 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
Unveiling Downstream Performance Scaling of LLMs: A Clustering-Based Perspective
Feb 24, 2025The rapid advancements in computing dramatically increase the scale and cost of training Large Language Models (LLMs). Accurately predicting downstream task performance prior to model training is crucial for efficient resource allocation, yet remains challenging due to two primary constraints: (1) the "emergence phenomenon", wherein downstream performance metrics become meaningful only after extensive training, which limits the ability to use smaller models for prediction; (2) Uneven task difficulty distributions and the absence of consistent scaling laws, resulting in substantial metric variability. Existing performance prediction methods suffer from limited accuracy and reliability, thereby impeding the assessment of potential LLM capabilities. To address these challenges, we propose a Clustering-On-Difficulty (COD) downstream performance prediction framework. COD first constructs a predictable support subset by clustering tasks based on difficulty features, strategically excluding non-emergent and non-scalable clusters. The scores on the selected subset serve as effective intermediate predictors of downstream performance on the full evaluation set. With theoretical support, we derive a mapping function that transforms performance metrics from the predictable subset to the full evaluation set, thereby ensuring accurate extrapolation of LLM downstream performance. The proposed method has been applied to predict performance scaling for a 70B LLM, providing actionable insights for training resource allocation and assisting in monitoring the training process. Notably, COD achieves remarkable predictive accuracy on the 70B LLM by leveraging an ensemble of small models, demonstrating an absolute mean deviation of 1.36% across eight important LLM evaluation benchmarks.
Towards Effective Collaborative Learning in Long-Tailed Recognition
May 05, 2023



Real-world data usually suffers from severe class imbalance and long-tailed distributions, where minority classes are significantly underrepresented compared to the majority ones. Recent research prefers to utilize multi-expert architectures to mitigate the model uncertainty on the minority, where collaborative learning is employed to aggregate the knowledge of experts, i.e., online distillation. In this paper, we observe that the knowledge transfer between experts is imbalanced in terms of class distribution, which results in limited performance improvement of the minority classes. To address it, we propose a re-weighted distillation loss by comparing two classifiers' predictions, which are supervised by online distillation and label annotations, respectively. We also emphasize that feature-level distillation will significantly improve model performance and increase feature robustness. Finally, we propose an Effective Collaborative Learning (ECL) framework that integrates a contrastive proxy task branch to further improve feature quality. Quantitative and qualitative experiments on four standard datasets demonstrate that ECL achieves state-of-the-art performance and the detailed ablation studies manifest the effectiveness of each component in ECL.
