 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfantAgent-Next: A Multimodal Generalist Agent for Automated Computer Interaction
May 16, 2025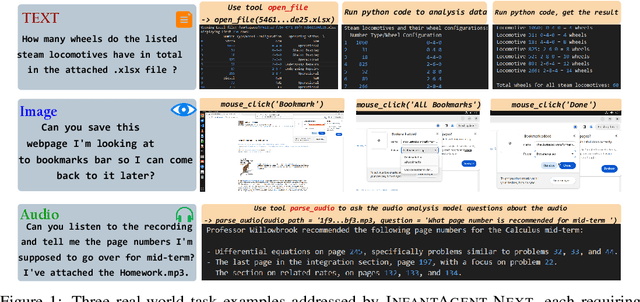

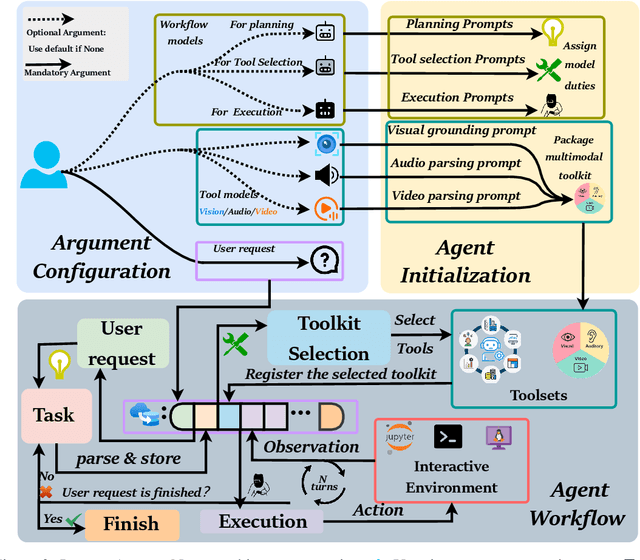
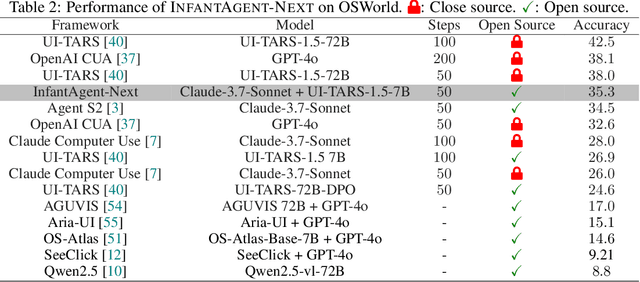
This paper introduces \textsc{InfantAgent-Next}, a generalist agent capable of interacting with computers in a multimodal manner, encompassing text, images, audio, and video. Unlike existing approaches that either build intricate workflows around a single large model or only provide workflow modularity, our agent integrates tool-based and pure vision agents within a highly modular architecture, enabling different models to collaboratively solve decoupled tasks in a step-by-step manner. Our generality is demonstrated by our ability to evaluate not only pure vision-based real-world benchmarks (i.e., OSWorld), but also more general or tool-intensive benchmarks (e.g., GAIA and SWE-Bench). Specifically, we achieve $\mathbf{7.27\%}$ accuracy on OSWorld, higher than Claude-Computer-Use. Codes and evaluation scripts are open-sourced at https://github.com/bin123apple/InfantAgent.
