 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkinned Motion Retargeting with Residual Perception of Motion Semantics & Geometry
Mar 15, 2023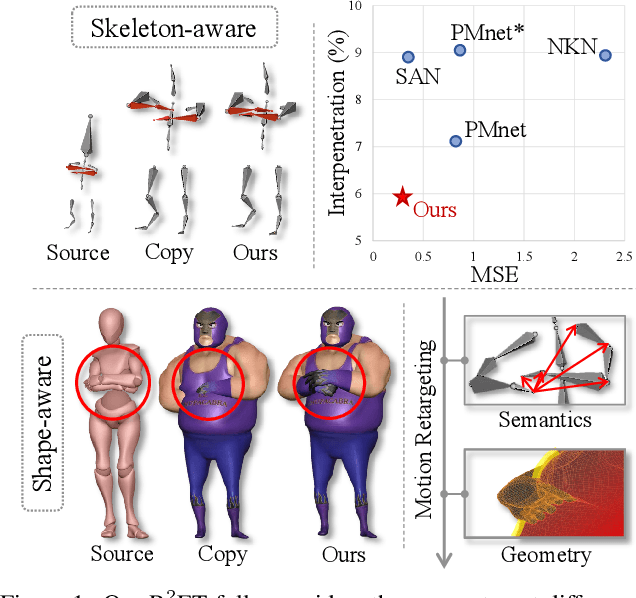
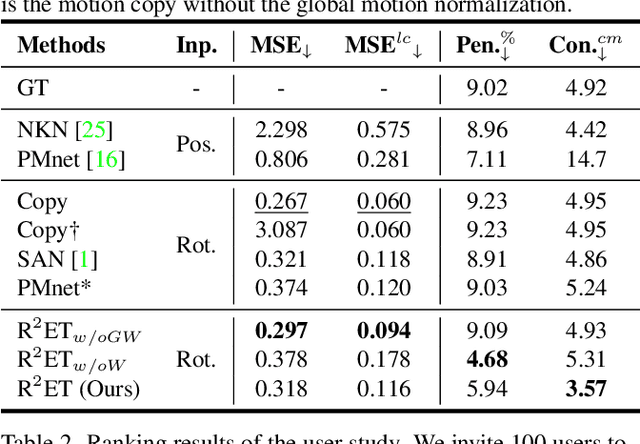
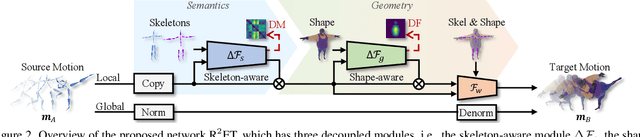
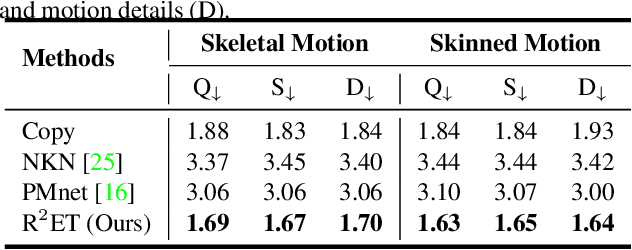
A good motion retargeting cannot be reached without reasonable consideration of source-target differences on both the skeleton and shape geometry levels. In this work, we propose a novel Residual RETargeting network (R2ET) structure, which relies on two neural modification modules, to adjust the source motions to fit the target skeletons and shapes progressively. In particular, a skeleton-aware module is introduced to preserve the source motion semantics. A shape-aware module is designed to perceive the geometries of target characters to reduce interpenetration and contact-missing. Driven by our explored distance-based losses that explicitly model the motion semantics and geometry, these two modules can learn residual motion modifications on the source motion to generate plausible retargeted motion in a single inference without post-processing. To balance these two modifications, we further present a balancing gate to conduct linear interpolation between them. Extensive experiments on the public dataset Mixamo demonstrate that our R2ET achieves the state-of-the-art performance, and provides a good balance between the preservation of motion semantics as well as the attenuation of interpenetration and contact-missing. Code is available at https://github.com/Kebii/R2ET.
