 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRANCE: Joint Token-Optimization and Structural Channel-Pruning for Adaptive ViT Inference
Jul 06, 2024



We introduce PRANCE, a Vision Transformer compression framework that jointly optimizes the activated channels and reduces tokens, based on the characteristics of inputs. Specifically, PRANCE~ leverages adaptive token optimization strategies for a certain computational budget, aiming to accelerate ViTs' inference from a unified data and architectural perspective. However, the joint framework poses challenges to both architectural and decision-making aspects. Firstly, while ViTs inherently support variable-token inference, they do not facilitate dynamic computations for variable channels. To overcome this limitation, we propose a meta-network using weight-sharing techniques to support arbitrary channels of the Multi-head Self-Attention and Multi-layer Perceptron layers, serving as a foundational model for architectural decision-making. Second, simultaneously optimizing the structure of the meta-network and input data constitutes a combinatorial optimization problem with an extremely large decision space, reaching up to around $10^{14}$, making supervised learning infeasible. To this end, we design a lightweight selector employing Proximal Policy Optimization for efficient decision-making. Furthermore, we introduce a novel "Result-to-Go" training mechanism that models ViTs' inference process as a Markov decision process, significantly reducing action space and mitigating delayed-reward issues during training. Extensive experiments demonstrate the effectiveness of PRANCE~ in reducing FLOPs by approximately 50\%, retaining only about 10\% of tokens while achieving lossless Top-1 accuracy. Additionally, our framework is shown to be compatible with various token optimization techniques such as pruning, merging, and sequential pruning-merging strategies. The code is available at \href{https://github.com/ChildTang/PRANCE}{https://github.com/ChildTang/PRANCE}.
STAR: Skeleton-aware Text-based 4D Avatar Generation with In-Network Motion Retargeting
Jun 07, 2024The creation of 4D avatars (i.e., animated 3D avatars) from text description typically uses text-to-image (T2I) diffusion models to synthesize 3D avatars in the canonical space and subsequently applies animation with target motions. However, such an optimization-by-animation paradigm has several drawbacks. (1) For pose-agnostic optimization, the rendered images in canonical pose for naive Score Distillation Sampling (SDS) exhibit domain gap and cannot preserve view-consistency using only T2I priors, and (2) For post hoc animation, simply applying the source motions to target 3D avatars yields translation artifacts and misalignment. To address these issues, we propose Skeleton-aware Text-based 4D Avatar generation with in-network motion Retargeting (STAR). STAR considers the geometry and skeleton differences between the template mesh and target avatar, and corrects the mismatched source motion by resorting to the pretrained motion retargeting techniques. With the informatively retargeted and occlusion-aware skeleton, we embrace the skeleton-conditioned T2I and text-to-video (T2V) priors, and propose a hybrid SDS module to coherently provide multi-view and frame-consistent supervision signals. Hence, STAR can progressively optimize the geometry, texture, and motion in an end-to-end manner. The quantitative and qualitative experiments demonstrate our proposed STAR can synthesize high-quality 4D avatars with vivid animations that align well with the text description. Additional ablation studies shows the contributions of each component in STAR. The source code and demos are available at: \href{https://star-avatar.github.io}{https://star-avatar.github.io}.
Towards Effective Collaborative Learning in Long-Tailed Recognition
May 05, 2023



Real-world data usually suffers from severe class imbalance and long-tailed distributions, where minority classes are significantly underrepresented compared to the majority ones. Recent research prefers to utilize multi-expert architectures to mitigate the model uncertainty on the minority, where collaborative learning is employed to aggregate the knowledge of experts, i.e., online distillation. In this paper, we observe that the knowledge transfer between experts is imbalanced in terms of class distribution, which results in limited performance improvement of the minority classes. To address it, we propose a re-weighted distillation loss by comparing two classifiers' predictions, which are supervised by online distillation and label annotations, respectively. We also emphasize that feature-level distillation will significantly improve model performance and increase feature robustness. Finally, we propose an Effective Collaborative Learning (ECL) framework that integrates a contrastive proxy task branch to further improve feature quality. Quantitative and qualitative experiments on four standard datasets demonstrate that ECL achieves state-of-the-art performance and the detailed ablation studies manifest the effectiveness of each component in ECL.