CipherPrune: Efficient and Scalable Private Transformer Inference
Feb 24, 2025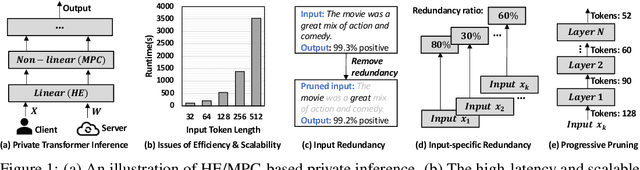
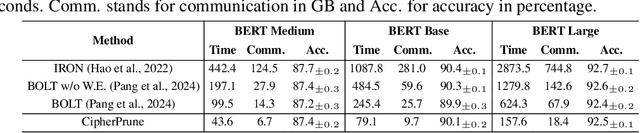
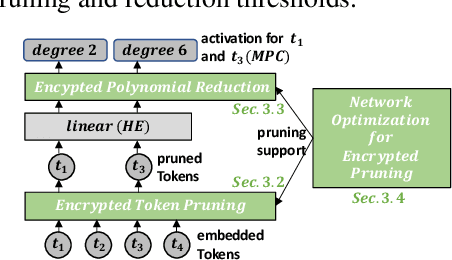
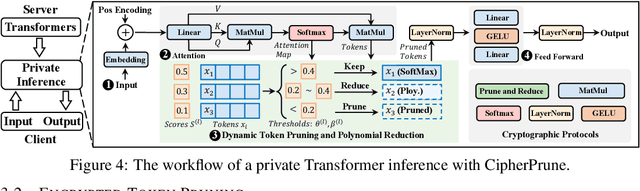
Private Transformer inference using cryptographic protocols offers promising solutions for privacy-preserving machine learning; however, it still faces significant runtime overhead (efficiency issues) and challenges in handling long-token inputs (scalability issues). We observe that the Transformer's operational complexity scales quadratically with the number of input tokens, making it essential to reduce the input token length. Notably, each token varies in importance, and many inputs contain redundant tokens. Additionally, prior private inference methods that rely on high-degree polynomial approximations for non-linear activations are computationally expensive. Therefore, reducing the polynomial degree for less important tokens can significantly accelerate private inference. Building on these observations, we propose \textit{CipherPrune}, an efficient and scalable private inference framework that includes a secure encrypted token pruning protocol, a polynomial reduction protocol, and corresponding Transformer network optimizations. At the protocol level, encrypted token pruning adaptively removes unimportant tokens from encrypted inputs in a progressive, layer-wise manner. Additionally, encrypted polynomial reduction assigns lower-degree polynomials to less important tokens after pruning, enhancing efficiency without decryption. At the network level, we introduce protocol-aware network optimization via a gradient-based search to maximize pruning thresholds and polynomial reduction conditions while maintaining the desired accuracy. Our experiments demonstrate that CipherPrune reduces the execution overhead of private Transformer inference by approximately $6.1\times$ for 128-token inputs and $10.6\times$ for 512-token inputs, compared to previous methods, with only a marginal drop in accuracy. The code is publicly available at https://github.com/UCF-Lou-Lab-PET/cipher-prune-inference.
Efficient and Direct Inference of Heart Rate Variability using Both Signal Processing and Machine Learning
Mar 23, 2023



Heart Rate Variability (HRV) measures the variation of the time between consecutive heartbeats and is a major indicator of physical and mental health. Recent research has demonstrated that photoplethysmography (PPG) sensors can be used to infer HRV. However, many prior studies had high errors because they only employed signal processing or machine learning (ML), or because they indirectly inferred HRV, or because there lacks large training datasets. Many prior studies may also require large ML models. The low accuracy and large model sizes limit their applications to small embedded devices and potential future use in healthcare. To address the above issues, we first collected a large dataset of PPG signals and HRV ground truth. With this dataset, we developed HRV models that combine signal processing and ML to directly infer HRV. Evaluation results show that our method had errors between 3.5% to 25.7% and outperformed signal-processing-only and ML-only methods. We also explored different ML models, which showed that Decision Trees and Multi-level Perceptrons have 13.0% and 9.1% errors on average with models at most hundreds of KB and inference time less than 1ms. Hence, they are more suitable for small embedded devices and potentially enable the future use of PPG-based HRV monitoring in healthcare.
