 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmooth image-to-image translations with latent space interpolations
Oct 03, 2022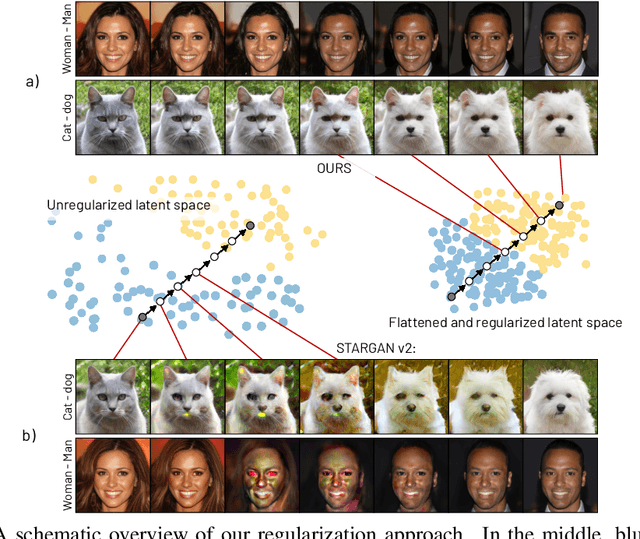
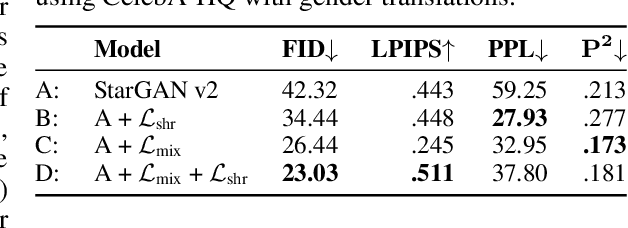
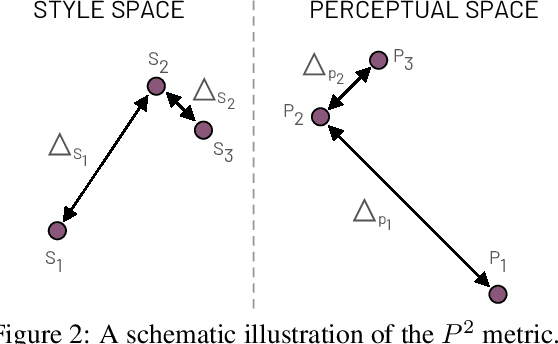
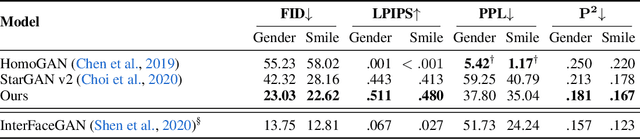
Multi-domain image-to-image (I2I) translations can transform a source image according to the style of a target domain. One important, desired characteristic of these transformations, is their graduality, which corresponds to a smooth change between the source and the target image when their respective latent-space representations are linearly interpolated. However, state-of-the-art methods usually perform poorly when evaluated using inter-domain interpolations, often producing abrupt changes in the appearance or non-realistic intermediate images. In this paper, we argue that one of the main reasons behind this problem is the lack of sufficient inter-domain training data and we propose two different regularization methods to alleviate this issue: a new shrinkage loss, which compacts the latent space, and a Mixup data-augmentation strategy, which flattens the style representations between domains. We also propose a new metric to quantitatively evaluate the degree of the interpolation smoothness, an aspect which is not sufficiently covered by the existing I2I translation metrics. Using both our proposed metric and standard evaluation protocols, we show that our regularization techniques can improve the state-of-the-art multi-domain I2I translations by a large margin. Our code will be made publicly available upon the acceptance of this article.
ISF-GAN: An Implicit Style Function for High-Resolution Image-to-Image Translation
Sep 26, 2021



Recently, there has been an increasing interest in image editing methods that employ pre-trained unconditional image generators (e.g., StyleGAN). However, applying these methods to translate images to multiple visual domains remains challenging. Existing works do not often preserve the domain-invariant part of the image (e.g., the identity in human face translations), they do not usually handle multiple domains, or do not allow for multi-modal translations. This work proposes an implicit style function (ISF) to straightforwardly achieve multi-modal and multi-domain image-to-image translation from pre-trained unconditional generators. The ISF manipulates the semantics of an input latent code to make the image generated from it lying in the desired visual domain. Our results in human face and animal manipulations show significantly improved results over the baselines. Our model enables cost-effective multi-modal unsupervised image-to-image translations at high resolution using pre-trained unconditional GANs. The code and data are available at: \url{https://github.com/yhlleo/stylegan-mmuit}.
