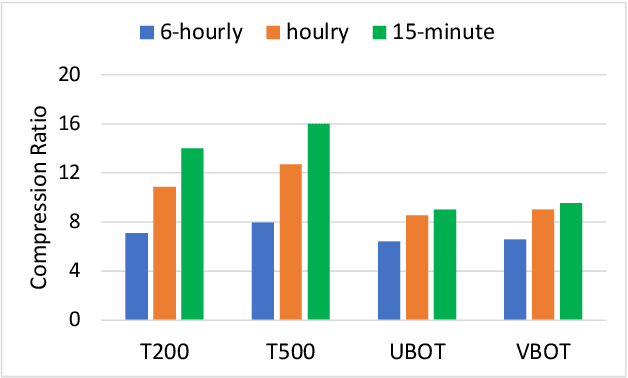
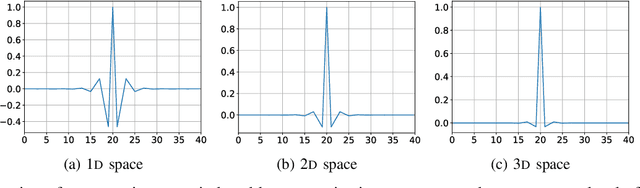
Scientific discoveries are increasingly constrained by limited storage space and I/O capacities. For time-series simulations and experiments, their data often need to be decimated over timesteps to accommodate storage and I/O limitations. In this paper, we propose a technique that addresses storage costs while improving post-analysis accuracy through spatiotemporal adaptive, error-controlled lossy compression. We investigate the trade-off between data precision and temporal output rates, revealing that reducing data precision and increasing timestep frequency lead to more accurate analysis outcomes. Additionally, we integrate spatiotemporal feature detection with data compression and demonstrate that performing adaptive error-bounded compression in higher dimensional space enables greater compression ratios, leveraging the error propagation theory of a transformation-based compressor. To evaluate our approach, we conduct experiments using the well-known E3SM climate simulation code and apply our method to compress variables used for cyclone tracking. Our results show a significant reduction in storage size while enhancing the quality of cyclone tracking analysis, both quantitatively and qualitatively, in comparison to the prevalent timestep decimation approach. Compared to three state-of-the-art lossy compressors lacking feature preservation capabilities, our adaptive compression framework improves perfectly matched cases in TC tracking by 26.4-51.3% at medium compression ratios and by 77.3-571.1% at large compression ratios, with a merely 5-11% computational overhead.
* 10 pages, 13 figures, 2023 IEEE International Conference on e-Science and Grid Computing
Scalable Hybrid Learning Techniques for Scientific Data Compression
Dec 21, 2022



Data compression is becoming critical for storing scientific data because many scientific applications need to store large amounts of data and post process this data for scientific discovery. Unlike image and video compression algorithms that limit errors to primary data, scientists require compression techniques that accurately preserve derived quantities of interest (QoIs). This paper presents a physics-informed compression technique implemented as an end-to-end, scalable, GPU-based pipeline for data compression that addresses this requirement. Our hybrid compression technique combines machine learning techniques and standard compression methods. Specifically, we combine an autoencoder, an error-bounded lossy compressor to provide guarantees on raw data error, and a constraint satisfaction post-processing step to preserve the QoIs within a minimal error (generally less than floating point error). The effectiveness of the data compression pipeline is demonstrated by compressing nuclear fusion simulation data generated by a large-scale fusion code, XGC, which produces hundreds of terabytes of data in a single day. Our approach works within the ADIOS framework and results in compression by a factor of more than 150 while requiring only a few percent of the computational resources necessary for generating the data, making the overall approach highly effective for practical scenarios.
Scale Optimization for Full-Image-CNN Vehicle Detection
Feb 20, 2018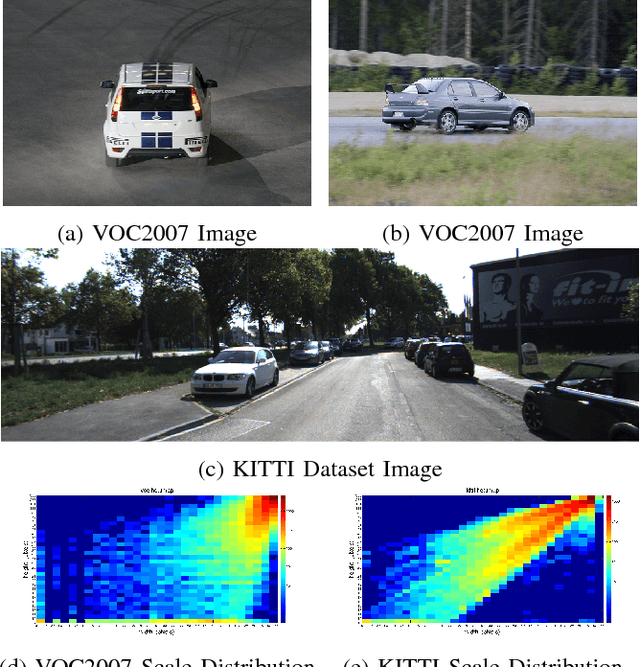

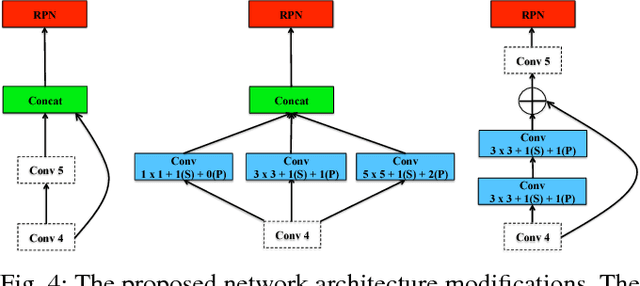

Many state-of-the-art general object detection methods make use of shared full-image convolutional features (as in Faster R-CNN). This achieves a reasonable test-phase computation time while enjoys the discriminative power provided by large Convolutional Neural Network (CNN) models. Such designs excel on benchmarks which contain natural images but which have very unnatural distributions, i.e. they have an unnaturally high-frequency of the target classes and a bias towards a "friendly" or "dominant" object scale. In this paper we present further study of the use and adaptation of the Faster R-CNN object detection method for datasets presenting natural scale distribution and unbiased real-world object frequency. In particular, we show that better alignment of the detector scale sensitivity to the extant distribution improves vehicle detection performance. We do this by modifying both the selection of Region Proposals, and through using more scale-appropriate full-image convolution features within the CNN model. By selecting better scales in the region proposal input and by combining feature maps through careful design of the convolutional neural network, we improve performance on smaller objects. We significantly increase detection AP for the KITTI dataset car class from 76.3% on our baseline Faster R-CNN detector to 83.6% in our improved detector.