HiFace: High-Fidelity 3D Face Reconstruction by Learning Static and Dynamic Details
Mar 20, 20233D Morphable Models (3DMMs) demonstrate great potential for reconstructing faithful and animatable 3D facial surfaces from a single image. The facial surface is influenced by the coarse shape, as well as the static detail (e,g., person-specific appearance) and dynamic detail (e.g., expression-driven wrinkles). Previous work struggles to decouple the static and dynamic details through image-level supervision, leading to reconstructions that are not realistic. In this paper, we aim at high-fidelity 3D face reconstruction and propose HiFace to explicitly model the static and dynamic details. Specifically, the static detail is modeled as the linear combination of a displacement basis, while the dynamic detail is modeled as the linear interpolation of two displacement maps with polarized expressions. We exploit several loss functions to jointly learn the coarse shape and fine details with both synthetic and real-world datasets, which enable HiFace to reconstruct high-fidelity 3D shapes with animatable details. Extensive quantitative and qualitative experiments demonstrate that HiFace presents state-of-the-art reconstruction quality and faithfully recovers both the static and dynamic details. Our project page can be found at https://project-hiface.github.io
Searching Transferable Mixed-Precision Quantization Policy through Large Margin Regularization
Feb 14, 2023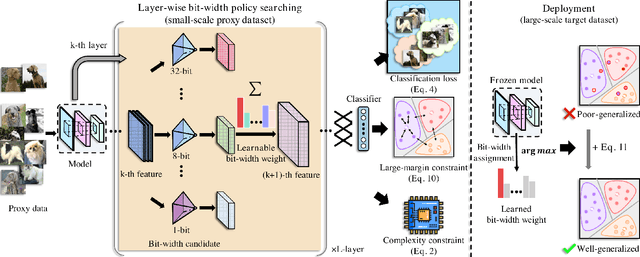
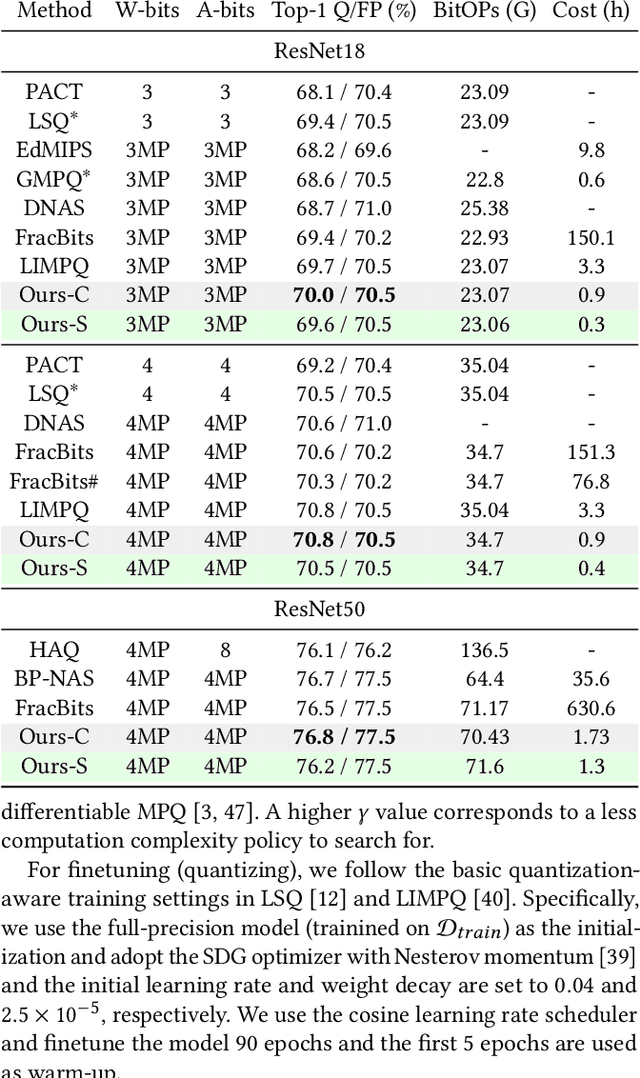

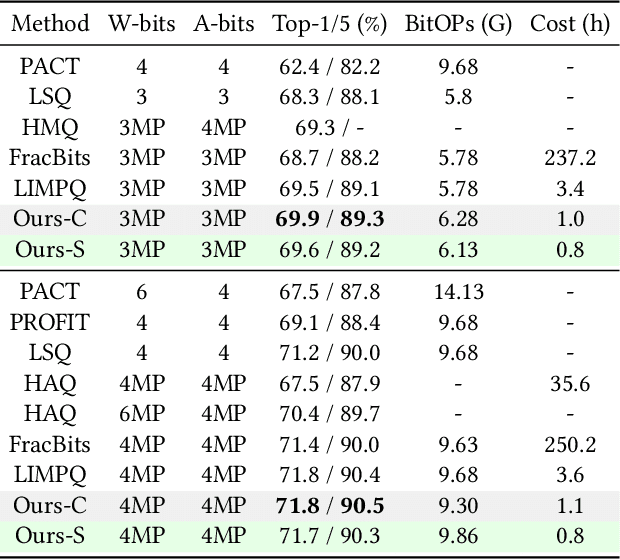
Mixed-precision quantization (MPQ) suffers from time-consuming policy search process (i.e., the bit-width assignment for each layer) on large-scale datasets (e.g., ISLVRC-2012), which heavily limits its practicability in real-world deployment scenarios. In this paper, we propose to search the effective MPQ policy by using a small proxy dataset for the model trained on a large-scale one. It breaks