 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInter-Diffusion Generation Model of Speakers and Listeners for Effective Communication
May 08, 2025Full-body gestures play a pivotal role in natural interactions and are crucial for achieving effective communication. Nevertheless, most existing studies primarily focus on the gesture generation of speakers, overlooking the vital role of listeners in the interaction process and failing to fully explore the dynamic interaction between them. This paper innovatively proposes an Inter-Diffusion Generation Model of Speakers and Listeners for Effective Communication. For the first time, we integrate the full-body gestures of listeners into the generation framework. By devising a novel inter-diffusion mechanism, this model can accurately capture the complex interaction patterns between speakers and listeners during communication. In the model construction process, based on the advanced diffusion model architecture, we innovatively introduce interaction conditions and the GAN model to increase the denoising step size. As a result, when generating gesture sequences, the model can not only dynamically generate based on the speaker's speech information but also respond in realtime to the listener's feedback, enabling synergistic interaction between the two. Abundant experimental results demonstrate that compared with the current state-of-the-art gesture generation methods, the model we proposed has achieved remarkable improvements in the naturalness, coherence, and speech-gesture synchronization of the generated gestures. In the subjective evaluation experiments, users highly praised the generated interaction scenarios, believing that they are closer to real life human communication situations. Objective index evaluations also show that our model outperforms the baseline methods in multiple key indicators, providing more powerful support for effective communication.
Conditional GAN for Enhancing Diffusion Models in Efficient and Authentic Global Gesture Generation from Audios
Oct 27, 2024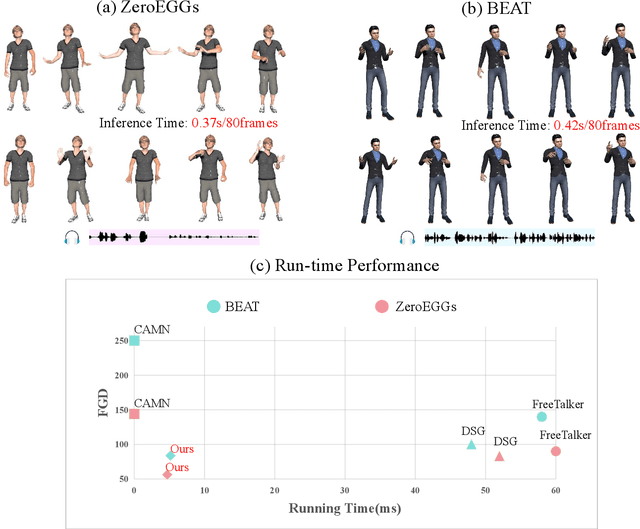

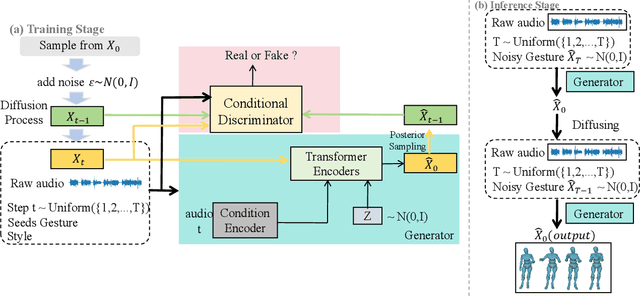

Audio-driven simultaneous gesture generation is vital for human-computer communication, AI games, and film production. While previous research has shown promise, there are still limitations. Methods based on VAEs are accompanied by issues of local jitter and global instability, whereas methods based on diffusion models are hampered by low generation efficiency. This is because the denoising process of DDPM in the latter relies on the assumption that the noise added at each step is sampled from a unimodal distribution, and the noise values are small. DDIM borrows the idea from the Euler method for solving differential equations, disrupts the Markov chain process, and increases the noise step size to reduce the number of denoising steps, thereby accelerating generation. However, simply increasing the step size during the step-by-step denoising process causes the results to gradually deviate from the original data distribution, leading to a significant drop in the quality of the generated actions and the emergence of unnatural artifacts. In this paper, we break the assumptions of DDPM and achieves breakthrough progress in denoising speed and fidelity. Specifically, we introduce a conditional GAN to capture audio control signals and implicitly match the multimodal denoising distribution between the diffusion and denoising steps within the same sampling step, aiming to sample larger noise values and apply fewer denoising steps for high-speed generation.
ReinDiffuse: Crafting Physically Plausible Motions with Reinforced Diffusion Model
Oct 09, 2024



Generating human motion from textual descriptions is a challenging task. Existing methods either struggle with physical credibility or are limited by the complexities of physics simulations. In this paper, we present \emph{ReinDiffuse} that combines reinforcement learning with motion diffusion model to generate physically credible human motions that align with textual descriptions. Our method adapts Motion Diffusion Model to output a parameterized distribution of actions, making them compatible with reinforcement learning paradigms. We employ reinforcement learning with the objective of maximizing physically plausible rewards to optimize motion generation for physical fidelity. Our approach outperforms existing state-of-the-art models on two major datasets, HumanML3D and KIT-ML, achieving significant improvements in physical plausibility and motion quality. Project: \url{https://reindiffuse.github.io/}
HuTuMotion: Human-Tuned Navigation of Latent Motion Diffusion Models with Minimal Feedback
Dec 19, 2023We introduce HuTuMotion, an innovative approach for generating natural human motions that navigates latent motion diffusion models by leveraging few-shot human feedback. Unlike existing approaches that sample latent variables from a standard normal prior distribution, our method adapts the prior distribution to better suit the characteristics of the data, as indicated by human feedback, thus enhancing the quality of motion generation. Furthermore, our findings reveal that utilizing few-shot feedback can yield performance levels on par with those attained through extensive human feedback. This discovery emphasizes the potential and efficiency of incorporating few-shot human-guided optimization within latent diffusion models for personalized and style-aware human motion generation applications. The experimental results show the significantly superior performance of our method over existing state-of-the-art approaches.