PPG-based Heart Rate Estimation with Efficient Sensor Sampling and Learning Models
Mar 23, 2023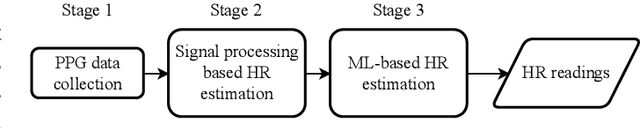



Recent studies showed that Photoplethysmography (PPG) sensors embedded in wearable devices can estimate heart rate (HR) with high accuracy. However, despite of prior research efforts, applying PPG sensor based HR estimation to embedded devices still faces challenges due to the energy-intensive high-frequency PPG sampling and the resource-intensive machine-learning models. In this work, we aim to explore HR estimation techniques that are more suitable for lower-power and resource-constrained embedded devices. More specifically, we seek to design techniques that could provide high-accuracy HR estimation with low-frequency PPG sampling, small model size, and fast inference time. First, we show that by combining signal processing and ML, it is possible to reduce the PPG sampling frequency from 125 Hz to only 25 Hz while providing higher HR estimation accuracy. This combination also helps to reduce the ML model feature size, leading to smaller models. Additionally, we present a comprehensive analysis on different ML models and feature sizes to compare their accuracy, model size, and inference time. The models explored include Decision Tree (DT), Random Forest (RF), K-nearest neighbor (KNN), Support vector machines (SVM), and Multi-layer perceptron (MLP). Experiments were conducted using both a widely-utilized dataset and our self-collected dataset. The experimental results show that our method by combining signal processing and ML had only 5% error for HR estimation using low-frequency PPG data. Moreover, our analysis showed that DT models with 10 to 20 input features usually have good accuracy, while are several magnitude smaller in model sizes and faster in inference time.
Dynamic Sparse Training via More Exploration
Dec 14, 2022



Over-parameterization of deep neural networks (DNNs) has shown high prediction accuracy for many applications. Although effective, the large number of parameters hinders its popularity on resource-limited devices and has an outsize environmental impact. Sparse training (using a fixed number of nonzero weights in each iteration) could significantly mitigate the training costs by reducing the model size. However, existing sparse training methods mainly use either random-based or greedy-based drop-and-grow strategies, resulting in local minimal and low accuracy. In this work, we consider the dynamic sparse training as a sparse connectivity search problem and design an exploitation and exploration acquisition function to escape from local optima and saddle points. We further design an acquisition function and provide the theoretical guarantees for the proposed method and clarify its convergence property. Experimental results show that sparse models (up to 98\% sparsity) obtained by our proposed method outperform the SOTA sparse training methods on a wide variety of deep learning tasks. On VGG-19 / CIFAR-100, ResNet-50 / CIFAR-10, ResNet-50 / CIFAR-100, our method has even higher accuracy than dense models. On ResNet-50 / ImageNet, the proposed method has up to 8.2\% accuracy improvement compared to SOTA sparse training methods.
EVE: Environmental Adaptive Neural Network Models for Low-power Energy Harvesting System