the routine that requires a consistent dataset at model training and MPQ policy search time, which can improve the MPQ searching efficiency significantly. However, the discrepant data distributions bring difficulties in searching for such a transferable MPQ policy. Motivated by the observation that quantization narrows the class margin and blurs the decision boundary, we search the policy that guarantees a general and dataset-independent property: discriminability of feature representations. Namely, we seek the policy that can robustly keep the intra-class compactness and inter-class separation. Our method offers several advantages, i.e., high proxy data utilization, no extra hyper-parameter tuning for approximating the relationship between full-precision and quantized model and high searching efficiency. We search high-quality MPQ policies with the proxy dataset that has only 4% of the data scale compared to the large-scale target dataset, achieving the same accuracy as searching directly on the latter, and improving the MPQ searching efficiency by up to 300 times.
ERA-Solver: Error-Robust Adams Solver for Fast Sampling of Diffusion Probabilistic Models
Feb 06, 2023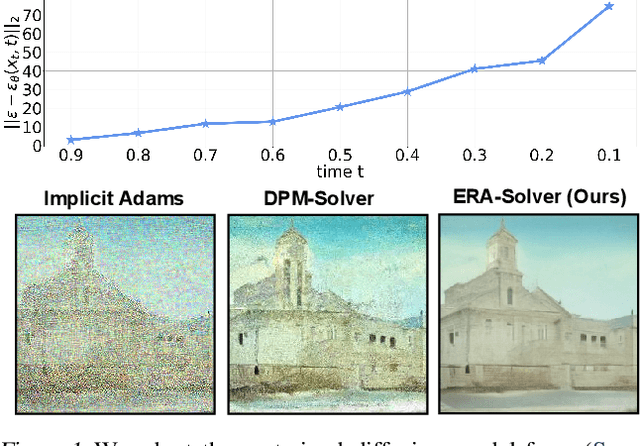

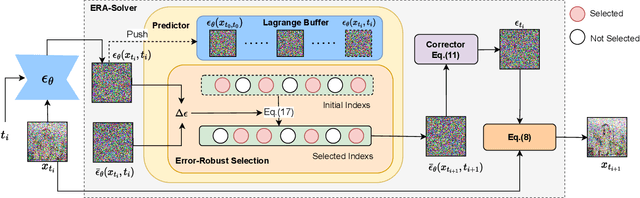
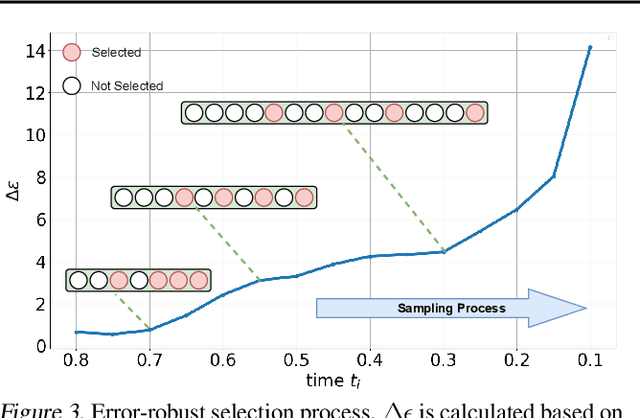
Though denoising diffusion probabilistic models (DDPMs) have achieved remarkable generation results, the low sampling efficiency of DDPMs still limits further applications. Since DDPMs can be formulated as diffusion ordinary differential equations (ODEs), various fast sampling methods can be derived from solving diffusion ODEs. However, we notice that previous sampling methods with fixed analytical form are not robust with the error in the noise estimated from pretrained diffusion models. In this work, we construct an error-robust Adams solver (ERA-Solver), which utilizes the implicit Adams numerical method that consists of a predictor and a corrector. Different from the