 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussianEM: Model compositional and conformational heterogeneity using 3D Gaussians
Dec 25, 2025Understanding protein flexibility and its dynamic interactions with other molecules is essential for protein function study. Cryogenic electron microscopy (cryo-EM) provides an opportunity to directly observe macromolecular dynamics. However, analyzing datasets that contain both continuous motions and discrete states remains highly challenging. Here we present GaussianEM, a Gaussian pseudo-atomic framework that simultaneously models compositional and conformational heterogeneity from experimental cryo-EM images. GaussianEM employs a two-encoder-one-decoder architecture to map an image to its individual Gaussian components, and represent structural variability through changes in Gaussian parameters. This approach provides an intuitive and interpretable description of conformational changes, preserves local structural consistency along the transition trajectories, and naturally bridges the gap between density-based models and corresponding atomic models. We demonstrate the effectiveness of GaussianEM on both simulated and experimental datasets.
Neural Machine Translation with Dynamic Graph Convolutional Decoder
May 28, 2023



Existing wisdom demonstrates the significance of syntactic knowledge for the improvement of neural machine translation models. However, most previous works merely focus on leveraging the source syntax in the well-known encoder-decoder framework. In sharp contrast, this paper proposes an end-to-end translation architecture from the (graph \& sequence) structural inputs to the (graph \& sequence) outputs, where the target translation and its corresponding syntactic graph are jointly modeled and generated. We propose a customized Dynamic Spatial-Temporal Graph Convolutional Decoder (Dyn-STGCD), which is designed for consuming source feature representations and their syntactic graph, and auto-regressively generating the target syntactic graph and tokens simultaneously. We conduct extensive experiments on five widely acknowledged translation benchmarks, verifying that our proposal achieves consistent improvements over baselines and other syntax-aware variants.
An Automatic and Efficient BERT Pruning for Edge AI Systems
Jun 21, 2022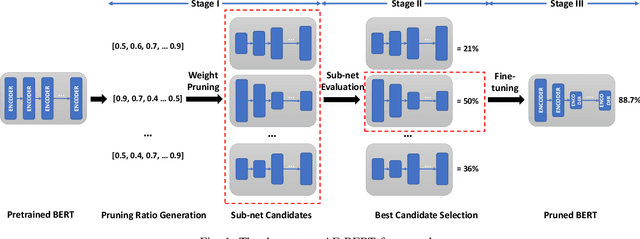
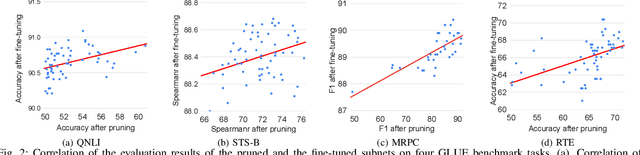
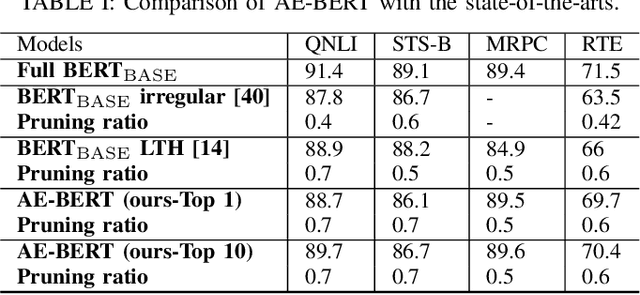
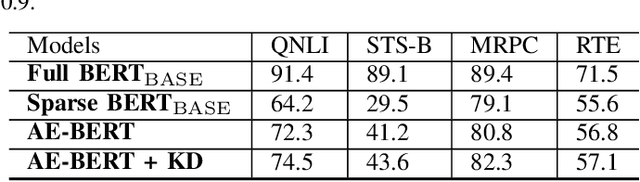
With the yearning for deep learning democratization, there are increasing demands to implement Transformer-based natural language processing (NLP) models on resource-constrained devices for low-latency and high accuracy. Existing BERT pruning methods require domain experts to heuristically handcraft hyperparameters to strike a balance among model size, latency, and accuracy. In this work, we propose AE-BERT, an automatic and efficient BERT pruning framework with efficient evaluation to select a "good" sub-network candidate (with high accuracy) given the overall pruning ratio constraints. Our proposed method requires no human experts experience and achieves a better accuracy performance on many NLP tasks. Our experimental results on General Language Understanding Evaluation (GLUE) benchmark show that AE-BERT outperforms the state-of-the-art (SOTA) hand-crafted pruning methods on BERT$_{\mathrm{BASE}}$. On QNLI and RTE, we obtain 75\% and 42.8\% more overall pruning ratio while achieving higher accuracy. On MRPC, we obtain a 4.6 higher score than the SOTA at the same overall pruning ratio of 0.5. On STS-B, we can achieve a 40\% higher pruning ratio with a very small loss in Spearman correlation compared to SOTA hand-crafted pruning methods. Experimental results also show that after model compression, the inference time of a single BERT$_{\mathrm{BASE}}$ encoder on Xilinx Alveo U200 FPGA board has a 1.83$\times$ speedup compared to Intel(R) Xeon(R) Gold 5218 (2.30GHz) CPU, which shows the reasonableness of deploying the proposed method generated subnets of BERT$_{\mathrm{BASE}}$ model on computation restricted devices.