Jul 14, 2022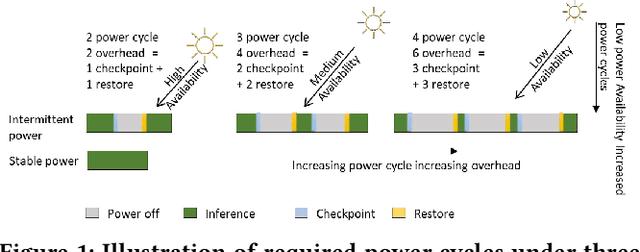
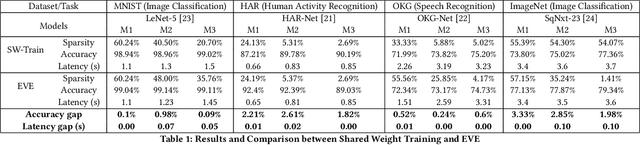
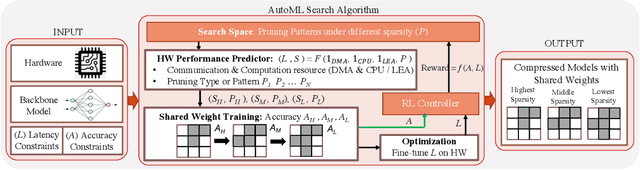
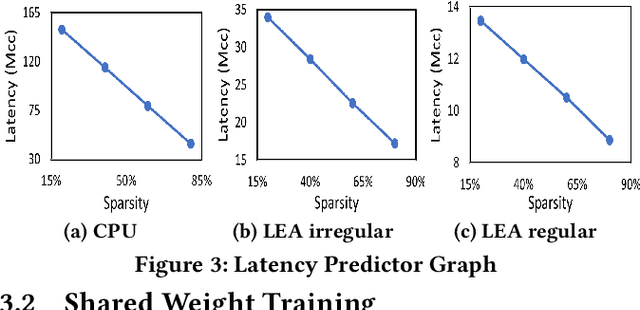
IoT devices are increasingly being implemented with neural network models to enable smart applications. Energy harvesting (EH) technology that harvests energy from ambient environment is a promising alternative to batteries for powering those devices due to the low maintenance cost and wide availability of the energy sources. However, the power provided by the energy harvester is low and has an intrinsic drawback of instability since it varies with the ambient environment. This paper proposes EVE, an automated machine learning (autoML) co-exploration framework to search for desired multi-models with shared weights for energy harvesting IoT devices. Those shared models incur significantly reduced memory footprint with different levels of model sparsity, latency, and accuracy to adapt to the environmental changes. An efficient on-device implementation architecture is further developed to efficiently execute each model on device. A run-time model extraction algorithm is proposed that retrieves individual model with negligible overhead when a specific model mode is triggered. Experimental results show that the neural networks models generated by EVE is on average 2.5X times faster than the baseline models without pruning and shared weights.
An Automatic and Efficient BERT Pruning for Edge AI Systems
Jun 21, 2022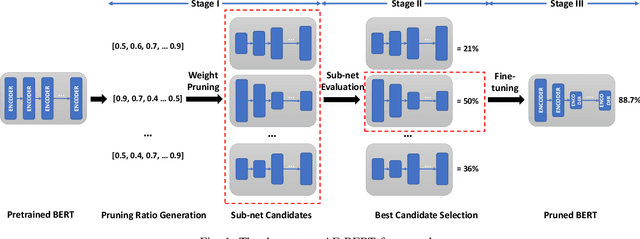
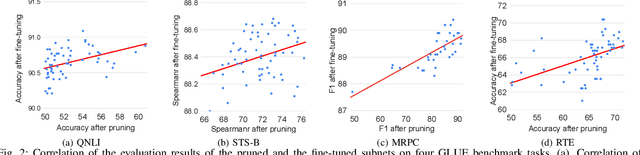
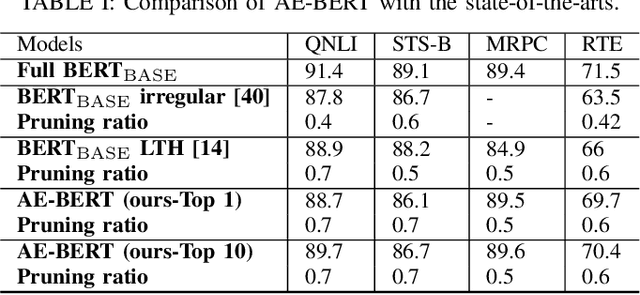
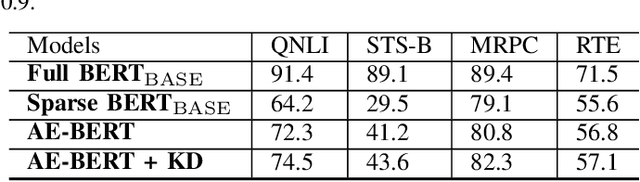
With the yearning for deep learning democratization, there are increasing demands to implement Transformer-based natural language processing (NLP) models on resource-constrained devices for low-latency and high accuracy. Existing BERT pruning methods require domain experts to heuristically handcraft hyperparameters to strike a balance among model size, latency, and accuracy. In this work, we propose AE-BERT, an automatic and efficient BERT pruning framework with efficient evaluation to select a "good" sub-network candidate (with high accuracy) given the overall pruning ratio constraints. Our proposed method requires no human experts experience and achieves a better accuracy performance on many NLP tasks. Our experimental results on General Language Understanding Evaluation (GLUE) benchmark show that AE-BERT outperforms the state-of-the-art (SOTA) hand-crafted pruning methods on BERT$_{\mathrm{BASE}}$. On QNLI and RTE, we obtain 75\% and 42.8\% more overall pruning ratio while achieving higher accuracy. On MRPC, we obtain a 4.6 higher score than the SOTA at the same overall pruning ratio of 0.5. On STS-B, we can achieve a 40\% higher pruning ratio with a very small loss in Spearman correlation compared to SOTA hand-crafted pruning methods. Experimental results also show that after model compression, the inference time of a single BERT$_{\mathrm{BASE}}$ encoder on Xilinx Alveo U200 FPGA board has a 1.83$\times$ speedup compared to Intel(R) Xeon(R) Gold 5218 (2.30GHz) CPU, which shows the reasonableness of deploying the proposed method generated subnets of BERT$_{\mathrm{BASE}}$ model on computation restricted devices.
