 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemocratizing High-Fidelity Co-Speech Gesture Video Generation
Jul 09, 2025Co-speech gesture video generation aims to synthesize realistic, audio-aligned videos of speakers, complete with synchronized facial expressions and body gestures. This task presents challenges due to the significant one-to-many mapping between audio and visual content, further complicated by the scarcity of large-scale public datasets and high computational demands. We propose a lightweight framework that utilizes 2D full-body skeletons as an efficient auxiliary condition to bridge audio signals with visual outputs. Our approach introduces a diffusion model conditioned on fine-grained audio segments and a skeleton extracted from the speaker's reference image, predicting skeletal motions through skeleton-audio feature fusion to ensure strict audio coordination and body shape consistency. The generated skeletons are then fed into an off-the-shelf human video generation model with the speaker's reference image to synthesize high-fidelity videos. To democratize research, we present CSG-405-the first public dataset with 405 hours of high-resolution videos across 71 speech types, annotated with 2D skeletons and diverse speaker demographics. Experiments show that our method exceeds state-of-the-art approaches in visual quality and synchronization while generalizing across speakers and contexts.
Bilateral Collaboration with Large Vision-Language Models for Open Vocabulary Human-Object Interaction Detection
Jul 09, 2025Open vocabulary Human-Object Interaction (HOI) detection is a challenging task that detects all <human, verb, object> triplets of interest in an image, even those that are not pre-defined in the training set. Existing approaches typically rely on output features generated by large Vision-Language Models (VLMs) to enhance the generalization ability of interaction representations. However, the visual features produced by VLMs are holistic and coarse-grained, which contradicts the nature of detection tasks. To address this issue, we propose a novel Bilateral Collaboration framework for open vocabulary HOI detection (BC-HOI). This framework includes an Attention Bias Guidance (ABG) component, which guides the VLM to produce fine-grained instance-level interaction features according to the attention bias provided by the HOI detector. It also includes a Large Language Model (LLM)-based Supervision Guidance (LSG) component, which provides fine-grained token-level supervision for the HOI detector by the LLM component of the VLM. LSG enhances the ability of ABG to generate high-quality attention bias. We conduct extensive experiments on two popular benchmarks: HICO-DET and V-COCO, consistently achieving superior performance in the open vocabulary and closed settings. The code will be released in Github.
Guiding Human-Object Interactions with Rich Geometry and Relations
Mar 26, 2025Human-object interaction (HOI) synthesis is crucial for creating immersive and realistic experiences for applications such as virtual reality. Existing methods often rely on simplified object representations, such as the object's centroid or the nearest point to a human, to achieve physically plausible motions. However, these approaches may overlook geometric complexity, resulting in suboptimal interaction fidelity. To address this limitation, we introduce ROG, a novel diffusion-based framework that models the spatiotemporal relationships inherent in HOIs with rich geometric detail. For efficient object representation, we select boundary-focused and fine-detail key points from the object mesh, ensuring a comprehensive depiction of the object's geometry. This representation is used to construct an interactive distance field (IDF), capturing the robust HOI dynamics. Furthermore, we develop a diffusion-based relation model that integrates spatial and temporal attention mechanisms, enabling a better understanding of intricate HOI relationships. This relation model refines the generated motion's IDF, guiding the motion generation process to produce relation-aware and semantically aligned movements. Experimental evaluations demonstrate that ROG significantly outperforms state-of-the-art methods in the realism and semantic accuracy of synthesized HOIs.
HoloGest: Decoupled Diffusion and Motion Priors for Generating Holisticly Expressive Co-speech Gestures
Mar 17, 2025