traditional predictor based on explicit Adams methods, we leverage a Lagrange interpolation function as the predictor, which is further enhanced with an error-robust strategy to adaptively select the Lagrange bases with lower error in the estimated noise. Experiments on Cifar10, LSUN-Church, and LSUN-Bedroom datasets demonstrate that our proposed ERA-Solver achieves 5.14, 9.42, and 9.69 Fenchel Inception Distance (FID) for image generation, with only 10 network evaluations.
Learning Imbalanced Data with Vision Transformers
Dec 05, 2022



The real-world data tends to be heavily imbalanced and severely skew the data-driven deep neural networks, which makes Long-Tailed Recognition (LTR) a massive challenging task. Existing LTR methods seldom train Vision Transformers (ViTs) with Long-Tailed (LT) data, while the off-the-shelf pretrain weight of ViTs always leads to unfair comparisons. In this paper, we systematically investigate the ViTs' performance in LTR and propose LiVT to train ViTs from scratch only with LT data. With the observation that ViTs suffer more severe LTR problems, we conduct Masked Generative Pretraining (MGP) to learn generalized features. With ample and solid evidence, we show that MGP is more robust than supervised manners. In addition, Binary Cross Entropy (BCE) loss, which shows conspicuous performance with ViTs, encounters predicaments in LTR. We further propose the balanced BCE to ameliorate it with strong theoretical groundings. Specially, we derive the unbiased extension of Sigmoid and compensate extra logit margins to deploy it. Our Bal-BCE contributes to the quick convergence of ViTs in just a few epochs. Extensive experiments demonstrate that with MGP and Bal-BCE, LiVT successfully trains ViTs well without any additional data and outperforms comparable state-of-the-art methods significantly, e.g., our ViT-B achieves 81.0% Top-1 accuracy in iNaturalist 2018 without bells and whistles. Code is available at https://github.com/XuZhengzhuo/LiVT.