Enabling Super-Fast Deep Learning on Tiny Energy-Harvesting IoT Devices
Nov 28, 2021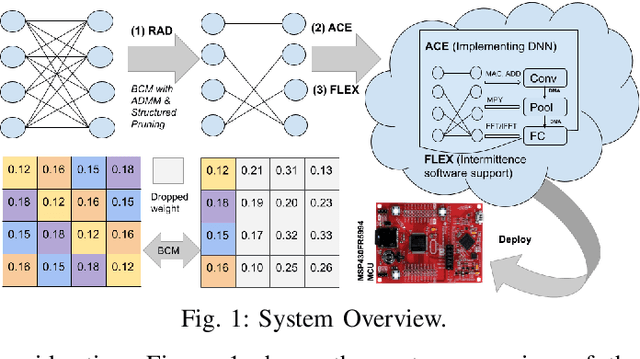
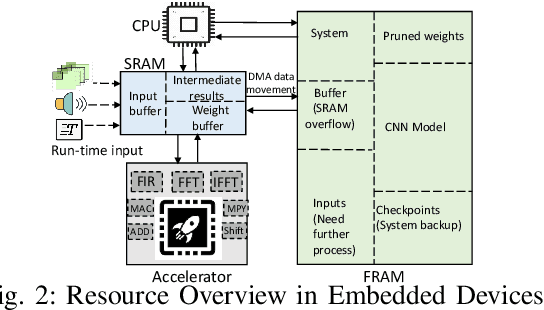
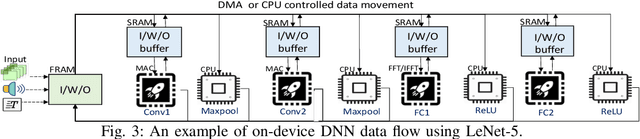
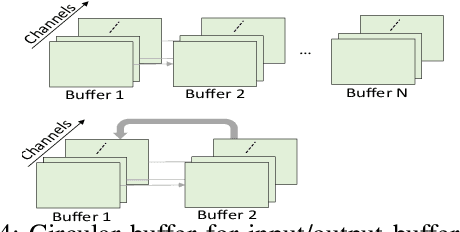
Energy harvesting (EH) IoT devices that operate intermittently without batteries, coupled with advances in deep neural networks (DNNs), have opened up new opportunities for enabling sustainable smart applications. Nevertheless, implementing those computation and memory-intensive intelligent algorithms on EH devices is extremely difficult due to the challenges of limited resources and intermittent power supply that causes frequent failures. To address those challenges, this paper proposes a methodology that enables super-fast deep learning with low-energy accelerators for tiny energy harvesting devices. We first propose RAD, a resource-aware structured DNN training framework, which employs block circulant matrix with ADMM to achieve high compression and model quantization for leveraging the advantage of various vector operation accelerators. A DNN implementation method, ACE, is then proposed that employs low-energy accelerators to profit maximum performance with minor energy consumption. Finally, we further design FLEX, the system support for intermittent computation in energy harvesting situations. Experimental results from three different DNN models demonstrate that RAD, ACE, and FLEX can enable super-fast and correct inference on energy harvesting devices with up to 4.26X runtime reduction, up to 7.7X energy reduction with higher accuracy over the state-of-the-art.