Animating virtual characters with holistic co-speech gestures is a challenging but critical task. Previous systems have primarily focused on the weak correlation between audio and gestures, leading to physically unnatural outcomes that degrade the user experience. To address this problem, we introduce HoleGest, a novel neural network framework based on decoupled diffusion and motion priors for the automatic generation of high-quality, expressive co-speech gestures. Our system leverages large-scale human motion datasets to learn a robust prior with low audio dependency and high motion reliance, enabling stable global motion and detailed finger movements. To improve the generation efficiency of diffusion-based models, we integrate implicit joint constraints with explicit geometric and conditional constraints, capturing complex motion distributions between large strides. This integration significantly enhances generation speed while maintaining high-quality motion. Furthermore, we design a shared embedding space for gesture-transcription text alignment, enabling the generation of semantically correct gesture actions. Extensive experiments and user feedback demonstrate the effectiveness and potential applications of our model, with our method achieving a level of realism close to the ground truth, providing an immersive user experience. Our code, model, and demo are are available at https://cyk990422.github.io/HoloGest.github.io/.
RopeTP: Global Human Motion Recovery via Integrating Robust Pose Estimation with Diffusion Trajectory Prior
Oct 27, 2024



We present RopeTP, a novel framework that combines Robust pose estimation with a diffusion Trajectory Prior to reconstruct global human motion from videos. At the heart of RopeTP is a hierarchical attention mechanism that significantly improves context awareness, which is essential for accurately inferring the posture of occluded body parts. This is achieved by exploiting the relationships with visible anatomical structures, enhancing the accuracy of local pose estimations. The improved robustness of these local estimations allows for the reconstruction of precise and stable global trajectories. Additionally, RopeTP incorporates a diffusion trajectory model that predicts realistic human motion from local pose sequences. This model ensures that the generated trajectories are not only consistent with observed local actions but also unfold naturally over time, thereby improving the realism and stability of 3D human motion reconstruction. Extensive experimental validation shows that RopeTP surpasses current methods on two benchmark datasets, particularly excelling in scenarios with occlusions. It also outperforms methods that rely on SLAM for initial camera estimates and extensive optimization, delivering more accurate and realistic trajectories.
Conditional GAN for Enhancing Diffusion Models in Efficient and Authentic Global Gesture Generation from Audios
Oct 27, 2024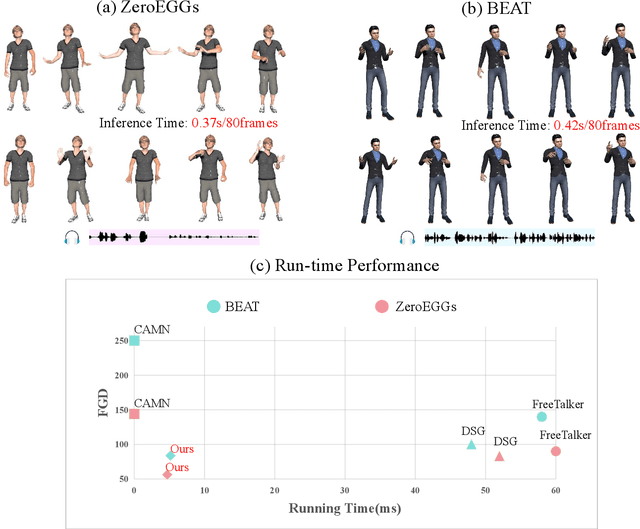

