 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards an Introspective Dynamic Model of Globally Distributed Computing Infrastructures
Jun 24, 2025Large-scale scientific collaborations like ATLAS, Belle II, CMS, DUNE, and others involve hundreds of research institutes and thousands of researchers spread across the globe. These experiments generate petabytes of data, with volumes soon expected to reach exabytes. Consequently, there is a growing need for computation, including structured data processing from raw data to consumer-ready derived data, extensive Monte Carlo simulation campaigns, and a wide range of end-user analysis. To manage these computational and storage demands, centralized workflow and data management systems are implemented. However, decisions regarding data placement and payload allocation are often made disjointly and via heuristic means. A significant obstacle in adopting more effective heuristic or AI-driven solutions is the absence of a quick and reliable introspective dynamic model to evaluate and refine alternative approaches. In this study, we aim to develop such an interactive system using real-world data. By examining job execution records from the PanDA workflow management system, we have pinpointed key performance indicators such as queuing time, error rate, and the extent of remote data access. The dataset includes five months of activity. Additionally, we are creating a generative AI model to simulate time series of payloads, which incorporate visible features like category, event count, and submitting group, as well as hidden features like the total computational load-derived from existing PanDA records and computing site capabilities. These hidden features, which are not visible to job allocators, whether heuristic or AI-driven, influence factors such as queuing times and data movement.
The Artificial Scientist -- in-transit Machine Learning of Plasma Simulations
Jan 06, 2025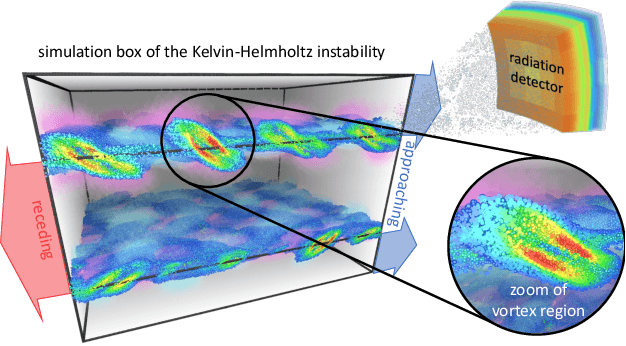
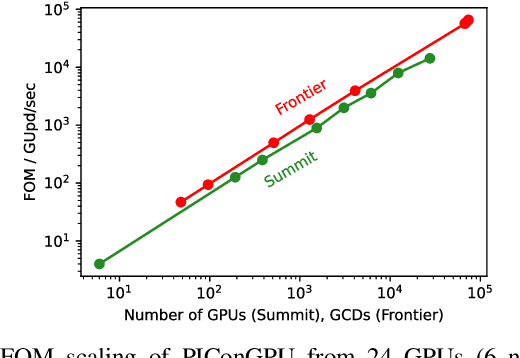
Increasing HPC cluster sizes and large-scale simulations that produce petabytes of data per run, create massive IO and storage challenges for analysis. Deep learning-based techniques, in particular, make use of these amounts of domain data to extract patterns that help build scientific understanding. Here, we demonstrate a streaming workflow in which simulation data is streamed directly to a machine-learning (ML) framework, circumventing the file system bottleneck. Data is transformed in transit, asynchronously to the simulation and the training of the model. With the presented workflow, data operations can be performed in common and easy-to-use programming languages, freeing the application user from adapting the application output routines. As a proof-of-concept we consider a GPU accelerated particle-in-cell (PIConGPU) simulation of the Kelvin- Helmholtz instability (KHI). We employ experience replay to avoid catastrophic forgetting in learning from this non-steady process in a continual manner. We detail challenges addressed while porting and scaling to Frontier exascale system.
A framework for compressing unstructured scientific data via serialization
Oct 10, 2024We present a general framework for compressing unstructured scientific data with known local connectivity. A common application is simulation data defined on arbitrary finite element meshes. The framework employs a greedy topology preserving reordering of original nodes which allows for seamless integration into existing data processing pipelines. This reordering process depends solely on mesh connectivity and can be performed offline for optimal efficiency. However, the algorithm's greedy nature also supports on-the-fly implementation. The proposed method is compatible with any compression algorithm that leverages spatial correlations within the data. The effectiveness of this approach is demonstrated on a large-scale real dataset using several compression methods, including MGARD, SZ, and ZFP.