Audio2Gestures: Generating Diverse Gestures from Audio
Jan 17, 2023

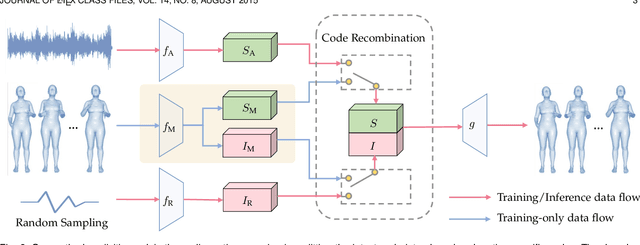

People may perform diverse gestures affected by various mental and physical factors when speaking the same sentences. This inherent one-to-many relationship makes co-speech gesture generation from audio particularly challenging. Conventional CNNs/RNNs assume one-to-one mapping, and thus tend to predict the average of all possible target motions, easily resulting in plain/boring motions during inference. So we propose to explicitly model the one-to-many audio-to-motion mapping by splitting the cross-modal latent code into shared code and motion-specific code. The shared code is expected to be responsible for the motion component that is more correlated to the audio while the motion-specific code is expected to capture diverse motion information that is more independent of the audio. However, splitting the latent code into two parts poses extra training difficulties. Several crucial training losses/strategies, including relaxed motion loss, bicycle constraint, and diversity loss, are designed to better train the VAE. Experiments on both 3D and 2D motion datasets verify that our method generates more realistic and diverse motions than previous state-of-the-art methods, quantitatively and qualitatively. Besides, our formulation is compatible with discrete cosine transformation (DCT) modeling and other popular backbones (\textit{i.e.} RNN, Transformer). As for motion losses and quantitative motion evaluation, we find structured losses/metrics (\textit{e.g.} STFT) that consider temporal and/or spatial context complement the most commonly used point-wise losses (\textit{e.g.} PCK), resulting in better motion dynamics and more nuanced motion details. Finally, we demonstrate that our method can be readily used to generate motion sequences with user-specified motion clips on the timeline.
Learning Audio-Driven Viseme Dynamics for 3D Face Animation
Jan 15, 2023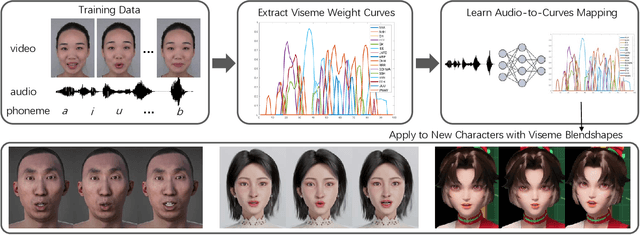
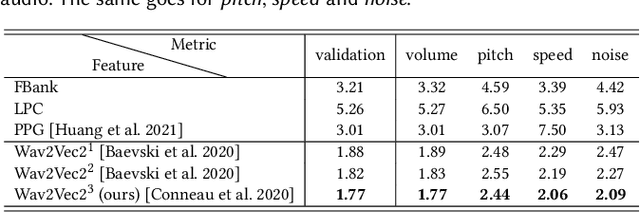
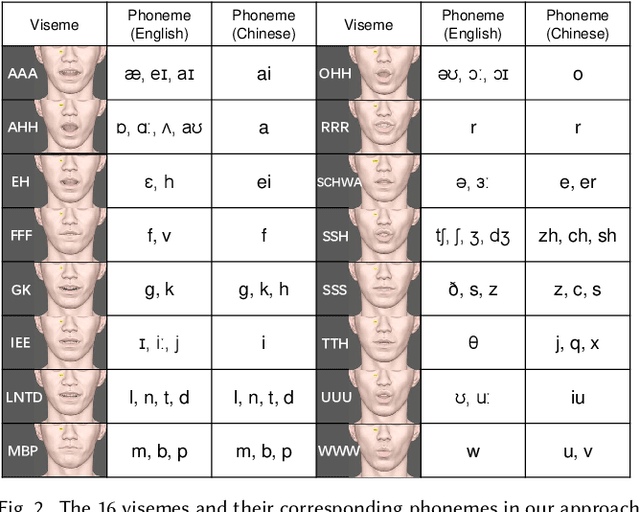
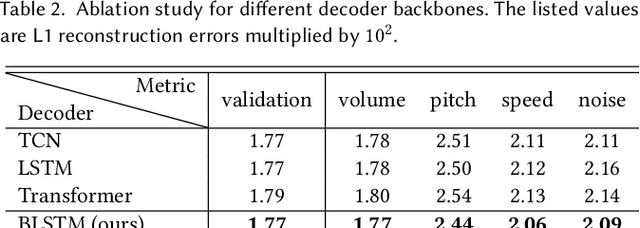
