 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnactor: From Traffic Simulators to Surrogate World Models
Mar 18, 2026Traffic microsimulators are widely used to evaluate road network performance under various ``what-if" conditions. However, the behavior models controlling the actions of the actors are overly simplistic and fails to capture realistic actor-actor interactions. Deep learning-based methods have been applied to model vehicles and pedestrians as ``agents" responding to their surrounding ``environment" (including lanes, signals, and neighboring agents). Although effective in learning actor-actor interaction, these approaches fail to generate physically consistent trajectories over long time periods, and they do not explicitly address the complex dynamics that arise at traffic intersections which is a critical location in urban networks. Inspired by the World Model paradigm, we have developed an actor centric generative model using transformer-based architecture that is able to capture the actor-actor interaction, at the same time understanding the geometry to the traffic intersection to generate physically grounded trajectories that are based on learned behavior. Moreover, we test the model in a live ``simulation-in-the-loop" setting, where we generate the initial conditions of the actors using SUMO and then let the model control the dynamics of the actors. We let the simulation run for 40000 timesteps (4000 seconds), testing the performance of the model on long timerange and evaluating the trajectories on traffic engineering related metrics. Experimental results demonstrate that the proposed framework effectively captures complex actor-actor interactions and generates long-horizon, physically consistent trajectories, while requiring significantly fewer training samples than traditional agent-centric generative approaches. Our model is able to outperform the baseline in traffic related as well as aggregate metrics where our model beats the baseline by more than 10x on the KL-Divergence.
Generative Latent Diffusion for Efficient Spatiotemporal Data Reduction
Jul 02, 2025Generative models have demonstrated strong performance in conditional settings and can be viewed as a form of data compression, where the condition serves as a compact representation. However, their limited controllability and reconstruction accuracy restrict their practical application to data compression. In this work, we propose an efficient latent diffusion framework that bridges this gap by combining a variational autoencoder with a conditional diffusion model. Our method compresses only a small number of keyframes into latent space and uses them as conditioning inputs to reconstruct the remaining frames via generative interpolation, eliminating the need to store latent representations for every frame. This approach enables accurate spatiotemporal reconstruction while significantly reducing storage costs. Experimental results across multiple datasets show that our method achieves up to 10 times higher compression ratios than rule-based state-of-the-art compressors such as SZ3, and up to 63 percent better performance than leading learning-based methods under the same reconstruction error.
Evaluating Generative Vehicle Trajectory Models for Traffic Intersection Dynamics
Jun 10, 2025Traffic Intersections are vital to urban road networks as they regulate the movement of people and goods. However, they are regions of conflicting trajectories and are prone to accidents. Deep Generative models of traffic dynamics at signalized intersections can greatly help traffic authorities better understand the efficiency and safety aspects. At present, models are evaluated on computational metrics that primarily look at trajectory reconstruction errors. They are not evaluated online in a `live' microsimulation scenario. Further, these metrics do not adequately consider traffic engineering-specific concerns such as red-light violations, unallowed stoppage, etc. In this work, we provide a comprehensive analytics tool to train, run, and evaluate models with metrics that give better insights into model performance from a traffic engineering point of view. We train a state-of-the-art multi-vehicle trajectory forecasting model on a large dataset collected by running a calibrated scenario of a real-world urban intersection. We then evaluate the performance of the prediction models, online in a microsimulator, under unseen traffic conditions. We show that despite using ideally-behaved trajectories as input, and achieving low trajectory reconstruction errors, the generated trajectories show behaviors that break traffic rules. We introduce new metrics to evaluate such undesired behaviors and present our results.
