 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-Aware Implicit Motion Control for View-Adaptive Human Video Generation
Feb 03, 2026Existing methods for human motion control in video generation typically rely on either 2D poses or explicit 3D parametric models (e.g., SMPL) as control signals. However, 2D poses rigidly bind motion to the driving viewpoint, precluding novel-view synthesis. Explicit 3D models, though structurally informative, suffer from inherent inaccuracies (e.g., depth ambiguity and inaccurate dynamics) which, when used as a strong constraint, override the powerful intrinsic 3D awareness of large-scale video generators. In this work, we revisit motion control from a 3D-aware perspective, advocating for an implicit, view-agnostic motion representation that naturally aligns with the generator's spatial priors rather than depending on externally reconstructed constraints. We introduce 3DiMo, which jointly trains a motion encoder with a pretrained video generator to distill driving frames into compact, view-agnostic motion tokens, injected semantically via cross-attention. To foster 3D awareness, we train with view-rich supervision (i.e., single-view, multi-view, and moving-camera videos), forcing motion consistency across diverse viewpoints. Additionally, we use auxiliary geometric supervision that leverages SMPL only for early initialization and is annealed to zero, enabling the model to transition from external 3D guidance to learning genuine 3D spatial motion understanding from the data and the generator's priors. Experiments confirm that 3DiMo faithfully reproduces driving motions with flexible, text-driven camera control, significantly surpassing existing methods in both motion fidelity and visual quality.
From Inpainting to Editing: A Self-Bootstrapping Framework for Context-Rich Visual Dubbing
Dec 31, 2025Audio-driven visual dubbing aims to synchronize a video's lip movements with new speech, but is fundamentally challenged by the lack of ideal training data: paired videos where only a subject's lip movements differ while all other visual conditions are identical. Existing methods circumvent this with a mask-based inpainting paradigm, where an incomplete visual conditioning forces models to simultaneously hallucinate missing content and sync lips, leading to visual artifacts, identity drift, and poor synchronization. In this work, we propose a novel self-bootstrapping framework that reframes visual dubbing from an ill-posed inpainting task into a well-conditioned video-to-video editing problem. Our approach employs a Diffusion Transformer, first as a data generator, to synthesize ideal training data: a lip-altered companion video for each real sample, forming visually aligned video pairs. A DiT-based audio-driven editor is then trained on these pairs end-to-end, leveraging the complete and aligned input video frames to focus solely on precise, audio-driven lip modifications. This complete, frame-aligned input conditioning forms a rich visual context for the editor, providing it with complete identity cues, scene interactions, and continuous spatiotemporal dynamics. Leveraging this rich context fundamentally enables our method to achieve highly accurate lip sync, faithful identity preservation, and exceptional robustness against challenging in-the-wild scenarios. We further introduce a timestep-adaptive multi-phase learning strategy as a necessary component to disentangle conflicting editing objectives across diffusion timesteps, thereby facilitating stable training and yielding enhanced lip synchronization and visual fidelity. Additionally, we propose ContextDubBench, a comprehensive benchmark dataset for robust evaluation in diverse and challenging practical application scenarios.
KlingAvatar 2.0 Technical Report
Dec 15, 2025Avatar video generation models have achieved remarkable progress in recent years. However, prior work exhibits limited efficiency in generating long-duration high-resolution videos, suffering from temporal drifting, quality degradation, and weak prompt following as video length increases. To address these challenges, we propose KlingAvatar 2.0, a spatio-temporal cascade framework that performs upscaling in both spatial resolution and temporal dimension. The framework first generates low-resolution blueprint video keyframes that capture global semantics and motion, and then refines them into high-resolution, temporally coherent sub-clips using a first-last frame strategy, while retaining smooth temporal transitions in long-form videos. To enhance cross-modal instruction fusion and alignment in extended videos, we introduce a Co-Reasoning Director composed of three modality-specific large language model (LLM) experts. These experts reason about modality priorities and infer underlying user intent, converting inputs into detailed storylines through multi-turn dialogue. A Negative Director further refines negative prompts to improve instruction alignment. Building on these components, we extend the framework to support ID-specific multi-character control. Extensive experiments demonstrate that our model effectively addresses the challenges of efficient, multimodally aligned long-form high-resolution video generation, delivering enhanced visual clarity, realistic lip-teeth rendering with accurate lip synchronization, strong identity preservation, and coherent multimodal instruction following.