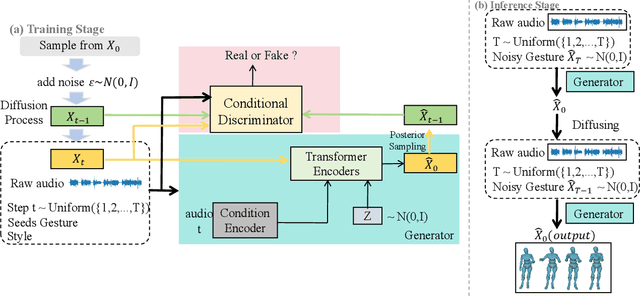

Audio-driven simultaneous gesture generation is vital for human-computer communication, AI games, and film production. While previous research has shown promise, there are still limitations. Methods based on VAEs are accompanied by issues of local jitter and global instability, whereas methods based on diffusion models are hampered by low generation efficiency. This is because the denoising process of DDPM in the latter relies on the assumption that the noise added at each step is sampled from a unimodal distribution, and the noise values are small. DDIM borrows the idea from the Euler method for solving differential equations, disrupts the Markov chain process, and increases the noise step size to reduce the number of denoising steps, thereby accelerating generation. However, simply increasing the step size during the step-by-step denoising process causes the results to gradually deviate from the original data distribution, leading to a significant drop in the quality of the generated actions and the emergence of unnatural artifacts. In this paper, we break the assumptions of DDPM and achieves breakthrough progress in denoising speed and fidelity. Specifically, we introduce a conditional GAN to capture audio control signals and implicitly match the multimodal denoising distribution between the diffusion and denoising steps within the same sampling step, aiming to sample larger noise values and apply fewer denoising steps for high-speed generation.
ExpGest: Expressive Speaker Generation Using Diffusion Model and Hybrid Audio-Text Guidance
Oct 12, 2024



Existing gesture generation methods primarily focus on upper body gestures based on audio features, neglecting speech content, emotion, and locomotion. These limitations result in stiff, mechanical gestures that fail to convey the true meaning of audio content. We introduce ExpGest, a novel framework leveraging synchronized text and audio information to generate expressive full-body gestures. Unlike AdaIN or one-hot encoding methods, we design a noise emotion classifier for optimizing adversarial direction noise, avoiding melody distortion and guiding results towards specified emotions. Moreover, aligning semantic and gestures in the latent space provides better generalization capabilities. ExpGest, a diffusion model-based gesture generation framework, is the first attempt to offer mixed generation modes, including audio-driven gestures and text-shaped motion. Experiments show that our framework effectively learns from combined text-driven motion and audio-induced gesture datasets, and preliminary results demonstrate that ExpGest achieves more expressive, natural, and controllable global motion in speakers compared to state-of-the-art models.
ReinDiffuse: Crafting Physically Plausible Motions with Reinforced Diffusion Model
Oct 09, 2024



Generating human motion from textual descriptions is a challenging task. Existing methods either struggle with physical credibility or are limited by the complexities of physics simulations. In this paper, we present \emph{ReinDiffuse} that combines reinforcement learning with motion diffusion model to generate physically credible human motions that align with textual descriptions. Our method adapts Motion Diffusion Model to output a parameterized distribution of actions, making them compatible with reinforcement learning paradigms. We employ reinforcement learning with the objective of maximizing physically plausible rewards to optimize motion generation for physical fidelity. Our approach outperforms existing state-of-the-art models on two major datasets, HumanML3D and KIT-ML, achieving significant improvements in physical plausibility and motion quality. Project: \url{https://reindiffuse.github.io/}
CT4D: Consistent Text-to-4D Generation with Animatable Meshes
Aug 15, 2024