IntTrajSim: Trajectory Prediction for Simulating Multi-Vehicle driving at Signalized Intersections
Jun 10, 2025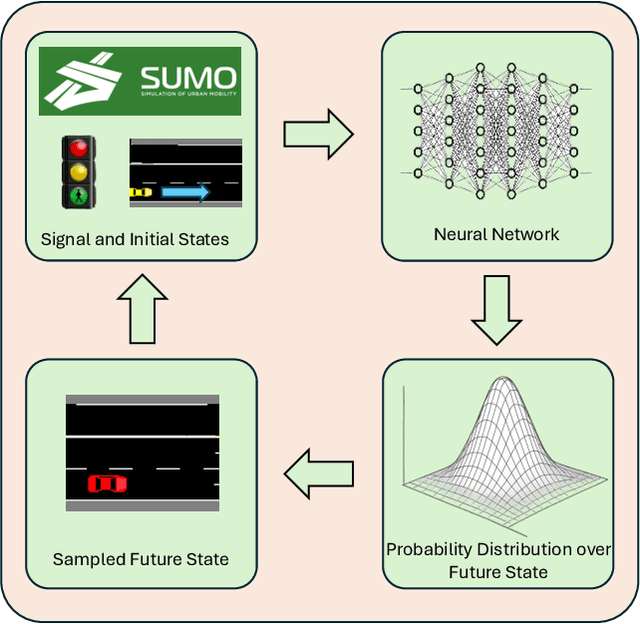
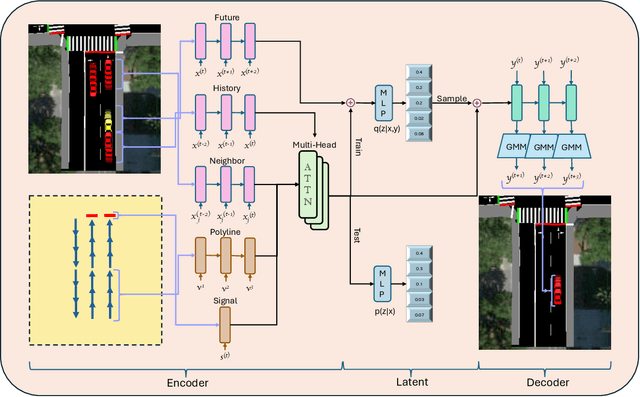
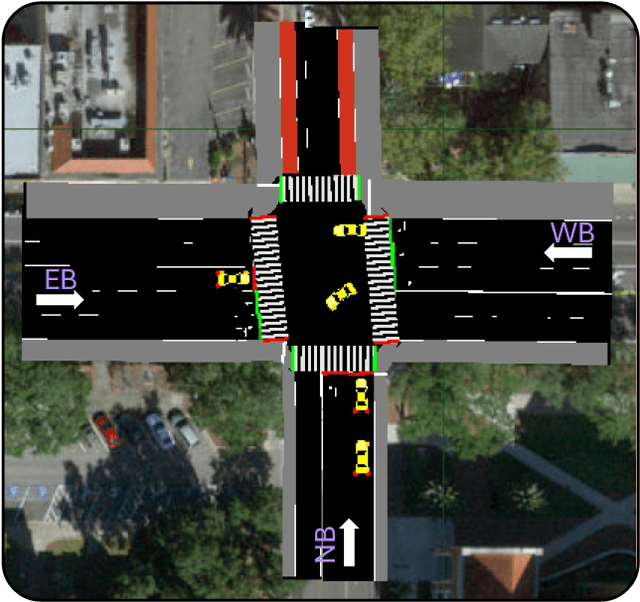
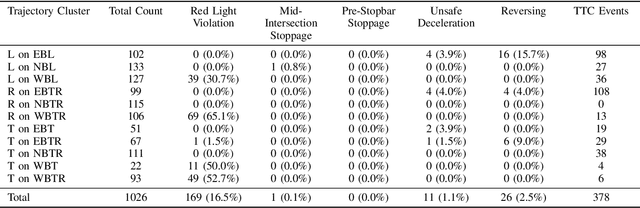
Traffic simulators are widely used to study the operational efficiency of road infrastructure, but their rule-based approach limits their ability to mimic real-world driving behavior. Traffic intersections are critical components of the road infrastructure, both in terms of safety risk (nearly 28% of fatal crashes and 58% of nonfatal crashes happen at intersections) as well as the operational efficiency of a road corridor. This raises an important question: can we create a data-driven simulator that can mimic the macro- and micro-statistics of the driving behavior at a traffic intersection? Deep Generative Modeling-based trajectory prediction models provide a good starting point to model the complex dynamics of vehicles at an intersection. But they are not tested in a "live" micro-simulation scenario and are not evaluated on traffic engineering-related metrics. In this study, we propose traffic engineering-related metrics to evaluate generative trajectory prediction models and provide a simulation-in-the-loop pipeline to do so. We also provide a multi-headed self-attention-based trajectory prediction model that incorporates the signal information, which outperforms our previous models on the evaluation metrics.
Guaranteed Conditional Diffusion: 3D Block-based Models for Scientific Data Compression
Feb 18, 2025This paper proposes a new compression paradigm -- Guaranteed Conditional Diffusion with Tensor Correction (GCDTC) -- for lossy scientific data compression. The framework is based on recent conditional diffusion (CD) generative models, and it consists of a conditional diffusion model, tensor correction, and error guarantee. Our diffusion model is a mixture of 3D conditioning and 2D denoising U-Net. The approach leverages a 3D block-based compressing module to address spatiotemporal correlations in structured scientific data. Then, the reverse diffusion process for 2D spatial data is conditioned on the ``slices'' of content latent variables produced by the compressing module. After training, the denoising decoder reconstructs the data with zero noise and content latent variables, and thus it is entirely deterministic. The reconstructed outputs of the CD model are further post-processed by our tensor correction and error guarantee steps to control and ensure a maximum error distortion, which is an inevitable requirement in lossy scientific data compression. Our experiments involving two datasets generated by climate and chemical combustion simulations show that our framework outperforms standard convolutional autoencoders and yields competitive compression quality with an existing scientific data compression algorithm.