We present a novel audio-driven facial animation approach that can generate realistic lip-synchronized 3D facial animations from the input audio. Our approach learns viseme dynamics from speech videos, produces animator-friendly viseme curves, and supports multilingual speech inputs. The core of our approach is a novel parametric viseme fitting algorithm that utilizes phoneme priors to extract viseme parameters from speech videos. With the guidance of phonemes, the extracted viseme curves can better correlate with phonemes, thus more controllable and friendly to animators. To support multilingual speech inputs and generalizability to unseen voices, we take advantage of deep audio feature models pretrained on multiple languages to learn the mapping from audio to viseme curves. Our audio-to-curves mapping achieves state-of-the-art performance even when the input audio suffers from distortions of volume, pitch, speed, or noise. Lastly, a viseme scanning approach for acquiring high-fidelity viseme assets is presented for efficient speech animation production. We show that the predicted viseme curves can be applied to different viseme-rigged characters to yield various personalized animations with realistic and natural facial motions. Our approach is artist-friendly and can be easily integrated into typical animation production workflows including blendshape or bone based animation.
CARD: Semantic Segmentation with Efficient Class-Aware Regularized Decoder
Jan 11, 2023
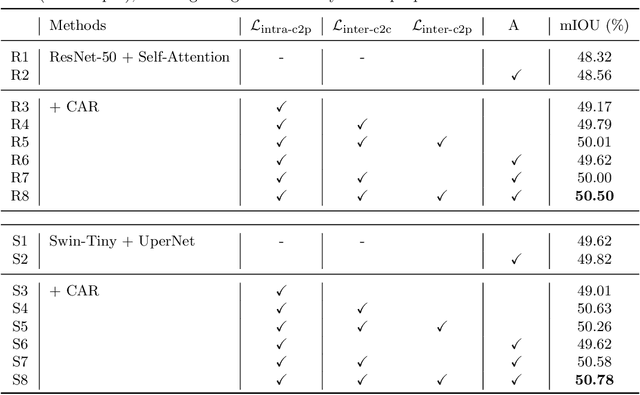
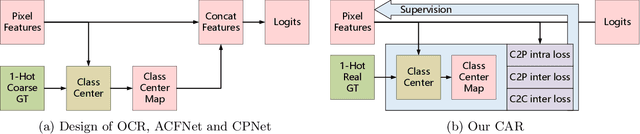
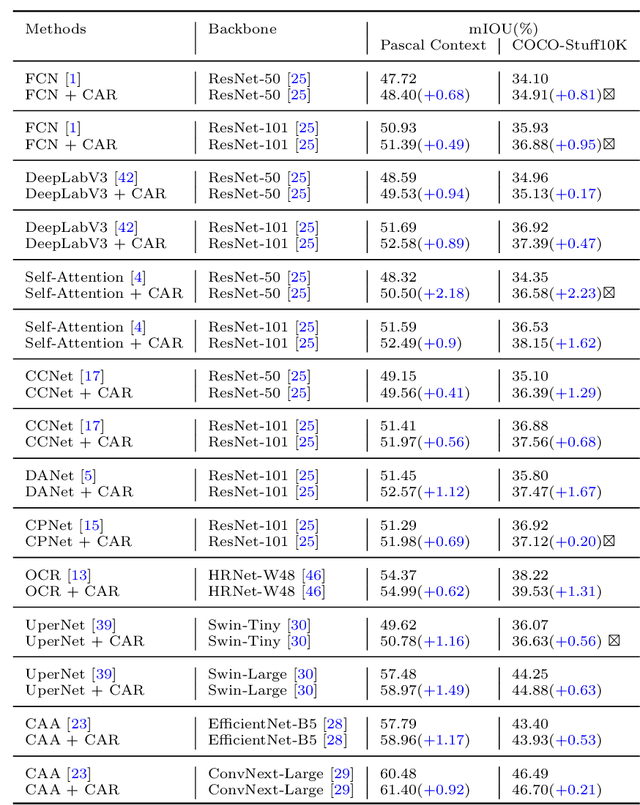
Semantic segmentation has recently achieved notable advances by exploiting "class-level" contextual information during learning. However, these approaches simply concatenate class-level information to pixel features to boost the pixel representation learning, which cannot fully utilize intra-class and inter-class contextual information. Moreover, these approaches learn soft class centers based on coarse mask prediction, which is prone to error accumulation. To better exploit class level information, we propose a universal Class-Aware Regularization (CAR) approach to optimize the intra-class variance and inter-class distance during feature learning, motivated by the fact that humans can recognize an object by itself no matter which other objects it appears with. Moreover, we design a dedicated decoder for CAR (CARD), which consists of a novel spatial token mixer and an upsampling module, to maximize its gain for existing baselines while being highly efficient in terms of computational cost. Specifically, CAR consists of three novel loss functions. The first loss function encourages more compact class representations within each class, the second directly maximizes the distance between different class centers, and the third further