 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLight-Weight Fault Tolerant Attention for Large Language Model Training
Oct 15, 2024



Large Language Models (LLMs) have demonstrated remarkable performance in various natural language processing tasks. However, the training of these models is computationally intensive and susceptible to faults, particularly in the attention mechanism, which is a critical component of transformer-based LLMs. In this paper, we investigate the impact of faults on LLM training, focusing on INF, NaN, and near-INF values in the computation results with systematic fault injection experiments. We observe the propagation patterns of these errors, which can trigger non-trainable states in the model and disrupt training, forcing the procedure to load from checkpoints.To mitigate the impact of these faults, we propose ATTNChecker, the first Algorithm-Based Fault Tolerance (ABFT) technique tailored for the attention mechanism in LLMs. ATTNChecker is designed based on fault propagation patterns of LLM and incorporates performance optimization to adapt to both system reliability and model vulnerability while providing lightweight protection for fast LLM training. Evaluations on four LLMs show that ATTNChecker on average incurs on average 7% overhead on training while detecting and correcting all extreme errors. Compared with the state-of-the-art checkpoint/restore approach, ATTNChecker reduces recovery overhead by up to 49x.
MGARD: A multigrid framework for high-performance, error-controlled data compression and refactoring
Jan 11, 2024We describe MGARD, a software providing MultiGrid Adaptive Reduction for floating-point scientific data on structured and unstructured grids. With exceptional data compression capability and precise error control, MGARD addresses a wide range of requirements, including storage reduction, high-performance I/O, and in-situ data analysis. It features a unified application programming interface (API) that seamlessly operates across diverse computing architectures. MGARD has been optimized with highly-tuned GPU kernels and efficient memory and device management mechanisms, ensuring scalable and rapid operations.
* 20 pages, 8 figures
Spatiotemporally adaptive compression for scientific dataset with feature preservation -- a case study on simulation data with extreme climate events analysis
Jan 06, 2024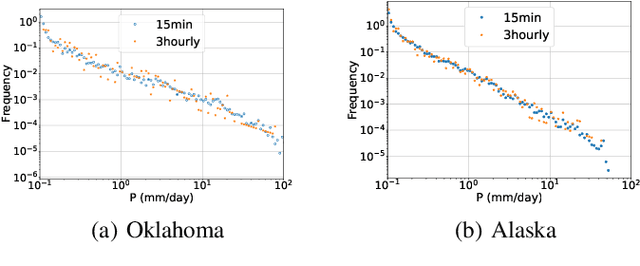
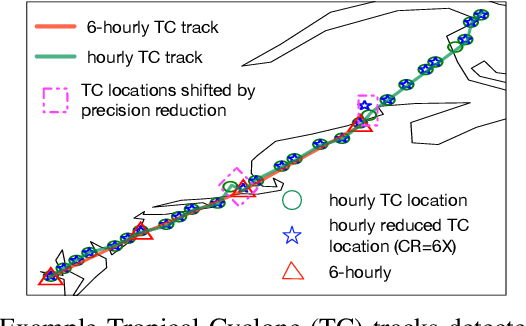
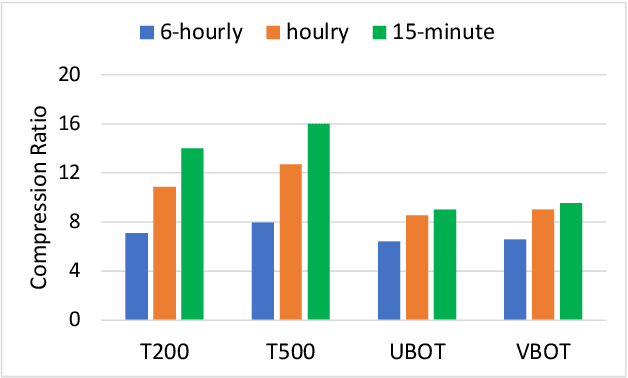
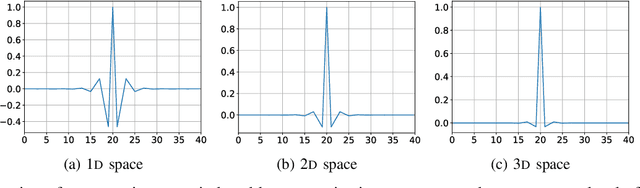
Scientific discoveries are increasingly constrained by limited storage space and I/O capacities. For time-series simulations and experiments, their data often need to be decimated over timesteps to accommodate storage and I/O limitations. In this paper, we propose a technique that addresses storage costs while improving post-analysis accuracy through spatiotemporal adaptive, error-controlled lossy compression. We investigate the trade-off between data precision and temporal output rates, revealing that reducing data precision and increasing timestep frequency lead to more accurate analysis outcomes. Additionally, we integrate spatiotemporal feature detection with data compression and demonstrate that performing adaptive error-bounded compression in higher dimensional space enables greater compression ratios, leveraging the error propagation theory of a transformation-based compressor. To evaluate our approach, we conduct experiments using the well-known E3SM climate simulation code and apply our method to compress variables used for cyclone tracking. Our results show a significant reduction in storage size while enhancing the quality of cyclone tracking analysis, both quantitatively and qualitatively, in comparison to the prevalent timestep decimation approach. Compared to three state-of-the-art lossy compressors lacking feature preservation capabilities, our adaptive compression framework improves perfectly matched cases in TC tracking by 26.4-51.3% at medium compression ratios and by 77.3-571.1% at large compression ratios, with a merely 5-11% computational overhead.