MGARD: A multigrid framework for high-performance, error-controlled data compression and refactoring
Jan 11, 2024We describe MGARD, a software providing MultiGrid Adaptive Reduction for floating-point scientific data on structured and unstructured grids. With exceptional data compression capability and precise error control, MGARD addresses a wide range of requirements, including storage reduction, high-performance I/O, and in-situ data analysis. It features a unified application programming interface (API) that seamlessly operates across diverse computing architectures. MGARD has been optimized with highly-tuned GPU kernels and efficient memory and device management mechanisms, ensuring scalable and rapid operations.
* 20 pages, 8 figures
Spatiotemporally adaptive compression for scientific dataset with feature preservation -- a case study on simulation data with extreme climate events analysis
Jan 06, 2024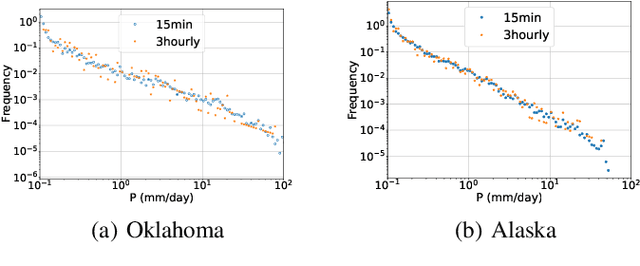
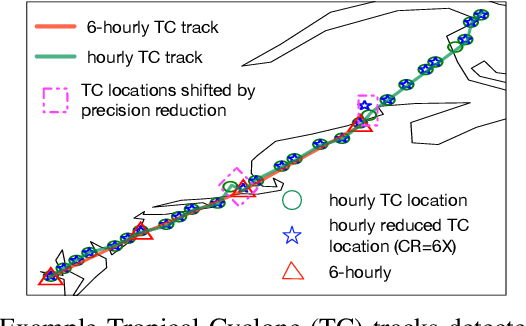
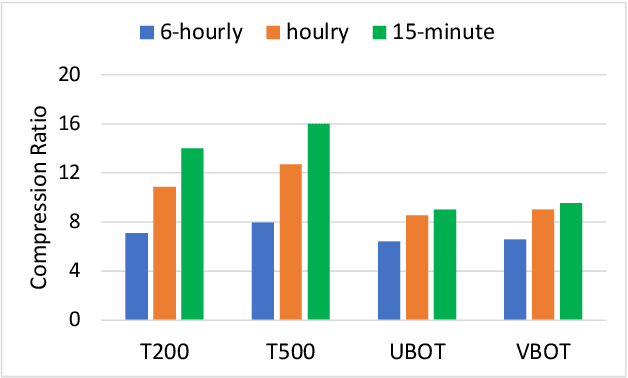
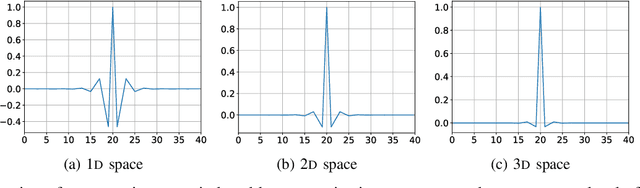
Scientific discoveries are increasingly constrained by limited storage space and I/O capacities. For time-series simulations and experiments, their data often need to be decimated over timesteps to accommodate storage and I/O limitations. In this paper, we propose a technique that addresses storage costs while improving post-analysis accuracy through spatiotemporal adaptive, error-controlled lossy compression. We investigate the trade-off between data precision and temporal output rates, revealing that reducing data precision and increasing timestep frequency lead to more accurate analysis outcomes. Additionally, we integrate spatiotemporal feature detection with data compression and demonstrate that performing adaptive error-bounded compression in higher dimensional space enables greater compression ratios, leveraging the error propagation theory of a transformation-based compressor. To evaluate our approach, we conduct experiments using the well-known E3SM climate simulation code and apply our method to compress variables used for cyclone tracking. Our results show a significant reduction in storage size while enhancing the quality of cyclone tracking analysis, both quantitatively and qualitatively, in comparison to the prevalent timestep decimation approach. Compared to three state-of-the-art lossy compressors lacking feature preservation capabilities, our adaptive compression framework improves perfectly matched cases in TC tracking by 26.4-51.3% at medium compression ratios and by 77.3-571.1% at large compression ratios, with a merely 5-11% computational overhead.
* 10 pages, 13 figures, 2023 IEEE International Conference on e-Science and Grid Computing