pushes the distance between inter-class centers and pixels. Furthermore, the class center in our approach is directly generated from ground truth instead of from the error-prone coarse prediction. CAR can be directly applied to most existing segmentation models during training, and can largely improve their accuracy at no additional inference overhead. Extensive experiments and ablation studies conducted on multiple benchmark datasets demonstrate that the proposed CAR can boost the accuracy of all baseline models by up to 2.23% mIOU with superior generalization ability. CARD outperforms SOTA approaches on multiple benchmarks with a highly efficient architecture.
NEURAL MARIONETTE: A Transformer-based Multi-action Human Motion Synthesis System
Sep 27, 2022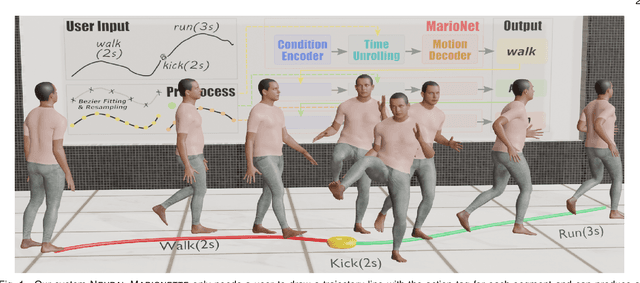
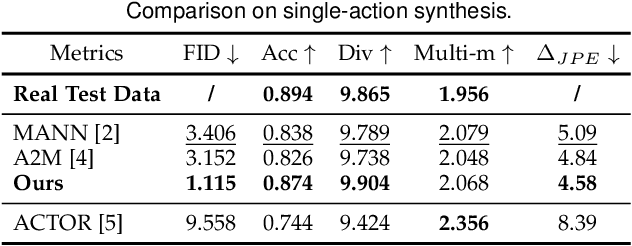

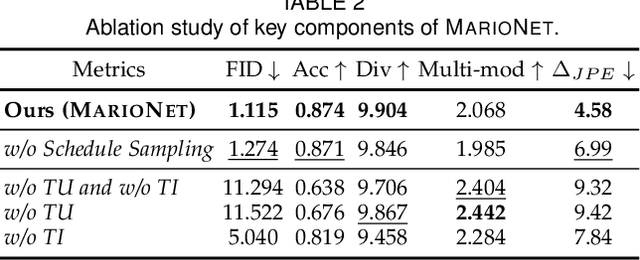
We present a neural network-based system for long-term, multi-action human motion synthesis. The system, dubbed as NEURAL MARIONETTE, can produce high-quality and meaningful motions with smooth transitions from simple user input, including a sequence of action tags with expected action duration, and optionally a hand-drawn moving trajectory if the user specifies. The core of our system is a novel Transformer-based motion generation model, namely MARIONET, which can generate diverse motions given action tags. Different from existing motion generation models, MARIONET utilizes contextual information from the past motion clip and future action tag, dedicated to generating actions that can smoothly blend historical and future actions. Specifically, MARIONET first encodes target action tag and contextual information into an action-level latent code. The code is unfolded into frame-level control signals via a time unrolling module, which could be then combined with other frame-level control signals like the target trajectory. Motion frames are then generated in an auto-regressive way. By sequentially applying MARIONET, the system NEURAL MARIONETTE can robustly generate long-term, multi-action motions with the help of two simple schemes, namely "Shadow Start" and "Action Revision". Along with the novel system, we also present a new dataset dedicated to the multi-action motion synthesis task, which contains both action tags and their contextual information. Extensive experiments are conducted to study the action accuracy, naturalism, and transition smoothness of the motions generated by our system.