HyP$^2$ Loss: Beyond Hypersphere Metric Space for Multi-label Image Retrieval
Aug 14, 2022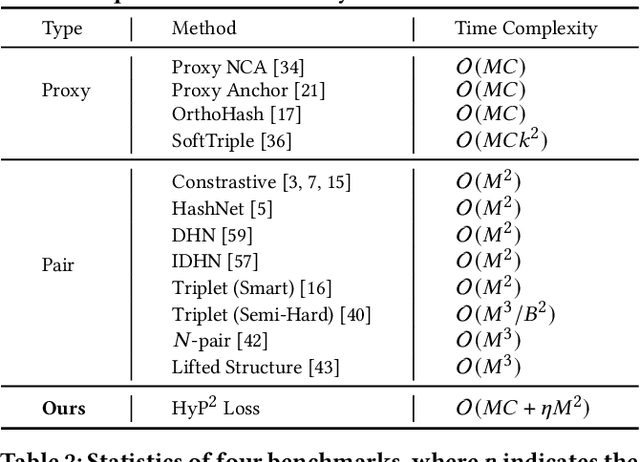
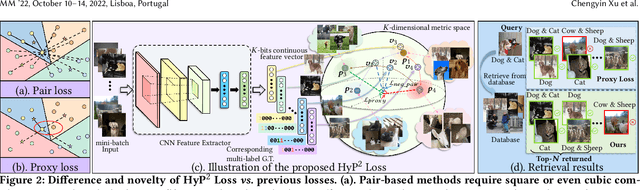
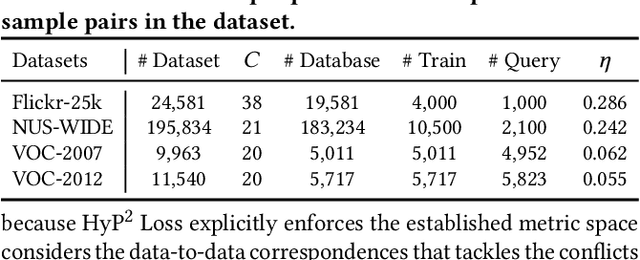
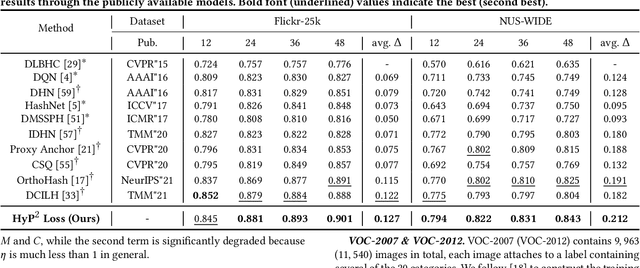
Image retrieval has become an increasingly appealing technique with broad multimedia application prospects, where deep hashing serves as the dominant branch towards low storage and efficient retrieval. In this paper, we carried out in-depth investigations on metric learning in deep hashing for establishing a powerful metric space in multi-label scenarios, where the pair loss suffers high computational overhead and converge difficulty, while the proxy loss is theoretically incapable of expressing the profound label dependencies and exhibits conflicts in the constructed hypersphere space. To address the problems, we propose a novel metric learning framework with Hybrid Proxy-Pair Loss (HyP$^2$ Loss) that constructs an expressive metric space with efficient training complexity w.r.t. the whole dataset. The proposed HyP$^2$ Loss focuses on optimizing the hypersphere space by learnable proxies and excavating data-to-data correlations of irrelevant pairs, which integrates sufficient data correspondence of pair-based methods and high-efficiency of proxy-based methods. Extensive experiments on four standard multi-label benchmarks justify the proposed method outperforms the state-of-the-art, is robust among different hash bits and achieves significant performance gains with a faster, more stable convergence speed. Our code is available at https://github.com/JerryXu0129/HyP2-Loss.
REALY: Rethinking the Evaluation of 3D Face Reconstruction
Mar 18, 2022

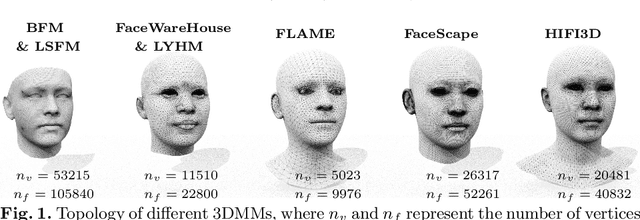
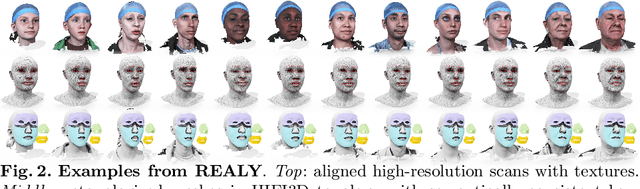
The evaluation of 3D face reconstruction results typically relies on a rigid shape alignment between the estimated 3D model and the ground-truth scan. We observe that aligning two shapes with different reference points can largely affect the evaluation results. This poses difficulties for precisely diagnosing and improving a 3D face reconstruction method. In this paper, we propose a novel evaluation approach with a new benchmark REALY, consists of 100 globally aligned face scans with accurate facial keypoints, high-quality region masks, and topology-consistent meshes. Our approach performs region-wise shape alignment and leads to more accurate, bidirectional correspondences during computing the shape errors. The fine-grained, region-wise evaluation results provide us detailed understandings about the performance of state-of-the-art 3D face reconstruction methods. For example, our experiments on single-image based reconstruction methods reveal that DECA performs the best on nose regions, while GANFit performs better on cheek regions. Besides, a new and high-quality 3DMM basis, HIFI3D++, is further derived using the same procedure as we construct REALY to align and retopologize several 3D face datasets. We will release REALY, HIFI3D++, and our new evaluation pipeline at https://realy3dface.com.