MIDAS: Multimodal Interactive Digital-humAn Synthesis via Real-time Autoregressive Video Generation
Aug 28, 2025Recently, interactive digital human video generation has attracted widespread attention and achieved remarkable progress. However, building such a practical system that can interact with diverse input signals in real time remains challenging to existing methods, which often struggle with heavy computational cost and limited controllability. In this work, we introduce an autoregressive video generation framework that enables interactive multimodal control and low-latency extrapolation in a streaming manner. With minimal modifications to a standard large language model (LLM), our framework accepts multimodal condition encodings including audio, pose, and text, and outputs spatially and semantically coherent representations to guide the denoising process of a diffusion head. To support this, we construct a large-scale dialogue dataset of approximately 20,000 hours from multiple sources, providing rich conversational scenarios for training. We further introduce a deep compression autoencoder with up to 64$\times$ reduction ratio, which effectively alleviates the long-horizon inference burden of the autoregressive model. Extensive experiments on duplex conversation, multilingual human synthesis, and interactive world model highlight the advantages of our approach in low latency, high efficiency, and fine-grained multimodal controllability.
GGTalker: Talking Head Systhesis with Generalizable Gaussian Priors and Identity-Specific Adaptation
Jun 26, 2025Creating high-quality, generalizable speech-driven 3D talking heads remains a persistent challenge. Previous methods achieve satisfactory results for fixed viewpoints and small-scale audio variations, but they struggle with large head rotations and out-of-distribution (OOD) audio. Moreover, they are constrained by the need for time-consuming, identity-specific training. We believe the core issue lies in the lack of sufficient 3D priors, which limits the extrapolation capabilities of synthesized talking heads. To address this, we propose GGTalker, which synthesizes talking heads through a combination of generalizable priors and identity-specific adaptation. We introduce a two-stage Prior-Adaptation training strategy to learn Gaussian head priors and adapt to individual characteristics. We train Audio-Expression and Expression-Visual priors to capture the universal patterns of lip movements and the general distribution of head textures. During the Customized Adaptation, individual speaking styles and texture details are precisely modeled. Additionally, we introduce a color MLP to generate fine-grained, motion-aligned textures and a Body Inpainter to blend rendered results with the background, producing indistinguishable, photorealistic video frames. Comprehensive experiments show that GGTalker achieves state-of-the-art performance in rendering quality, 3D consistency, lip-sync accuracy, and training efficiency.
OmniSync: Towards Universal Lip Synchronization via Diffusion Transformers
May 27, 2025Lip synchronization is the task of aligning a speaker's lip movements in video with corresponding speech audio, and it is essential for creating realistic, expressive video content. However, existing methods often rely on reference frames and masked-frame inpainting, which limit their robustness to identity consistency, pose variations, facial occlusions, and stylized content. In addition, since audio signals provide weaker conditioning than visual cues, lip shape leakage from the original video will affect lip sync quality. In this paper, we present OmniSync, a universal lip synchronization framework for diverse visual scenarios. Our approach introduces a mask-free training paradigm using Diffusion Transformer models for direct frame editing without explicit masks, enabling unlimited-duration inference while maintaining natural facial dynamics and preserving character identity. During inference, we propose a flow-matching-based progressive noise initialization to ensure pose and identity consistency, while allowing precise mouth-region editing. To address the weak conditioning signal of audio, we develop a Dynamic Spatiotemporal Classifier-Free Guidance (DS-CFG) mechanism that adaptively adjusts guidance strength over time and space. We also establish the AIGC-LipSync Benchmark, the first evaluation suite for lip synchronization in diverse AI-generated videos. Extensive experiments demonstrate that OmniSync significantly outperforms prior methods in both visual quality and lip sync accuracy, achieving superior results in both real-world and AI-generated videos.