Learning to Construct 3D Building Wireframes from 3D Line Clouds
Aug 25, 2022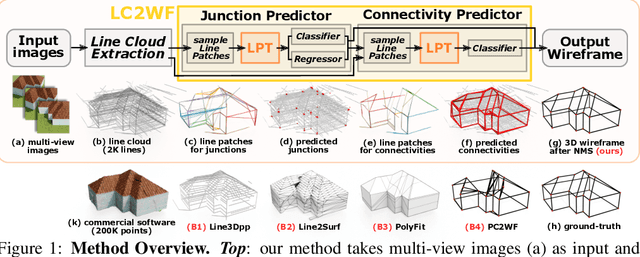
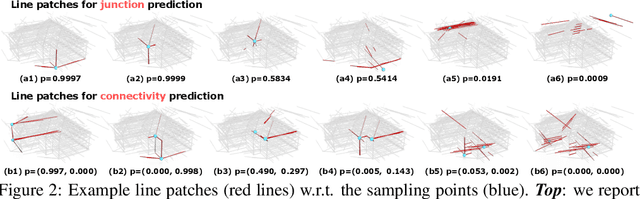

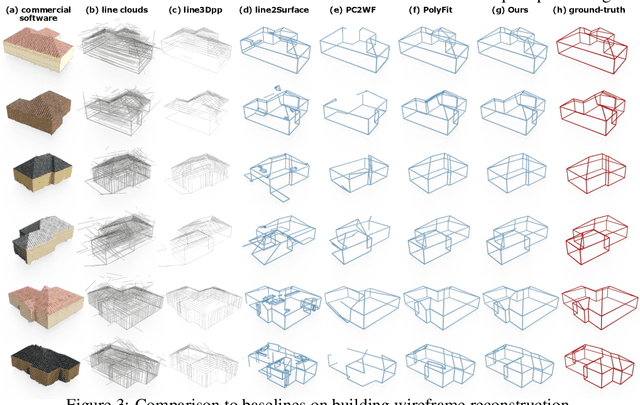
Line clouds, though under-investigated in the previous work, potentially encode more compact structural information of buildings than point clouds extracted from multi-view images. In this work, we propose the first network to process line clouds for building wireframe abstraction. The network takes a line cloud as input , i.e., a nonstructural and unordered set of 3D line segments extracted from multi-view images, and outputs a 3D wireframe of the underlying building, which consists of a sparse set of 3D junctions connected by line segments. We observe that a line patch, i.e., a group of neighboring line segments, encodes sufficient contour information to predict the existence and even the 3D position of a potential junction, as well as the likelihood of connectivity between two query junctions. We therefore introduce a two-layer Line-Patch Transformer to extract junctions and connectivities from sampled line patches to form a 3D building wireframe model. We also introduce a synthetic dataset of multi-view images with ground-truth 3D wireframe. We extensively justify that our reconstructed 3D wireframe models significantly improve upon multiple baseline building reconstruction methods.