Foundation Model for Lossy Compression of Spatiotemporal Scientific Data
Dec 22, 2024We present a foundation model (FM) for lossy scientific data compression, combining a variational autoencoder (VAE) with a hyper-prior structure and a super-resolution (SR) module. The VAE framework uses hyper-priors to model latent space dependencies, enhancing compression efficiency. The SR module refines low-resolution representations into high-resolution outputs, improving reconstruction quality. By alternating between 2D and 3D convolutions, the model efficiently captures spatiotemporal correlations in scientific data while maintaining low computational cost. Experimental results demonstrate that the FM generalizes well to unseen domains and varying data shapes, achieving up to 4 times higher compression ratios than state-of-the-art methods after domain-specific fine-tuning. The SR module improves compression ratio by 30 percent compared to simple upsampling techniques. This approach significantly reduces storage and transmission costs for large-scale scientific simulations while preserving data integrity and fidelity.
Attention Based Machine Learning Methods for Data Reduction with Guaranteed Error Bounds
Sep 09, 2024Scientific applications in fields such as high energy physics, computational fluid dynamics, and climate science generate vast amounts of data at high velocities. This exponential growth in data production is surpassing the advancements in computing power, network capabilities, and storage capacities. To address this challenge, data compression or reduction techniques are crucial. These scientific datasets have underlying data structures that consist of structured and block structured multidimensional meshes where each grid point corresponds to a tensor. It is important that data reduction techniques leverage strong spatial and temporal correlations that are ubiquitous in these applications. Additionally, applications such as CFD, process tensors comprising hundred plus species and their attributes at each grid point. Reduction techniques should be able to leverage interrelationships between the elements in each tensor. In this paper, we propose an attention-based hierarchical compression method utilizing a block-wise compression setup. We introduce an attention-based hyper-block autoencoder to capture inter-block correlations, followed by a block-wise encoder to capture block-specific information. A PCA-based post-processing step is employed to guarantee error bounds for each data block. Our method effectively captures both spatiotemporal and inter-variable correlations within and between data blocks. Compared to the state-of-the-art SZ3, our method achieves up to 8 times higher compression ratio on the multi-variable S3D dataset. When evaluated on single-variable setups using the E3SM and XGC datasets, our method still achieves up to 3 times and 2 times higher compression ratio, respectively.
Video-based Pedestrian and Vehicle Traffic Analysis During Football Games
Aug 04, 2024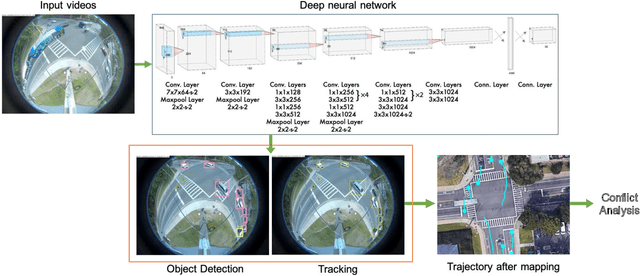

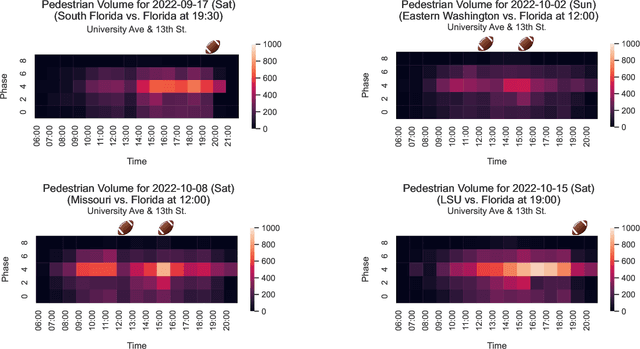
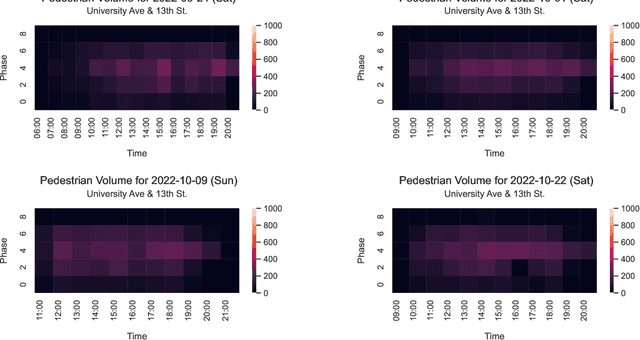
This paper utilizes video analytics to study pedestrian and vehicle traffic behavior, focusing on analyzing traffic patterns during football gamedays. The University of Florida (UF) hosts six to seven home football games on Saturdays during the college football season, attracting significant pedestrian activity. Through video analytics, this study provides valuable insights into the impact of these events on traffic volumes and safety at intersections. Comparing pedestrian and vehicle activities on gamedays versus non-gamedays reveals differing patterns. For example, pedestrian volume substantially increases during gamedays, which is positively correlated with the probability of the away team winning. This correlation is likely because fans of the home team enjoy watching difficult games. Win probabilities as an early predictor of pedestrian volumes at intersections can be a tool to help traffic professionals anticipate traffic management needs. Pedestrian-to-vehicle (P2V) conflicts notably increase on gamedays, particularly a few hours before games start. Addressing this, a "Barnes Dance" movement phase within the intersection is recommended. Law enforcement presence during high-activity gamedays can help ensure pedestrian compliance and enhance safety. In contrast, we identified that vehicle-to-vehicle (V2V) conflicts generally do not increase on gamedays and may even decrease due to heightened driver caution.