Learning Audio-Driven Viseme Dynamics for 3D Face Animation
Jan 15, 2023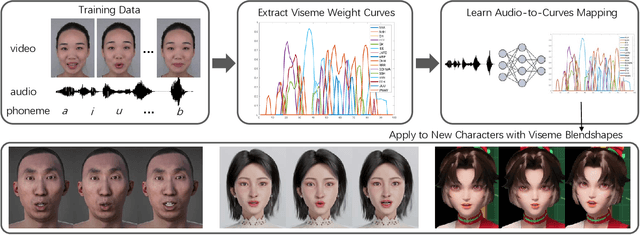
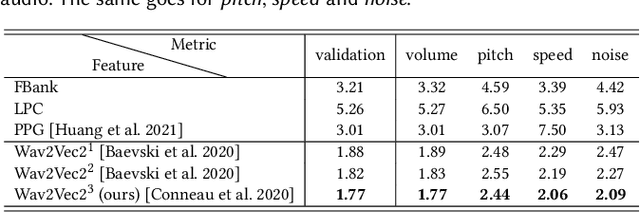
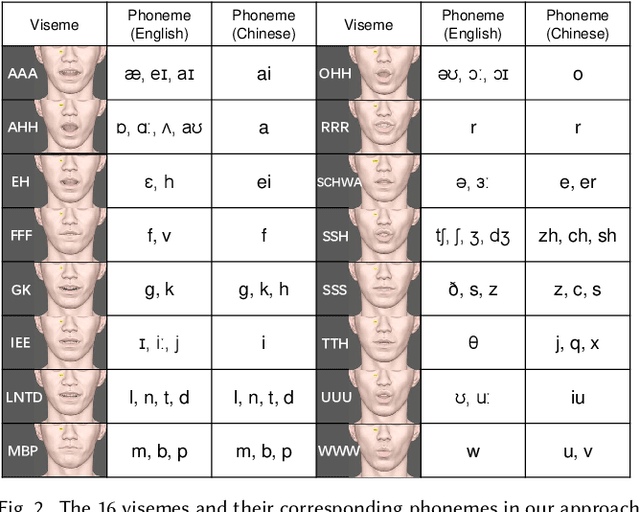
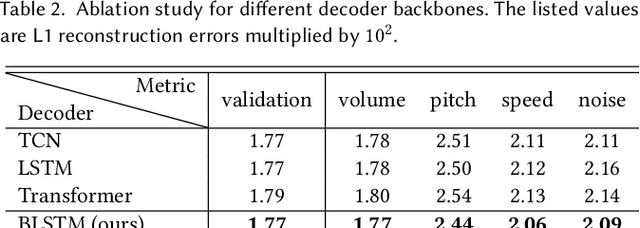
We present a novel audio-driven facial animation approach that can generate realistic lip-synchronized 3D facial animations from the input audio. Our approach learns viseme dynamics from speech videos, produces animator-friendly viseme curves, and supports multilingual speech inputs. The core of our approach is a novel parametric viseme fitting algorithm that utilizes phoneme priors to extract viseme parameters from speech videos. With the guidance of phonemes, the extracted viseme curves can better correlate with phonemes, thus more controllable and friendly to animators. To support multilingual speech inputs and generalizability to unseen voices, we take advantage of deep audio feature models pretrained on multiple languages to learn the mapping from audio to viseme curves. Our audio-to-curves mapping achieves state-of-the-art performance even when the input audio suffers from distortions of volume, pitch, speed, or noise. Lastly, a viseme scanning approach for acquiring high-fidelity viseme assets is presented for efficient speech animation production. We show that the predicted viseme curves can be applied to different viseme-rigged characters to yield various personalized animations with realistic and natural facial motions. Our approach is artist-friendly and can be easily integrated into typical animation production workflows including blendshape or bone based animation.
FFHQ-UV: Normalized Facial UV-Texture Dataset for 3D Face Reconstruction
Nov 25, 2022



We present a large-scale facial UV-texture dataset that contains over 50,000 high-quality texture UV-maps with even illuminations, neutral expressions, and cleaned facial regions, which are desired characteristics for rendering realistic 3D face models under different lighting conditions. The dataset is derived from a large-scale face image dataset namely FFHQ, with the help of our fully automatic and robust UV-texture production pipeline. Our pipeline utilizes the recent advances in StyleGAN-based facial image editing approaches to generate multi-view normalized face images from single-image inputs. An elaborated UV-texture extraction, correction, and completion procedure is then applied to produce high-quality UV-maps from the normalized face images. Compared with existing UV-texture datasets, our dataset has more diverse and higher-quality texture maps. We further train a GAN-based texture decoder as the nonlinear texture basis for parametric fitting based 3D face reconstruction. Experiments show that our method improves the reconstruction accuracy over state-of-the-art approaches, and more importantly, produces high-quality texture maps that are ready for realistic renderings. The dataset, code, and pre-trained texture decoder are publicly available at https://github.com/csbhr/FFHQ-UV.