Semi-signed neural fitting for surface reconstruction from unoriented point clouds
Jun 14, 2022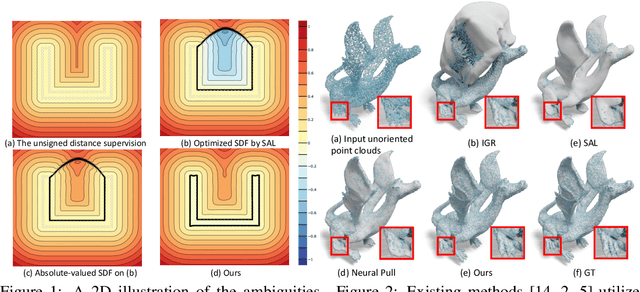
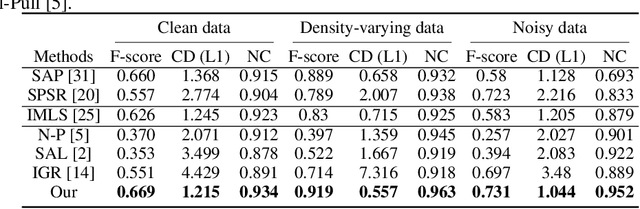
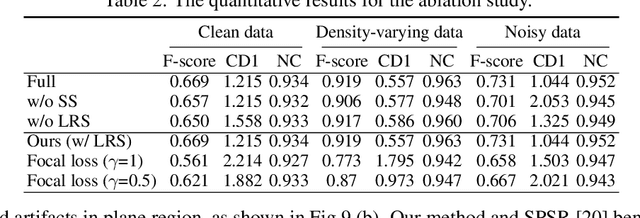
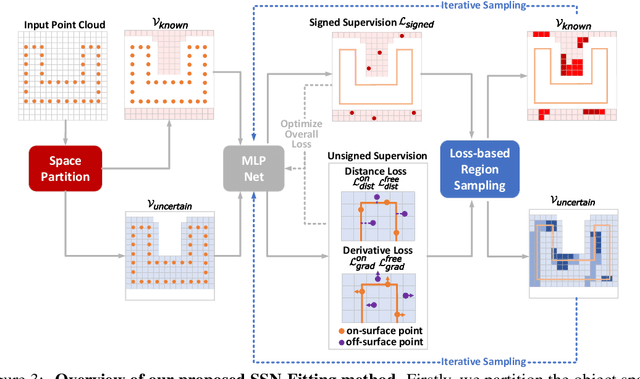
Reconstructing 3D geometry from \emph{unoriented} point clouds can benefit many downstream tasks. Recent methods mostly adopt a neural shape representation with a neural network to represent a signed distance field and fit the point cloud with an unsigned supervision. However, we observe that using unsigned supervision may cause severe ambiguities and often leads to \emph{unexpected} failures such as generating undesired surfaces in free space when reconstructing complex structures and struggle with reconstructing accurate surfaces. To reconstruct a better signed distance field, we propose semi-signed neural fitting (SSN-Fitting), which consists of a semi-signed supervision and a loss-based region sampling strategy. Our key insight is that signed supervision is more informative and regions that are obviously outside the object can be easily determined. Meanwhile, a novel importance sampling is proposed to accelerate the optimization and better reconstruct the fine details. Specifically, we voxelize and partition the object space into \emph{sign-known} and \emph{sign-uncertain} regions, in which different supervisions are applied. Also, we adaptively adjust the sampling rate of each voxel according to the tracked reconstruction loss, so that the network can focus more on the complex under-fitting regions. We conduct extensive experiments to demonstrate that SSN-Fitting achieves state-of-the-art performance under different settings on multiple datasets, including clean, density-varying, and noisy data.
WarpingGAN: Warping Multiple Uniform Priors for Adversarial 3D Point Cloud Generation
Mar 24, 2022We propose WarpingGAN, an effective and efficient 3D point cloud generation network. Unlike existing methods that generate point clouds by directly learning the mapping functions between latent codes and 3D shapes, Warping-GAN learns a unified local-warping function to warp multiple identical pre-defined priors (i.e., sets of points uniformly distributed on regular 3D grids) into 3D shapes driven by local structure-aware semantics. In addition, we also ingeniously utilize the principle of the discriminator and tailor a stitching loss to eliminate the gaps between different partitions of a generated shape corresponding to different priors for boosting quality. Owing to the novel generating mechanism, WarpingGAN, a single lightweight network after one-time training, is capable of efficiently generating uniformly distributed 3D point clouds with various resolutions. Extensive experimental results demonstrate the superiority of our WarpingGAN over state-of-the-art methods in terms of quantitative metrics, visual quality, and efficiency. The source code is publicly available at https://github.com/yztang4/WarpingGAN.git.