Smoothing the Disentangled Latent Style Space for Unsupervised Image-to-Image Translation
Jun 16, 2021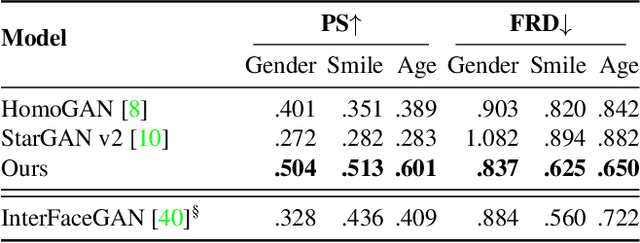
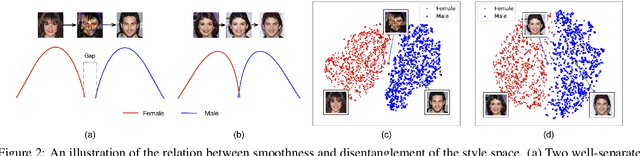
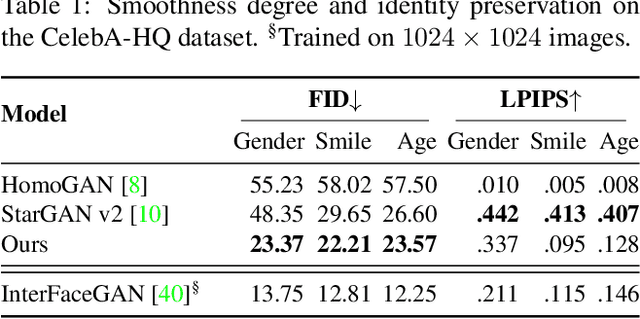

Image-to-Image (I2I) multi-domain translation models are usually evaluated also using the quality of their semantic interpolation results. However, state-of-the-art models frequently show abrupt changes in the image appearance during interpolation, and usually perform poorly in interpolations across domains. In this paper, we propose a new training protocol based on three specific losses which help a translation network to learn a smooth and disentangled latent style space in which: 1) Both intra- and inter-domain interpolations correspond to gradual changes in the generated images and 2) The content of the source image is better preserved during the translation. Moreover, we propose a novel evaluation metric to properly measure the smoothness of latent style space of I2I translation models. The proposed method can be plugged into existing translation approaches, and our extensive experiments on different datasets show that it can significantly boost the quality of the generated images and the graduality of the interpolations.
High-Fidelity 3D Digital Human Creation from RGB-D Selfies
Oct 12, 2020
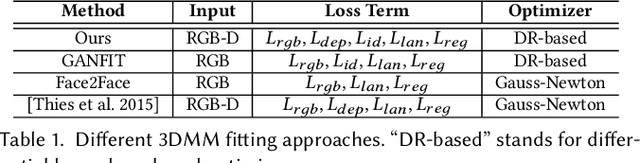
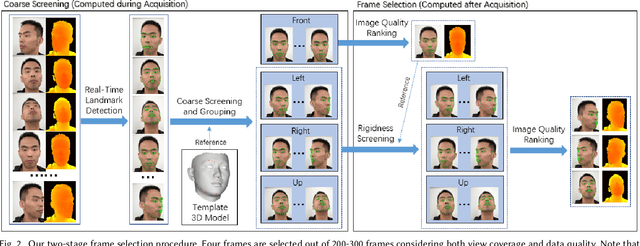

We present a fully automatic system that can produce high-fidelity, photo-realistic 3D digital human characters with a consumer RGB-D selfie camera. The system only needs the user to take a short selfie RGB-D video while rotating his/her head, and can produce a high quality reconstruction in less than 30 seconds. Our main contribution is a new facial geometry modeling and reflectance synthesis procedure that significantly improves the state-of-the-art. Specifically, given the input video a two-stage frame selection algorithm is first employed to select a few high-quality frames for reconstruction. A novel, differentiable renderer based 3D Morphable Model (3DMM) fitting method is then applied to recover facial geometries from multiview RGB-D data, which takes advantages of extensive data generation and perturbation. Our 3DMM has much larger expressive capacities than conventional 3DMM, allowing us to recover more accurate facial geometry using merely linear bases. For reflectance synthesis, we present a hybrid approach that combines parametric fitting and CNNs to synthesize high-resolution albedo/normal maps with realistic hair/pore/wrinkle details. Results show that our system can produce faithful 3D characters with extremely realistic details. Code and the constructed 3DMM is publicly available.