HHF: Hashing-guided Hinge Function for Deep Hashing Retrieval
Dec 04, 2021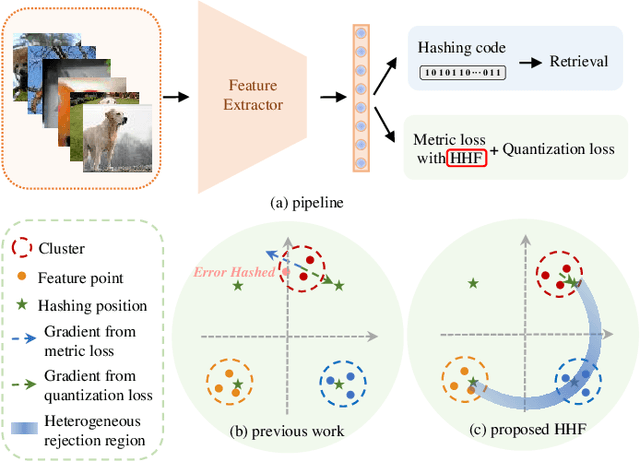

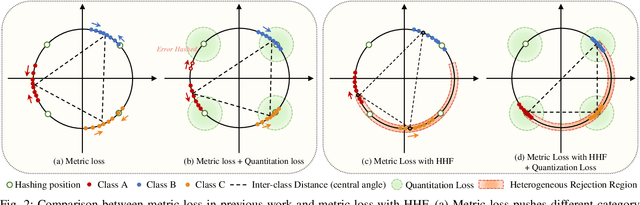
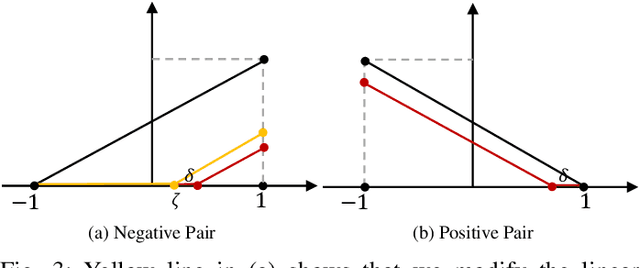
Deep hashing has shown promising performance in large-scale image retrieval. However, latent codes extracted by \textbf{D}eep \textbf{N}eural \textbf{N}etwork (DNN) will inevitably lose semantic information during the binarization process, which damages the retrieval efficiency and make it challenging. Although many existing approaches perform regularization to alleviate quantization errors, we figure out an incompatible conflict between the metric and quantization losses. The metric loss penalizes the inter-class distances to push different classes unconstrained far away. Worse still, it tends to map the latent code deviate from ideal binarization point and generate severe ambiguity in the binarization process. Based on the minimum distance of the binary linear code, \textbf{H}ashing-guided \textbf{H}inge \textbf{F}unction (HHF) is proposed to avoid such conflict. In detail, we carefully design a specific inflection point, which relies on the hash bit length and category numbers to balance metric learning and quantization learning. Such a modification prevents the network from falling into local metric optimal minima in deep hashing. Extensive experiments in CIFAR-10, CIFAR-100, ImageNet, and MS-COCO show that HHF consistently outperforms existing techniques, and is robust and flexible to transplant into other methods.