REALY: Rethinking the Evaluation of 3D Face Reconstruction
Mar 18, 2022

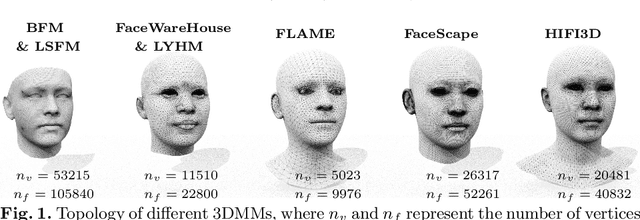
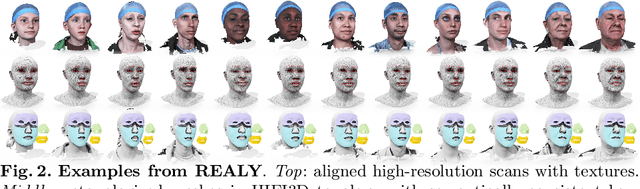
The evaluation of 3D face reconstruction results typically relies on a rigid shape alignment between the estimated 3D model and the ground-truth scan. We observe that aligning two shapes with different reference points can largely affect the evaluation results. This poses difficulties for precisely diagnosing and improving a 3D face reconstruction method. In this paper, we propose a novel evaluation approach with a new benchmark REALY, consists of 100 globally aligned face scans with accurate facial keypoints, high-quality region masks, and topology-consistent meshes. Our approach performs region-wise shape alignment and leads to more accurate, bidirectional correspondences during computing the shape errors. The fine-grained, region-wise evaluation results provide us detailed understandings about the performance of state-of-the-art 3D face reconstruction methods. For example, our experiments on single-image based reconstruction methods reveal that DECA performs the best on nose regions, while GANFit performs better on cheek regions. Besides, a new and high-quality 3DMM basis, HIFI3D++, is further derived using the same procedure as we construct REALY to align and retopologize several 3D face datasets. We will release REALY, HIFI3D++, and our new evaluation pipeline at https://realy3dface.com.
CAR: Class-aware Regularizations for Semantic Segmentation
Mar 14, 2022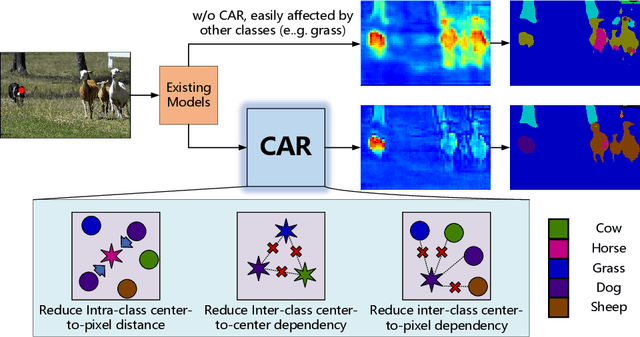



Recent segmentation methods, such as OCR and CPNet, utilizing "class level" information in addition to pixel features, have achieved notable success for boosting the accuracy of existing network modules. However, the extracted class-level information was simply concatenated to pixel features, without explicitly being exploited for better pixel representation learning. Moreover, these approaches learn soft class centers based on coarse mask prediction, which is prone to error accumulation. In this paper, aiming to use class level information more effectively, we propose a universal Class-Aware Regularization (CAR) approach to optimize the intra-class variance and inter-class distance during feature learning, motivated by the fact that humans can recognize an object by itself no matter which other objects it appears with. Three novel loss functions are proposed. The first loss function encourages more compact class representations within each class, the second directly maximizes the distance between different class centers, and the third further pushes the distance between inter-class centers and pixels. Furthermore, the class center in our approach is directly generated from ground truth instead of from the error-prone coarse prediction. Our method can be easily applied to most existing segmentation models during training, including OCR and CPNet, and can largely improve their accuracy at no additional inference overhead. Extensive experiments and ablation studies conducted on multiple benchmark datasets demonstrate that the proposed CAR can boost the accuracy of all baseline models by up to 2.23% mIOU with superior generalization ability. The complete code is available at https://github.com/edwardyehuang/CAR.