Sparse Progressive Distillation: Resolving Overfitting under Pretrain-and-Finetune Paradigm
Oct 18, 2021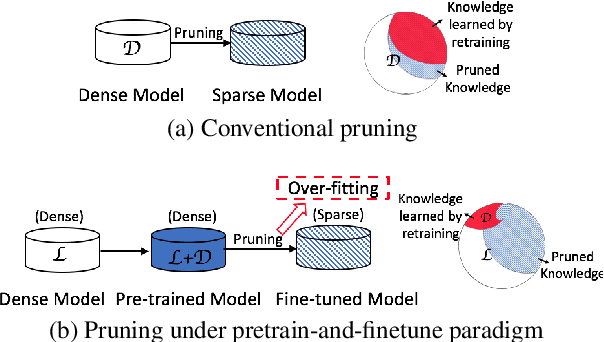
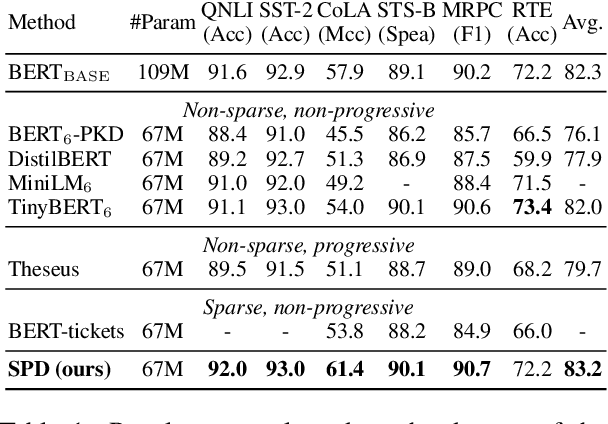
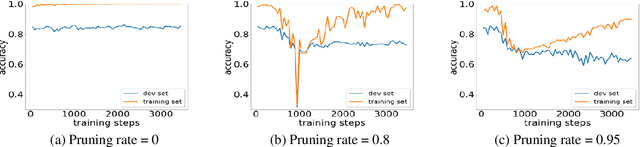
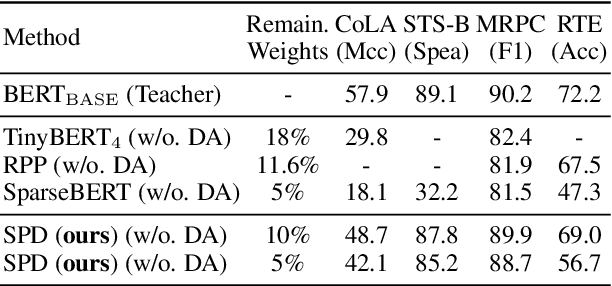
Various pruning approaches have been proposed to reduce the footprint requirements of Transformer-based language models. Conventional wisdom is that pruning reduces the model expressiveness and thus is more likely to underfit than overfit compared to the original model. However, under the trending pretrain-and-finetune paradigm, we argue that pruning increases the risk of overfitting if pruning was performed at the fine-tuning phase, as it increases the amount of information a model needs to learn from the downstream task, resulting in relative data deficiency. In this paper, we aim to address the overfitting issue under the pretrain-and-finetune paradigm to improve pruning performance via progressive knowledge distillation (KD) and sparse pruning. Furthermore, to mitigate the interference between different strategies of learning rate, pruning and distillation, we propose a three-stage learning framework. We show for the first time that reducing the risk of overfitting can help the effectiveness of pruning under the pretrain-and-finetune paradigm. Experiments on multiple datasets of GLUE benchmark show that our method achieves highly competitive pruning performance over the state-of-the-art competitors across different pruning ratio constraints.