* 10 pages, 13 figures, 2023 IEEE International Conference on e-Science and Grid Computing
Scalable Hybrid Learning Techniques for Scientific Data Compression
Dec 21, 2022



Data compression is becoming critical for storing scientific data because many scientific applications need to store large amounts of data and post process this data for scientific discovery. Unlike image and video compression algorithms that limit errors to primary data, scientists require compression techniques that accurately preserve derived quantities of interest (QoIs). This paper presents a physics-informed compression technique implemented as an end-to-end, scalable, GPU-based pipeline for data compression that addresses this requirement. Our hybrid compression technique combines machine learning techniques and standard compression methods. Specifically, we combine an autoencoder, an error-bounded lossy compressor to provide guarantees on raw data error, and a constraint satisfaction post-processing step to preserve the QoIs within a minimal error (generally less than floating point error). The effectiveness of the data compression pipeline is demonstrated by compressing nuclear fusion simulation data generated by a large-scale fusion code, XGC, which produces hundreds of terabytes of data in a single day. Our approach works within the ADIOS framework and results in compression by a factor of more than 150 while requiring only a few percent of the computational resources necessary for generating the data, making the overall approach highly effective for practical scenarios.
FTRANS: Energy-Efficient Acceleration of Transformers using FPGA
Jul 16, 2020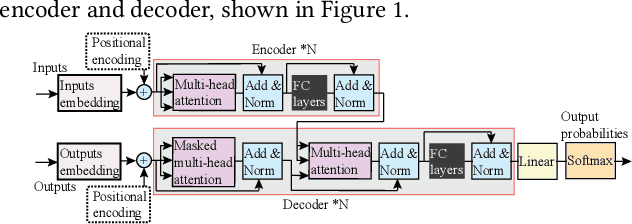

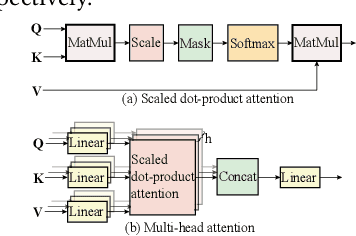
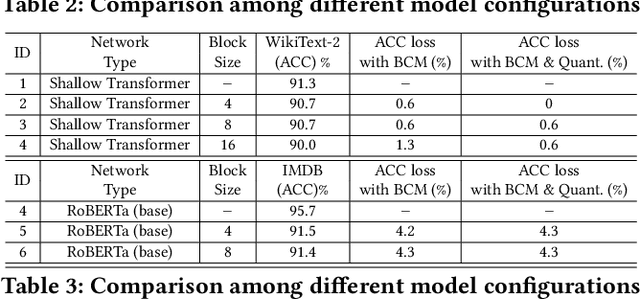
In natural language processing (NLP), the "Transformer" architecture was proposed as the first transduction model replying entirely on self-attention mechanisms without using sequence-aligned recurrent neural networks (RNNs) or convolution, and it achieved significant improvements for sequence to sequence tasks. The introduced intensive computation and storage of these pre-trained language representations has impeded their popularity into computation and memory-constrained devices. The field-programmable gate array (FPGA) is widely used to accelerate deep learning algorithms for its high parallelism and low latency. However, the trained models are still too large to accommodate to an FPGA fabric. In this paper, we propose an efficient acceleration framework, Ftrans, for transformer-based large scale language representations. Our framework includes enhanced block-circulant matrix (BCM)-based weight representation to enable model compression on large-scale language representations at the algorithm level with few accuracy degradation, and an acceleration design at the architecture level. Experimental results show that our proposed framework significantly reduces the model size of NLP models by up to 16 times. Our FPGA design achieves 27.07x and 81x improvement in performance and energy efficiency compared to CPU, and up to 8.80x improvement in energy efficiency compared to GPU.