HyP$^2$ Loss: Beyond Hypersphere Metric Space for Multi-label Image Retrieval
Aug 14, 2022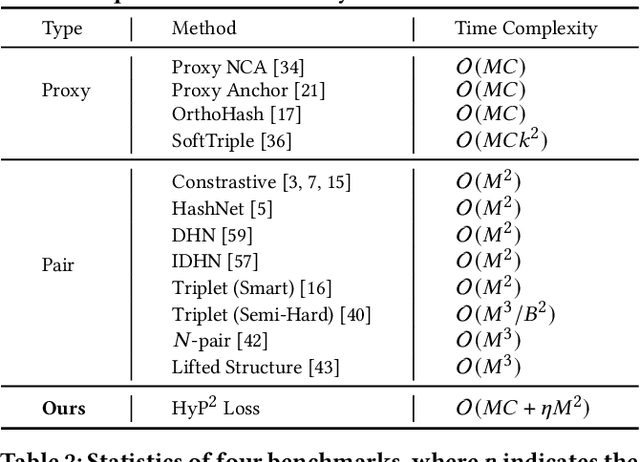
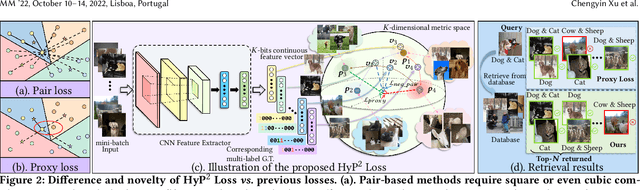
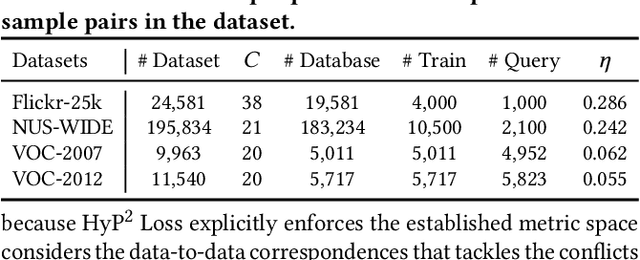
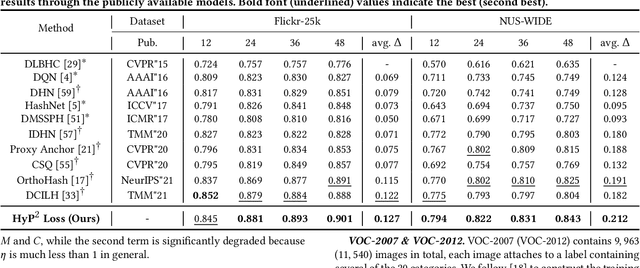
Image retrieval has become an increasingly appealing technique with broad multimedia application prospects, where deep hashing serves as the dominant branch towards low storage and efficient retrieval. In this paper, we carried out in-depth investigations on metric learning in deep hashing for establishing a powerful metric space in multi-label scenarios, where the pair loss suffers high computational overhead and converge difficulty, while the proxy loss is theoretically incapable of expressing the profound label dependencies and exhibits conflicts in the constructed hypersphere space. To address the problems, we propose a novel metric learning framework with Hybrid Proxy-Pair Loss (HyP$^2$ Loss) that constructs an expressive metric space with efficient training complexity w.r.t. the whole dataset. The proposed HyP$^2$ Loss focuses on optimizing the hypersphere space by learnable proxies and excavating data-to-data correlations of irrelevant pairs, which integrates sufficient data correspondence of pair-based methods and high-efficiency of proxy-based methods. Extensive experiments on four standard multi-label benchmarks justify the proposed method outperforms the state-of-the-art, is robust among different hash bits and achieves significant performance gains with a faster, more stable convergence speed. Our code is available at https://github.com/JerryXu0129/HyP2-Loss.
HHF: Hashing-guided Hinge Function for Deep Hashing Retrieval
Dec 04, 2021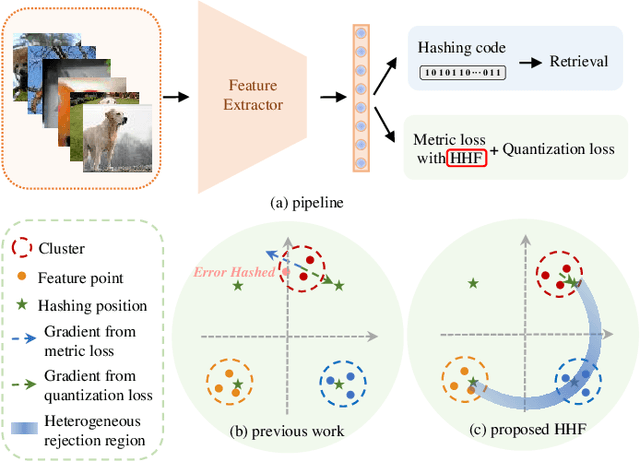

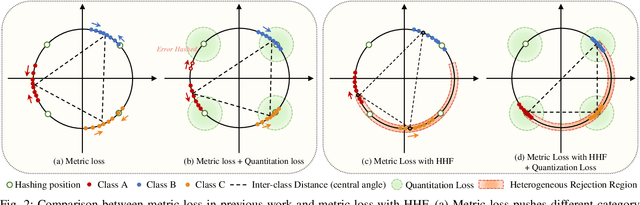
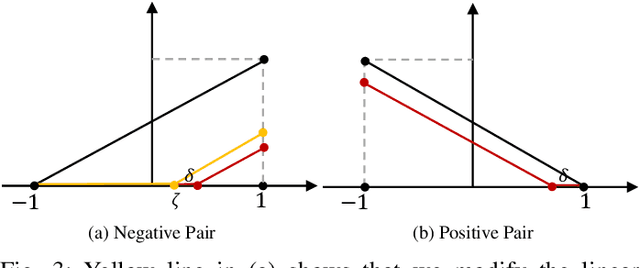
Deep hashing has shown promising performance in large-scale image retrieval. However, latent codes extracted by \textbf{D}eep \textbf{N}eural \textbf{N}etwork (DNN) will inevitably lose semantic information during the binarization process, which damages the retrieval efficiency and make it challenging. Although many existing approaches perform regularization to alleviate quantization errors, we figure out an incompatible conflict between the metric and quantization losses. The metric loss penalizes the inter-class distances to push different classes unconstrained far away. Worse still, it tends to map the latent code deviate from ideal binarization point and generate severe ambiguity in the binarization process. Based on the minimum distance of the binary linear code, \textbf{H}ashing-guided \textbf{H}inge \textbf{F}unction (HHF) is proposed to avoid such conflict. In detail, we carefully design a specific inflection point, which relies on the hash bit length and category numbers to balance metric learning and quantization learning. Such a modification prevents the network from falling into local metric optimal minima in deep hashing. Extensive experiments in CIFAR-10, CIFAR-100, ImageNet, and MS-COCO show that HHF consistently outperforms existing techniques, and is robust and flexible to transplant into other methods.