Binary Complex Neural Network Acceleration on FPGA
Aug 10, 2021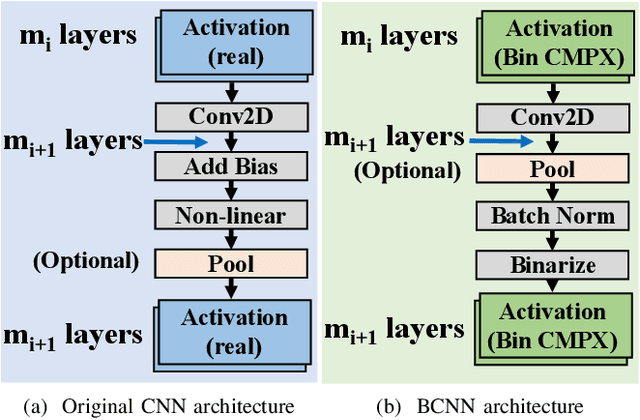
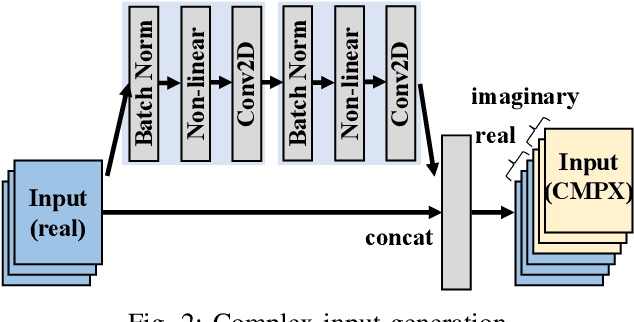

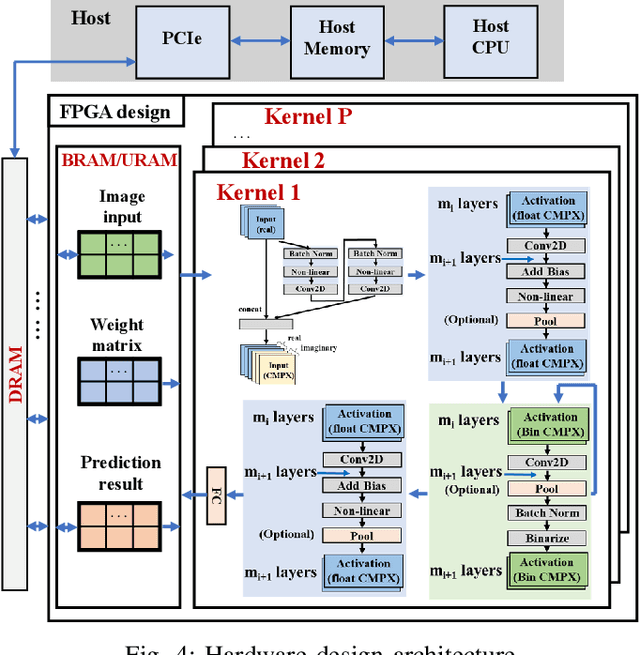
Being able to learn from complex data with phase information is imperative for many signal processing applications. Today' s real-valued deep neural networks (DNNs) have shown efficiency in latent information analysis but fall short when applied to the complex domain. Deep complex networks (DCN), in contrast, can learn from complex data, but have high computational costs; therefore, they cannot satisfy the instant decision-making requirements of many deployable systems dealing with short observations or short signal bursts. Recent, Binarized Complex Neural Network (BCNN), which integrates DCNs with binarized neural networks (BNN), shows great potential in classifying complex data in real-time. In this paper, we propose a structural pruning based accelerator of BCNN, which is able to provide more than 5000 frames/s inference throughput on edge devices. The high performance comes from both the algorithm and hardware sides. On the algorithm side, we conduct structural pruning to the original BCNN models and obtain 20 $\times$ pruning rates with negligible accuracy loss; on the hardware side, we propose a novel 2D convolution operation accelerator for the binary complex neural network. Experimental results show that the proposed design works with over 90% utilization and is able to achieve the inference throughput of 5882 frames/s and 4938 frames/s for complex NIN-Net and ResNet-18 using CIFAR-10 dataset and Alveo U280 Board.