 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional GAN for Enhancing Diffusion Models in Efficient and Authentic Global Gesture Generation from Audios
Oct 27, 2024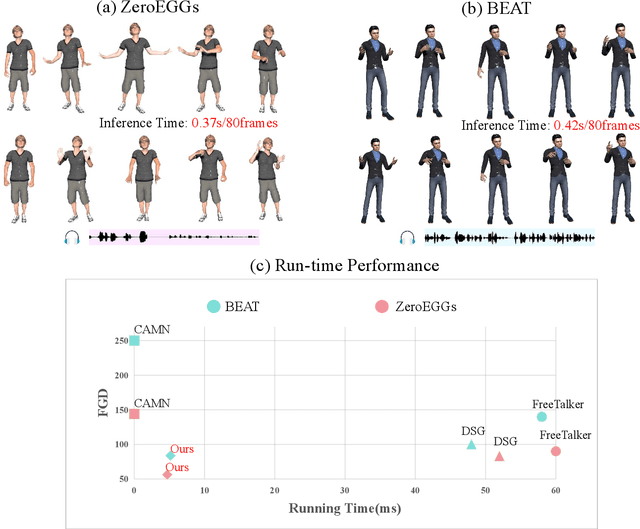

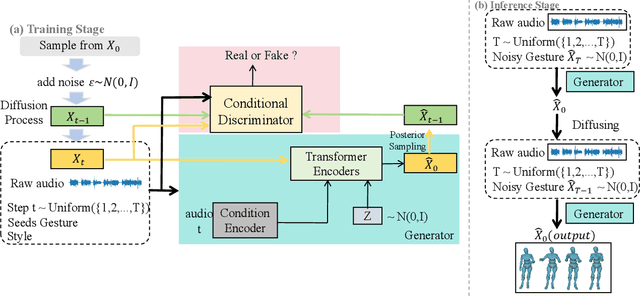

Audio-driven simultaneous gesture generation is vital for human-computer communication, AI games, and film production. While previous research has shown promise, there are still limitations. Methods based on VAEs are accompanied by issues of local jitter and global instability, whereas methods based on diffusion models are hampered by low generation efficiency. This is because the denoising process of DDPM in the latter relies on the assumption that the noise added at each step is sampled from a unimodal distribution, and the noise values are small. DDIM borrows the idea from the Euler method for solving differential equations, disrupts the Markov chain process, and increases the noise step size to reduce the number of denoising steps, thereby accelerating generation. However, simply increasing the step size during the step-by-step denoising process causes the results to gradually deviate from the original data distribution, leading to a significant drop in the quality of the generated actions and the emergence of unnatural artifacts. In this paper, we break the assumptions of DDPM and achieves breakthrough progress in denoising speed and fidelity. Specifically, we introduce a conditional GAN to capture audio control signals and implicitly match the multimodal denoising distribution between the diffusion and denoising steps within the same sampling step, aiming to sample larger noise values and apply fewer denoising steps for high-speed generation.
RopeTP: Global Human Motion Recovery via Integrating Robust Pose Estimation with Diffusion Trajectory Prior
Oct 27, 2024



We present RopeTP, a novel framework that combines Robust pose estimation with a diffusion Trajectory Prior to reconstruct global human motion from videos. At the heart of RopeTP is a hierarchical attention mechanism that significantly improves context awareness, which is essential for accurately inferring the posture of occluded body parts. This is achieved by exploiting the relationships with visible anatomical structures, enhancing the accuracy of local pose estimations. The improved robustness of these local estimations allows for the reconstruction of precise and stable global trajectories. Additionally, RopeTP incorporates a diffusion trajectory model that predicts realistic human motion from local pose sequences. This model ensures that the generated trajectories are not only consistent with observed local actions but also unfold naturally over time, thereby improving the realism and stability of 3D human motion reconstruction. Extensive experimental validation shows that RopeTP surpasses current methods on two benchmark datasets, particularly excelling in scenarios with occlusions. It also outperforms methods that rely on SLAM for initial camera estimates and extensive optimization, delivering more accurate and realistic trajectories.
ExpGest: Expressive Speaker Generation Using Diffusion Model and Hybrid Audio-Text Guidance
Oct 12, 2024



Existing gesture generation methods primarily focus on upper body gestures based on audio features, neglecting speech content, emotion, and locomotion. These limitations result in stiff, mechanical gestures that fail to convey the true meaning of audio content. We introduce ExpGest, a novel framework leveraging synchronized text and audio information to generate expressive full-body gestures. Unlike AdaIN or one-hot encoding methods, we design a noise emotion classifier for optimizing adversarial direction noise, avoiding melody distortion and guiding results towards specified emotions. Moreover, aligning semantic and gestures in the latent space provides better generalization capabilities. ExpGest, a diffusion model-based gesture generation framework, is the first attempt to offer mixed generation modes, including audio-driven gestures and text-shaped motion. Experiments show that our framework effectively learns from combined text-driven motion and audio-induced gesture datasets, and preliminary results demonstrate that ExpGest achieves more expressive, natural, and controllable global motion in speakers compared to state-of-the-art models.
ReinDiffuse: Crafting Physically Plausible Motions with Reinforced Diffusion Model
Oct 09, 2024



Generating human motion from textual descriptions is a challenging task. Existing methods either struggle with physical credibility or are limited by the complexities of physics simulations. In this paper, we present \emph{ReinDiffuse} that combines reinforcement learning with motion diffusion model to generate physically credible human motions that align with textual descriptions. Our method adapts Motion Diffusion Model to output a parameterized distribution of actions, making them compatible with reinforcement learning paradigms. We employ reinforcement learning with the objective of maximizing physically plausible rewards to optimize motion generation for physical fidelity. Our approach outperforms existing state-of-the-art models on two major datasets, HumanML3D and KIT-ML, achieving significant improvements in physical plausibility and motion quality. Project: \url{https://reindiffuse.github.io/}