MTDT: A Multi-Task Deep Learning Digital Twin
May 02, 2024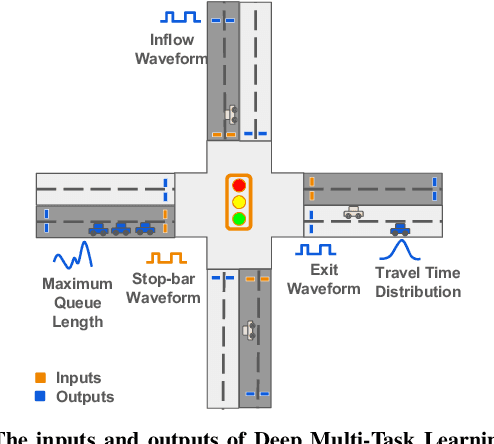

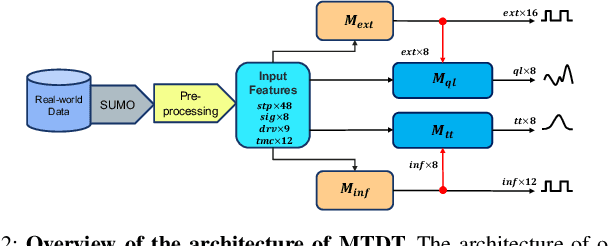

Traffic congestion has significant impacts on both the economy and the environment. Measures of Effectiveness (MOEs) have long been the standard for evaluating the level of service and operational efficiency of traffic intersections. However, the scarcity of traditional high-resolution loop detector data (ATSPM) presents challenges in accurately measuring MOEs or capturing the intricate temporospatial characteristics inherent in urban intersection traffic. In response to this challenge, we have introduced the Multi-Task Deep Learning Digital Twin (MTDT) as a solution for multifaceted and precise intersection traffic flow simulation. MTDT enables accurate, fine-grained estimation of loop detector waveform time series for each lane of movement, alongside successful estimation of several MOEs for each lane group associated with a traffic phase concurrently and for all approaches of an arbitrary urban intersection. Unlike existing deep learning methodologies, MTDT distinguishes itself through its adaptability to local temporal and spatial features, such as signal timing plans, intersection topology, driving behaviors, and turning movement counts. While maintaining a straightforward design, our model emphasizes the advantages of multi-task learning in traffic modeling. By consolidating the learning process across multiple tasks, MTDT demonstrates reduced overfitting, increased efficiency, and enhanced effectiveness by sharing representations learned by different tasks. Furthermore, our approach facilitates sequential computation and lends itself to complete parallelization through GPU implementation. This not only streamlines the computational process but also enhances scalability and performance.
Machine Learning Techniques for Data Reduction of Climate Applications
May 01, 2024Scientists conduct large-scale simulations to compute derived quantities-of-interest (QoI) from primary data. Often, QoI are linked to specific features, regions, or time intervals, such that data can be adaptively reduced without compromising the integrity of QoI. For many spatiotemporal applications, these QoI are binary in nature and represent presence or absence of a physical phenomenon. We present a pipelined compression approach that first uses neural-network-based techniques to derive regions where QoI are highly likely to be present. Then, we employ a Guaranteed Autoencoder (GAE) to compress data with differential error bounds. GAE uses QoI information to apply low-error compression to only these regions. This results in overall high compression ratios while still achieving downstream goals of simulation or data collections. Experimental results are presented for climate data generated from the E3SM Simulation model for downstream quantities such as tropical cyclone and atmospheric river detection and tracking. These results show that our approach is superior to comparable methods in the literature.