HHF: Hashing-guided Hinge Function for Deep Hashing Retrieval
Dec 04, 2021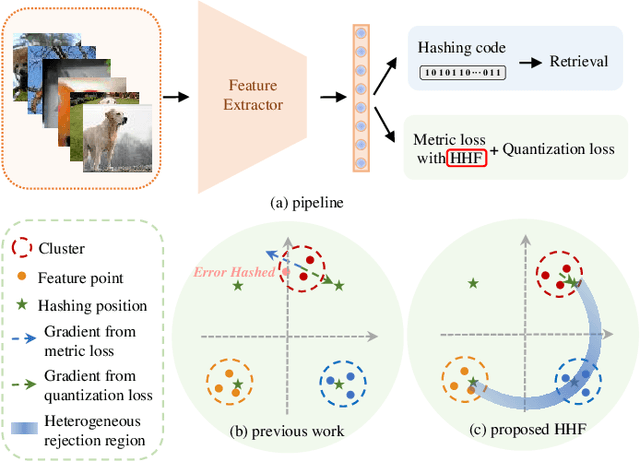

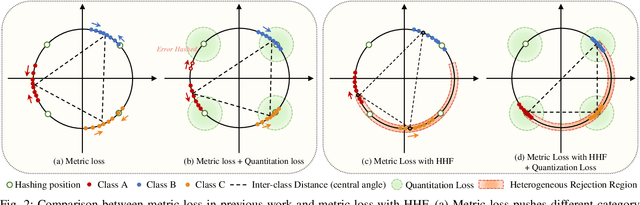
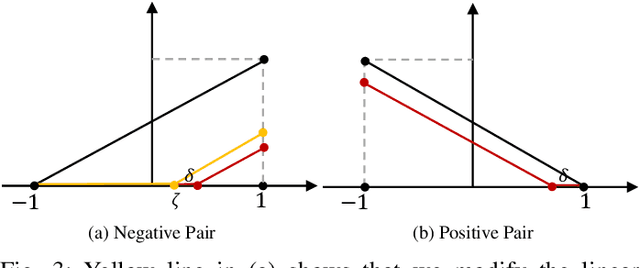
Deep hashing has shown promising performance in large-scale image retrieval. However, latent codes extracted by \textbf{D}eep \textbf{N}eural \textbf{N}etwork (DNN) will inevitably lose semantic information during the binarization process, which damages the retrieval efficiency and make it challenging. Although many existing approaches perform regularization to alleviate quantization errors, we figure out an incompatible conflict between the metric and quantization losses. The metric loss penalizes the inter-class distances to push different classes unconstrained far away. Worse still, it tends to map the latent code deviate from ideal binarization point and generate severe ambiguity in the binarization process. Based on the minimum distance of the binary linear code, \textbf{H}ashing-guided \textbf{H}inge \textbf{F}unction (HHF) is proposed to avoid such conflict. In detail, we carefully design a specific inflection point, which relies on the hash bit length and category numbers to balance metric learning and quantization learning. Such a modification prevents the network from falling into local metric optimal minima in deep hashing. Extensive experiments in CIFAR-10, CIFAR-100, ImageNet, and MS-COCO show that HHF consistently outperforms existing techniques, and is robust and flexible to transplant into other methods.