Algorithm-Based Fault Tolerance for Convolutional Neural Networks
Mar 27, 2020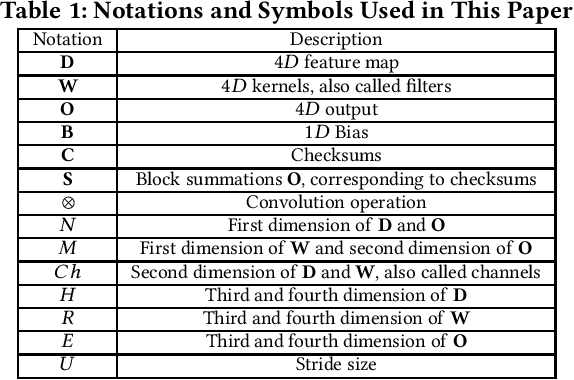
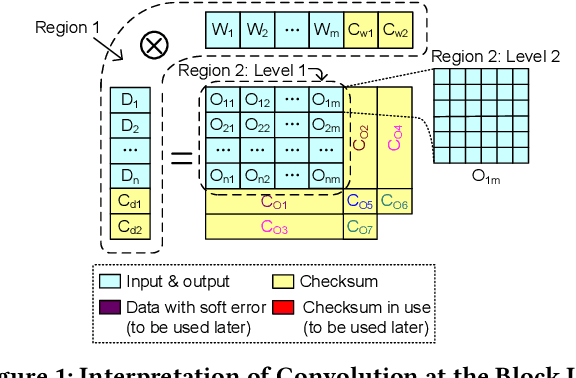
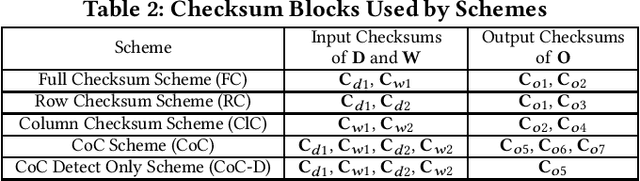
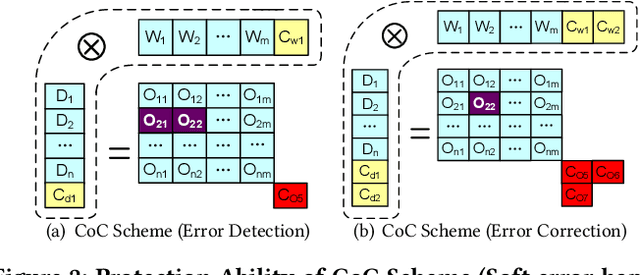
Convolutional neural networks (CNNs) are becoming more and more important for solving challenging and critical problems in many fields. CNN inference applications have been deployed in safety-critical systems, which may suffer from soft errors caused by high-energy particles, high temperature, or abnormal voltage. Of critical importance is ensuring the stability of the CNN inference process against soft errors. Traditional fault tolerance methods are not suitable for CNN inference because error-correcting code is unable to protect computational components, instruction duplication techniques incur high overhead, and existing algorithm-based fault tolerance (ABFT) schemes cannot protect all convolution implementations. In this paper, we focus on how to protect the CNN inference process against soft errors as efficiently as possible, with the following three contributions. (1) We propose several systematic ABFT schemes based on checksum techniques and analyze their pros and cons thoroughly. Unlike traditional ABFT based on matrix-matrix multiplication, our schemes support any convolution implementations. (2) We design a novel workflow integrating all the proposed schemes to obtain a high detection/correction ability with limited total runtime overhead. (3) We perform our evaluation using ImageNet with well-known CNN models including AlexNet, VGG-19, ResNet-18, and YOLOv2. Experimental results demonstrate that our implementation can handle soft errors with very limited runtime overhead (4%~8% in both error-free and error-injected situations).