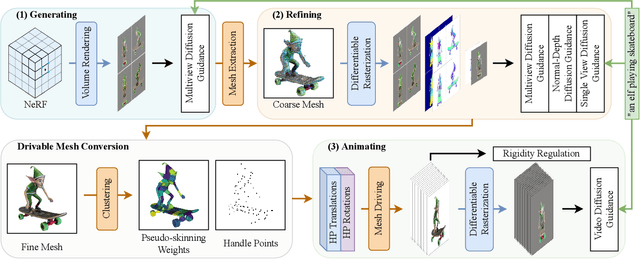

Text-to-4D generation has recently been demonstrated viable by integrating a 2D image diffusion model with a video diffusion model. However, existing models tend to produce results with inconsistent motions and geometric structures over time. To this end, we present a novel framework, coined CT4D, which directly operates on animatable meshes for generating consistent 4D content from arbitrary user-supplied prompts. The primary challenges of our mesh-based framework involve stably generating a mesh with details that align with the text prompt while directly driving it and maintaining surface continuity. Our CT4D framework incorporates a unique Generate-Refine-Animate (GRA) algorithm to enhance the creation of text-aligned meshes. To improve surface continuity, we divide a mesh into several smaller regions and implement a uniform driving function within each area. Additionally, we constrain the animating stage with a rigidity regulation to ensure cross-region continuity. Our experimental results, both qualitative and quantitative, demonstrate that our CT4D framework surpasses existing text-to-4D techniques in maintaining interframe consistency and preserving global geometry. Furthermore, we showcase that this enhanced representation inherently possesses the capability for combinational 4D generation and texture editing.
GrootVL: Tree Topology is All You Need in State Space Model
Jun 04, 2024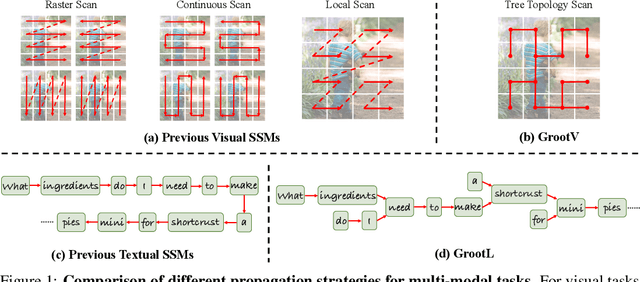
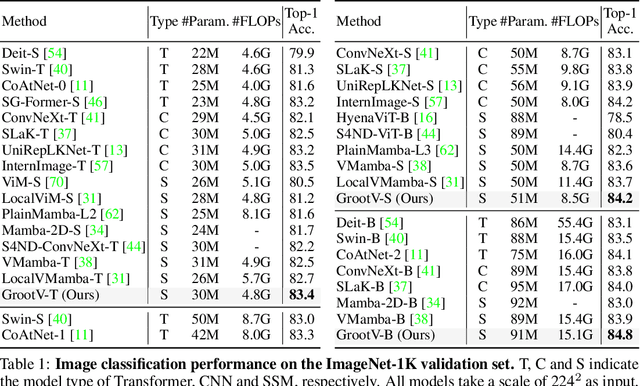
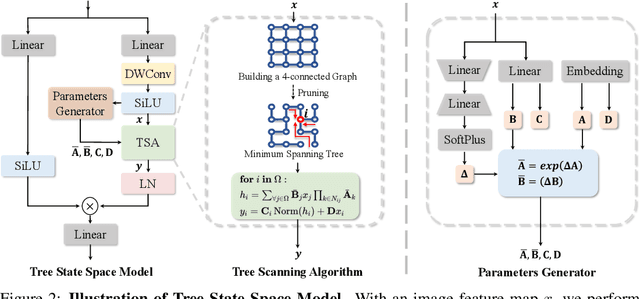
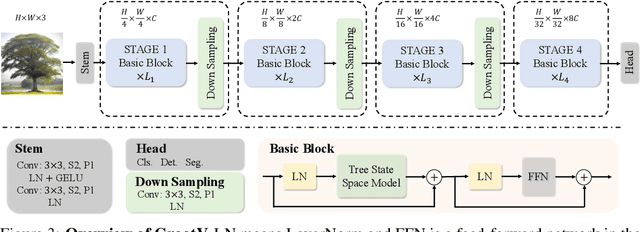
The state space models, employing recursively propagated features, demonstrate strong representation capabilities comparable to Transformer models and superior efficiency. However, constrained by the inherent geometric constraints of sequences, it still falls short in modeling long-range dependencies. To address this issue, we propose the GrootVL network, which first dynamically generates a tree topology based on spatial relationships and input features. Then, feature propagation is performed based on this graph, thereby breaking the original sequence constraints to achieve stronger representation capabilities. Additionally, we introduce a linear complexity dynamic programming algorithm to enhance long-range interactions without increasing computational cost. GrootVL is a versatile multimodal framework that can be applied to both visual and textual tasks. Extensive experiments demonstrate that our method significantly outperforms existing structured state space models on image classification, object detection and segmentation. Besides, by fine-tuning large language models, our approach achieves consistent improvements in multiple textual tasks at minor training cost.