YOLObile: Real-Time Object Detection on Mobile Devices via Compression-Compilation Co-Design
Sep 12, 2020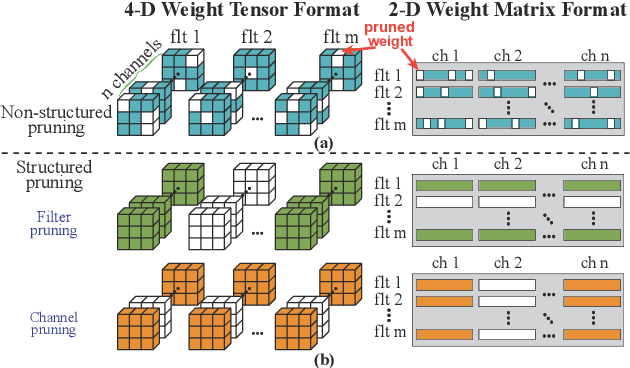
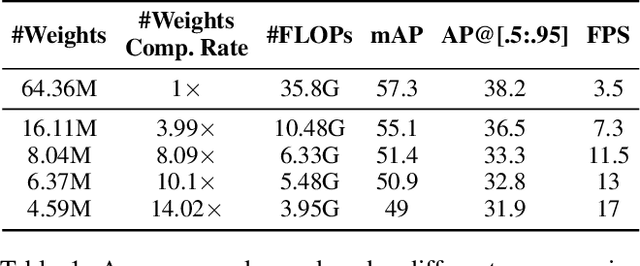
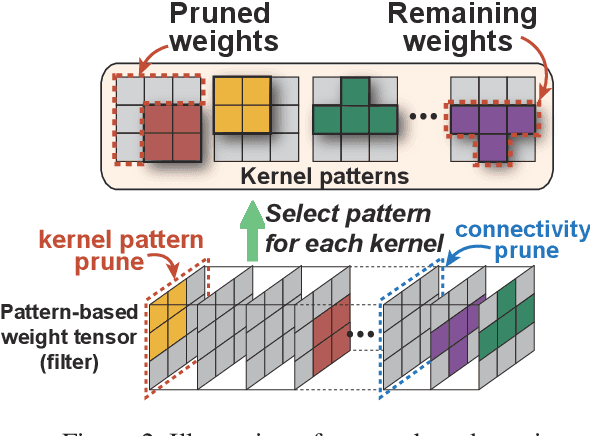
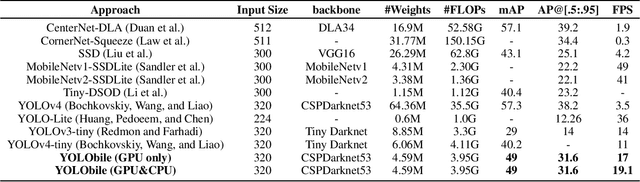
The rapid development and wide utilization of object detection techniques have aroused attention on both accuracy and speed of object detectors. However, the current state-of-the-art object detection works are either accuracy-oriented using a large model but leading to high latency or speed-oriented using a lightweight model but sacrificing accuracy. In this work, we propose YOLObile framework, a real-time object detection on mobile devices via compression-compilation co-design. A novel block-punched pruning scheme is proposed for any kernel size. To improve computational efficiency on mobile devices, a GPU-CPU collaborative scheme is adopted along with advanced compiler-assisted optimizations. Experimental results indicate that our pruning scheme achieves 14$\times$ compression rate of YOLOv4 with 49.0 mAP. Under our YOLObile framework, we achieve 17 FPS inference speed using GPU on Samsung Galaxy S20. By incorporating our proposed GPU-CPU collaborative scheme, the inference speed is increased to 19.1 FPS, and outperforms the original YOLOv4 by 5$\times$ speedup.