Self-supervised Learning of Detailed 3D Face Reconstruction
Oct 25, 2019
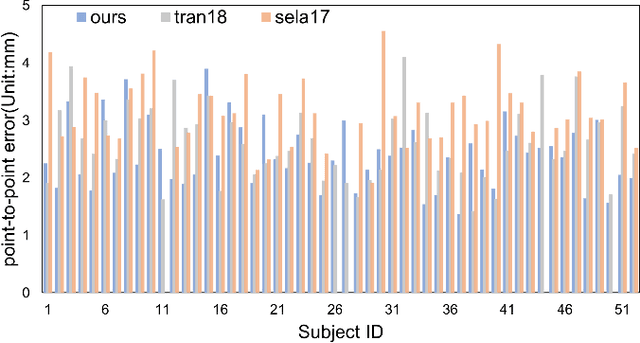
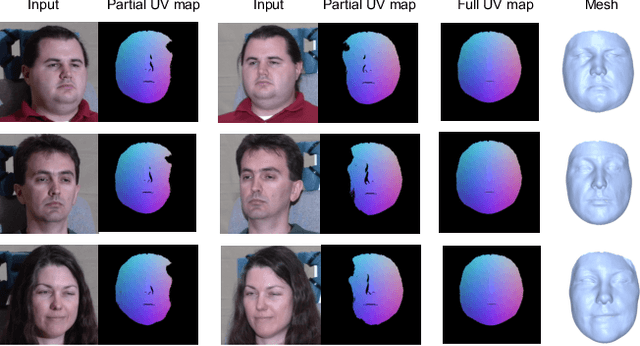

In this paper, we present an end-to-end learning framework for detailed 3D face reconstruction from a single image. Our approach uses a 3DMM-based coarse model and a displacement map in UV-space to represent a 3D face. Unlike previous work addressing the problem, our learning framework does not require supervision of surrogate ground-truth 3D models computed with traditional approaches. Instead, we utilize the input image itself as supervision during learning. In the first stage, we combine a photometric loss and a facial perceptual loss between the input face and the rendered face, to regress a 3DMM-based coarse model. In the second stage, both the input image and the regressed texture of the coarse model are unwrapped into UV-space, and then sent through an image-toimage translation network to predict a displacement map in UVspace. The displacement map and the coarse model are used to render a final detailed face, which again can be compared with the original input image to serve as a photometric loss for the second stage. The advantage of learning displacement map in UV-space is that face alignment can be explicitly done during the unwrapping, thus facial details are easier to learn from large amount of data. Extensive experiments demonstrate the superiority of the proposed method over previous work.
MVF-Net: Multi-View 3D Face Morphable Model Regression
Apr 09, 2019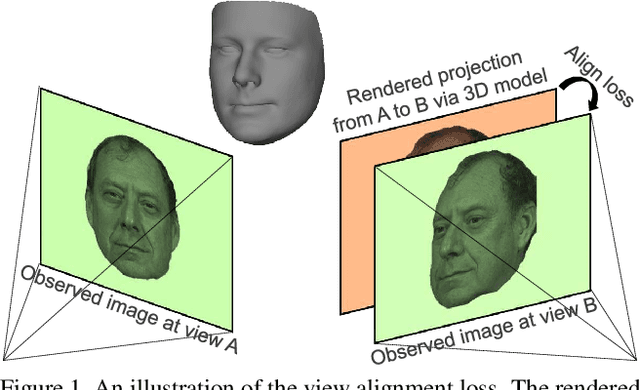
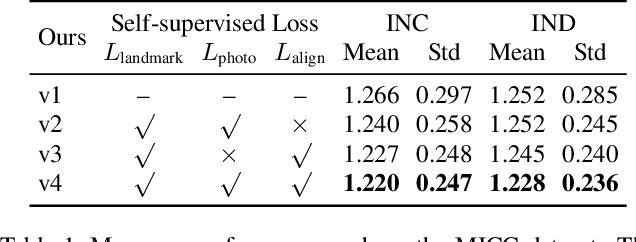
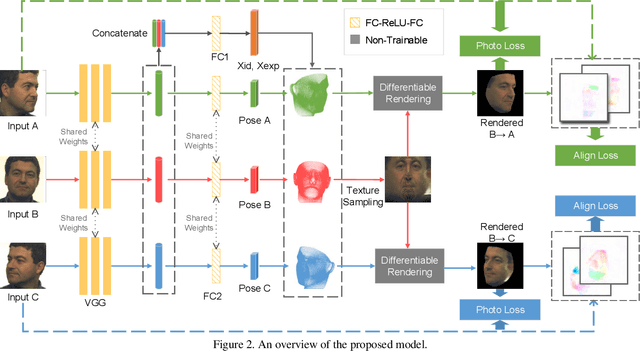
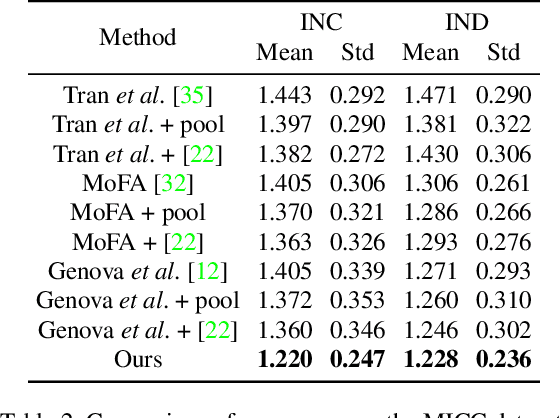
We address the problem of recovering the 3D geometry of a human face from a set of facial images in multiple views. While recent studies have shown impressive progress in 3D Morphable Model (3DMM) based facial reconstruction, the settings are mostly restricted to a single view. There is an inherent drawback in the single-view setting: the lack of reliable 3D constraints can cause unresolvable ambiguities. We in this paper explore 3DMM-based shape recovery in a different setting, where a set of multi-view facial images are given as input. A novel approach is proposed to regress 3DMM parameters from multi-view inputs with an end-to-end trainable Convolutional Neural Network (CNN). Multiview geometric constraints are