Smooth image-to-image translations with latent space interpolations
Oct 03, 2022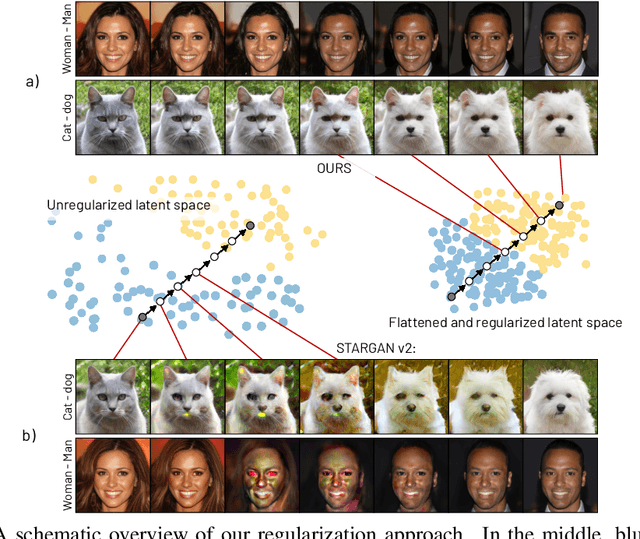
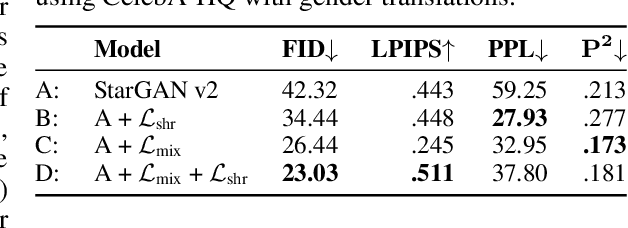
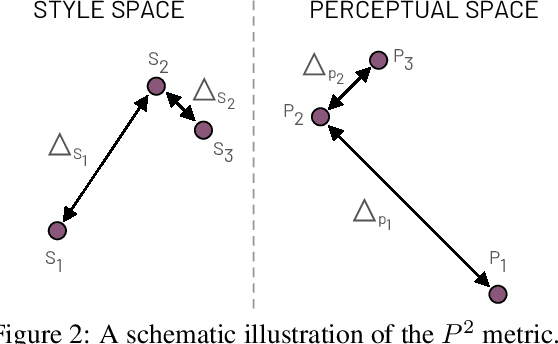
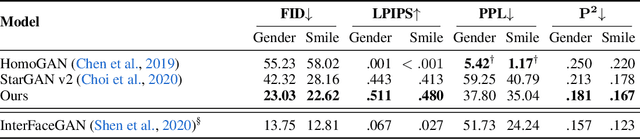
Multi-domain image-to-image (I2I) translations can transform a source image according to the style of a target domain. One important, desired characteristic of these transformations, is their graduality, which corresponds to a smooth change between the source and the target image when their respective latent-space representations are linearly interpolated. However, state-of-the-art methods usually perform poorly when evaluated using inter-domain interpolations, often producing abrupt changes in the appearance or non-realistic intermediate images. In this paper, we argue that one of the main reasons behind this problem is the lack of sufficient inter-domain training data and we propose two different regularization methods to alleviate this issue: a new shrinkage loss, which compacts the latent space, and a Mixup data-augmentation strategy, which flattens the style representations between domains. We also propose a new metric to quantitatively evaluate the degree of the interpolation smoothness, an aspect which is not sufficiently covered by the existing I2I translation metrics. Using both our proposed metric and standard evaluation protocols, we show that our regularization techniques can improve the state-of-the-art multi-domain I2I translations by a large margin. Our code will be made publicly available upon the acceptance of this article.
HVC-Net: Unifying Homography, Visibility, and Confidence Learning for Planar Object Tracking
Sep 19, 2022
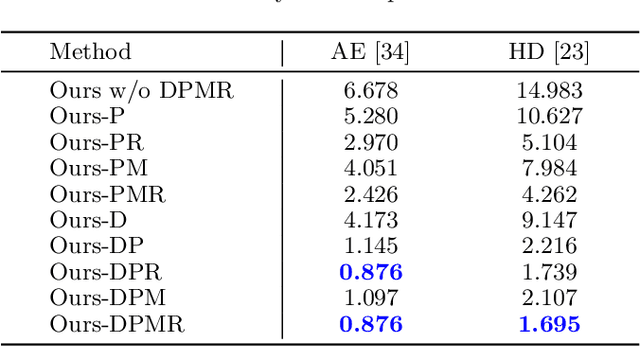


Robust and accurate planar tracking over a whole video sequence is vitally important for many vision applications. The key to planar object tracking is to find object correspondences, modeled by homography, between the reference image and the tracked image. Existing methods tend to obtain wrong correspondences with changing appearance variations, camera-object relative motions and occlusions. To alleviate this problem, we present a unified convolutional neural network (CNN) model that jointly considers homography, visibility, and confidence. First, we introduce correlation blocks that explicitly account for the local appearance changes and camera-object relative motions as the base of our model. Second, we jointly learn the homography and visibility that links camera-object relative motions with occlusions. Third, we propose a confidence module that actively monitors the estimation quality from the pixel correlation distributions obtained in correlation blocks. All these modules are plugged into a Lucas-Kanade (LK) tracking pipeline to obtain both accurate and robust planar object tracking. Our approach outperforms the state-of-the-art methods on public POT and TMT datasets. Its superior performance is also verified on a real-world application, synthesizing high-quality in-video advertisements.