ESMFL: Efficient and Secure Models for Federated Learning
Sep 03, 2020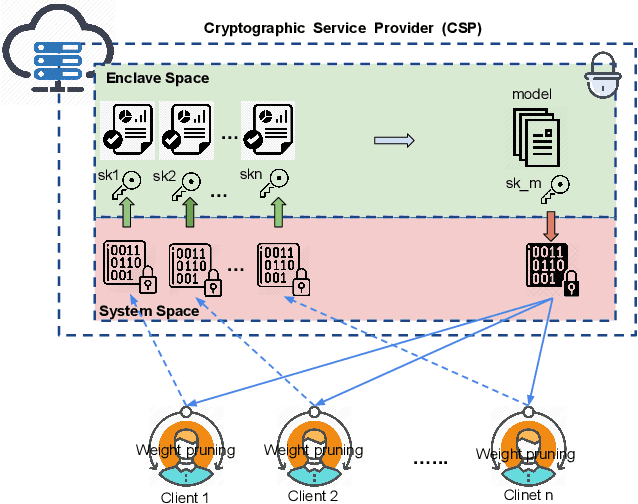
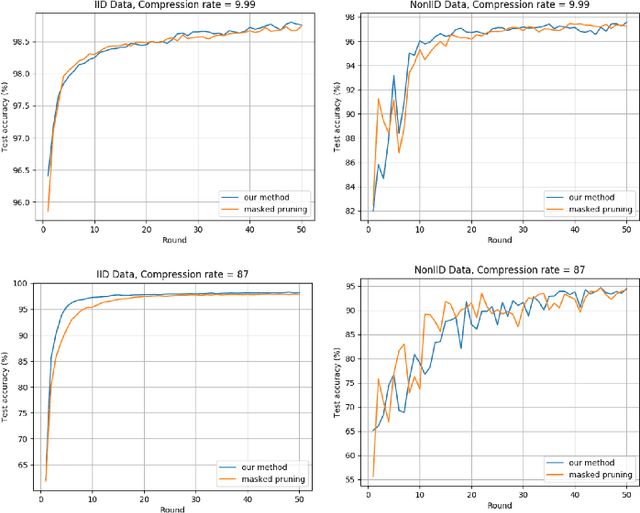
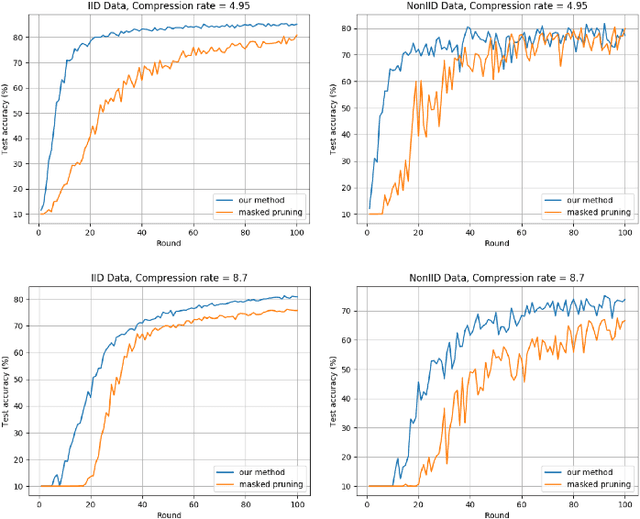
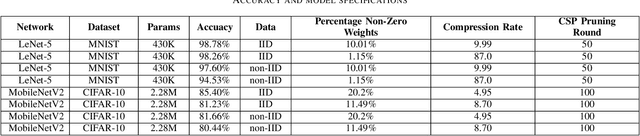
Deep Neural Networks are widely applied to various domains. The successful deployment of these applications is everywhere and it depends on the availability of big data. However, massive data collection required for deep neural network reveals the potential privacy issues and also consumes large mounts of communication bandwidth. To address this problem, we propose a privacy-preserving method for the federated learning distributed system, operated on Intel Software Guard Extensions, a set of instructions that increases the security of application code and data. Meanwhile, the encrypted models make the transmission overhead larger. Hence, we reduce the commutation cost by sparsification and achieve reasonable accuracy with different model architectures. Experimental results under our privacy-preserving framework show that, for LeNet-5, we obtain 98.78% accuracy on IID data and 97.60% accuracy on Non-IID data with 34.85% communication saving, and 1.8X total elapsed time acceleration. For MobileNetV2, we obtain 85.40% accuracy on IID data and 81.66% accuracy on Non-IID data with 15.85% communication saving, and 1.2X total elapsed time acceleration.