incorporated into the network by establishing dense correspondences between different views leveraging a novel self-supervised view alignment loss. The main ingredient of the view alignment loss is a differentiable dense optical flow estimator that can backpropagate the alignment errors between an input view and a synthetic rendering from another input view, which is projected to the target view through the 3D shape to be inferred. Through minimizing the view alignment loss, better 3D shapes can be recovered such that the synthetic projections from one view to another can better align with the observed image. Extensive experiments demonstrate the superiority of the proposed method over other 3DMM methods.
Sketch-pix2seq: a Model to Generate Sketches of Multiple Categories
Sep 13, 2017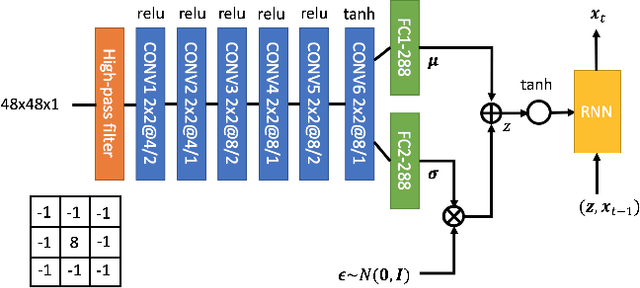


Sketch is an important media for human to communicate ideas, which reflects the superiority of human intelligence. Studies on sketch can be roughly summarized into recognition and generation. Existing models on image recognition failed to obtain satisfying performance on sketch classification. But for sketch generation, a recent study proposed a sequence-to-sequence variational-auto-encoder (VAE) model called sketch-rnn which was able to generate sketches based on human inputs. The model achieved amazing results when asked to learn one category of object, such as an animal or a vehicle. However, the performance dropped when multiple categories were fed into the model. Here, we proposed a model called sketch-pix2seq which could learn and draw multiple categories of sketches. Two modifications were made to improve the sketch-rnn model: one is to replace the bidirectional recurrent neural network (BRNN) encoder with a convolutional neural network(CNN); the other is to remove the Kullback-Leibler divergence from the objective function of VAE. Experimental results showed that models with CNN encoders outperformed those with RNN encoders in generating human-style sketches. Visualization of the latent space illustrated that the removal of KL-divergence made the encoder learn a posterior of latent space that reflected the features of different categories. Moreover, the combination of CNN encoder and removal of KL-divergence, i.e., the sketch-pix2seq model, had better performance in learning and generating sketches of multiple categories and showed promising results in creativity tasks.