An Image Enhancing Pattern-based Sparsity for Real-time Inference on Mobile Devices
Feb 22, 2020
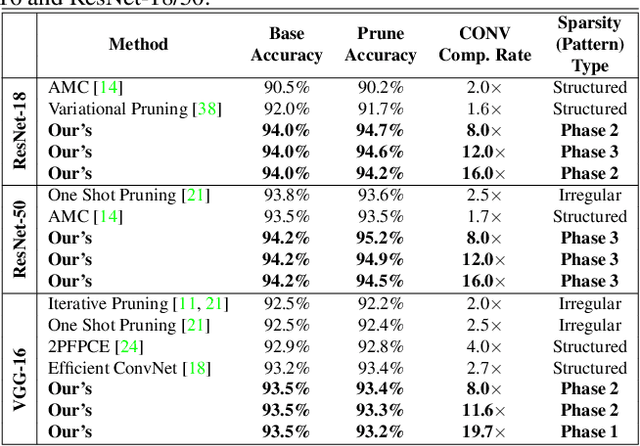
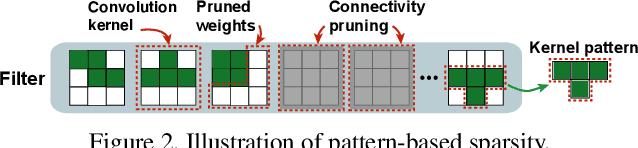
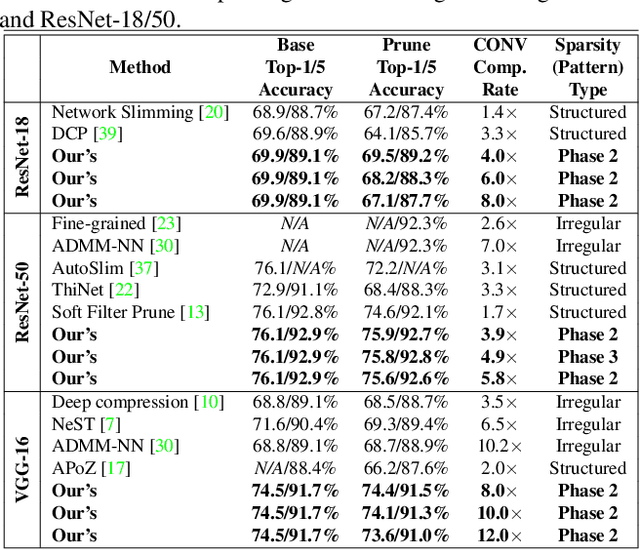
Weight pruning has been widely acknowledged as a straightforward and effective method to eliminate redundancy in Deep Neural Networks (DNN), thereby achieving acceleration on various platforms. However, most of the pruning techniques are essentially trade-offs between model accuracy and regularity which lead to impaired inference accuracy and limited on-device acceleration performance. To solve the problem, we introduce a new sparsity dimension, namely pattern-based sparsity that comprises pattern and connectivity sparsity, and becoming both highly accurate and hardware friendly. With carefully designed patterns, the proposed pruning unprecedentedly and consistently achieves accuracy enhancement and better feature extraction ability on different DNN structures and datasets, and our pattern-aware pruning framework also achieves pattern library extraction, pattern selection, pattern and connectivity pruning and weight training simultaneously. Our approach on the new pattern-based sparsity naturally fits into compiler optimization for highly efficient DNN execution on mobile platforms. To the best of our knowledge, it is the first time that mobile devices achieve real-time inference for the large-scale DNN models thanks to the unique spatial property of pattern-based sparsity and the help of the code generation capability of compilers.
Deep Compressed Pneumonia Detection for Low-Power Embedded Devices
Nov 04, 2019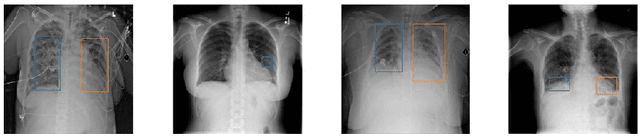
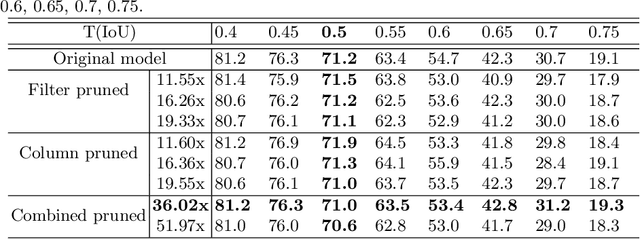

Deep neural networks (DNNs) have been expanded into medical fields and triggered the revolution of some medical applications by extracting complex features and achieving high accuracy and performance, etc. On the contrast, the large-scale network brings high requirements of both memory storage and computation resource, especially for portable medical devices and other embedded systems. In this work, we first train a DNN for pneumonia detection using the dataset provided by RSNA Pneumonia Detection Challenge. To overcome hardware limitation for implementing large-scale networks, we develop a systematic structured weight pruning method with filter sparsity, column sparsity and combined sparsity. Experiments show that we can achieve up to 36x compression ratio compared to the original model with 106 layers, while maintaining no accuracy degradation. We evaluate the proposed methods on an embedded low-power device, Jetson TX2, and achieve low power usage and high energy efficiency.
C3PO: Database and Benchmark for Early-stage Malicious Activity Detection in 3D Printing
Aug 02, 2018
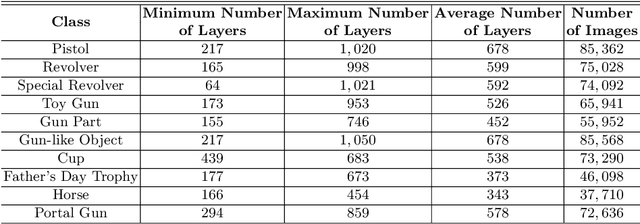

Increasing malicious users have sought practices to leverage 3D printing technology to produce unlawful tools in criminal activities. Current regulations are inadequate to deal with the rapid growth of 3D printers. It is of vital importance to enable 3D printers to identify the objects to be printed, so that the manufacturing procedure of an illegal weapon can be terminated at the early stage. Deep learning yields significant rises in performance in the object recognition tasks. However, the lack of large-scale databases in 3D printing domain stalls the advancement of automatic illegal weapon recognition. This paper presents a new 3D printing image database, namely C3PO, which compromises two subsets for the different system working scenarios. We extract images from the numerical control programming code files of 22 3D models, and then categorize the images into 10 distinct labels. The first set consists of 62,200 images which represent the object projections on the three planes in a Cartesian coordinate system. And the second sets consists of sequences of total 671,677 images to simulate the cameras' captures of the printed objects. Importantly, we demonstrate that the weapons can be recognized in either scenario using deep learning based approaches using our proposed database. % We also use the trained deep models to build a prototype of object-aware 3D printer. The quantitative results are promising, and the future exploration of the database and the crime prevention in 3D printing are demanding tasks.
Image Dataset for Visual Objects Classification in 3D Printing
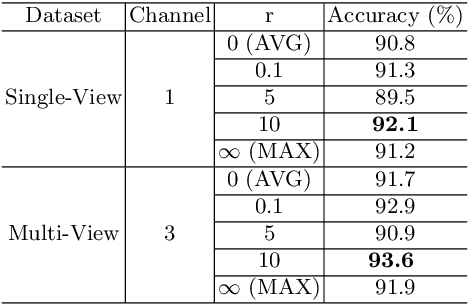
Mar 22, 2018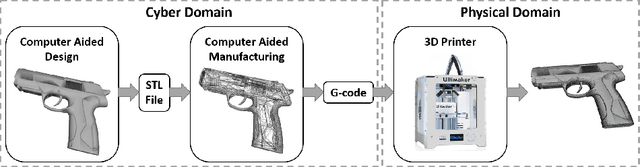

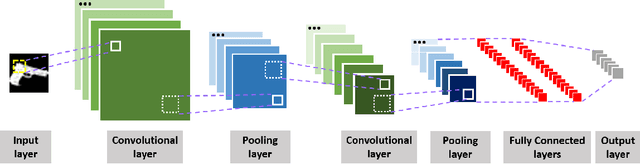
The rapid development in additive manufacturing (AM), also known as 3D printing, has brought about potential risk and security issues along with significant benefits. In order to enhance the security level of the 3D printing process, the present research aims to detect and recognize illegal components using deep learning. In this work, we collected a dataset of 61,340 2D images (28x28 for each image) of 10 classes including guns and other non-gun objects, corresponding to the projection results of the original 3D models. To validate the dataset, we train a convolutional neural network (CNN) model for gun classification which can achieve 98.16% classification accuracy.