 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMirage2Matter: A Physically Grounded Gaussian World Model from Video
Jan 24, 2026The scalability of embodied intelligence is fundamentally constrained by the scarcity of real-world interaction data. While simulation platforms provide a promising alternative, existing approaches often suffer from a substantial visual and physical gap to real environments and rely on expensive sensors, precise robot calibration, or depth measurements, limiting their practicality at scale. We present Simulate Anything, a graphics-driven world modeling and simulation framework that enables efficient generation of high-fidelity embodied training data using only multi-view environment videos and off-the-shelf assets. Our approach reconstructs real-world environments into a photorealistic scene representation using 3D Gaussian Splatting (3DGS), seamlessly capturing fine-grained geometry and appearance from video. We then leverage generative models to recover a physically realistic representation and integrate it into a simulation environment via a precision calibration target, enabling accurate scale alignment between the reconstructed scene and the real world. Together, these components provide a unified, editable, and physically grounded world model. Vision Language Action (VLA) models trained on our simulated data achieve strong zero-shot performance on downstream tasks, matching or even surpassing results obtained with real-world data, highlighting the potential of reconstruction-driven world modeling for scalable and practical embodied intelligence training.
Inter-Diffusion Generation Model of Speakers and Listeners for Effective Communication
May 08, 2025Full-body gestures play a pivotal role in natural interactions and are crucial for achieving effective communication. Nevertheless, most existing studies primarily focus on the gesture generation of speakers, overlooking the vital role of listeners in the interaction process and failing to fully explore the dynamic interaction between them. This paper innovatively proposes an Inter-Diffusion Generation Model of Speakers and Listeners for Effective Communication. For the first time, we integrate the full-body gestures of listeners into the generation framework. By devising a novel inter-diffusion mechanism, this model can accurately capture the complex interaction patterns between speakers and listeners during communication. In the model construction process, based on the advanced diffusion model architecture, we innovatively introduce interaction conditions and the GAN model to increase the denoising step size. As a result, when generating gesture sequences, the model can not only dynamically generate based on the speaker's speech information but also respond in realtime to the listener's feedback, enabling synergistic interaction between the two. Abundant experimental results demonstrate that compared with the current state-of-the-art gesture generation methods, the model we proposed has achieved remarkable improvements in the naturalness, coherence, and speech-gesture synchronization of the generated gestures. In the subjective evaluation experiments, users highly praised the generated interaction scenarios, believing that they are closer to real life human communication situations. Objective index evaluations also show that our model outperforms the baseline methods in multiple key indicators, providing more powerful support for effective communication.
HoloGest: Decoupled Diffusion and Motion Priors for Generating Holisticly Expressive Co-speech Gestures
Mar 17, 2025



Animating virtual characters with holistic co-speech gestures is a challenging but critical task. Previous systems have primarily focused on the weak correlation between audio and gestures, leading to physically unnatural outcomes that degrade the user experience. To address this problem, we introduce HoleGest, a novel neural network framework based on decoupled diffusion and motion priors for the automatic generation of high-quality, expressive co-speech gestures. Our system leverages large-scale human motion datasets to learn a robust prior with low audio dependency and high motion reliance, enabling stable global motion and detailed finger movements. To improve the generation efficiency of diffusion-based models, we integrate implicit joint constraints with explicit geometric and conditional constraints, capturing complex motion distributions between large strides. This integration significantly enhances generation speed while maintaining high-quality motion. Furthermore, we design a shared embedding space for gesture-transcription text alignment, enabling the generation of semantically correct gesture actions. Extensive experiments and user feedback demonstrate the effectiveness and potential applications of our model, with our method achieving a level of realism close to the ground truth, providing an immersive user experience. Our code, model, and demo are are available at https://cyk990422.github.io/HoloGest.github.io/.
RopeTP: Global Human Motion Recovery via Integrating Robust Pose Estimation with Diffusion Trajectory Prior
Oct 27, 2024



We present RopeTP, a novel framework that combines Robust pose estimation with a diffusion Trajectory Prior to reconstruct global human motion from videos. At the heart of RopeTP is a hierarchical attention mechanism that significantly improves context awareness, which is essential for accurately inferring the posture of occluded body parts. This is achieved by exploiting the relationships with visible anatomical structures, enhancing the accuracy of local pose estimations. The improved robustness of these local estimations allows for the reconstruction of precise and stable global trajectories. Additionally, RopeTP incorporates a diffusion trajectory model that predicts realistic human motion from local pose sequences. This model ensures that the generated trajectories are not only consistent with observed local actions but also unfold naturally over time, thereby improving the realism and stability of 3D human motion reconstruction. Extensive experimental validation shows that RopeTP surpasses current methods on two benchmark datasets, particularly excelling in scenarios with occlusions. It also outperforms methods that rely on SLAM for initial camera estimates and extensive optimization, delivering more accurate and realistic trajectories.
Conditional GAN for Enhancing Diffusion Models in Efficient and Authentic Global Gesture Generation from Audios
Oct 27, 2024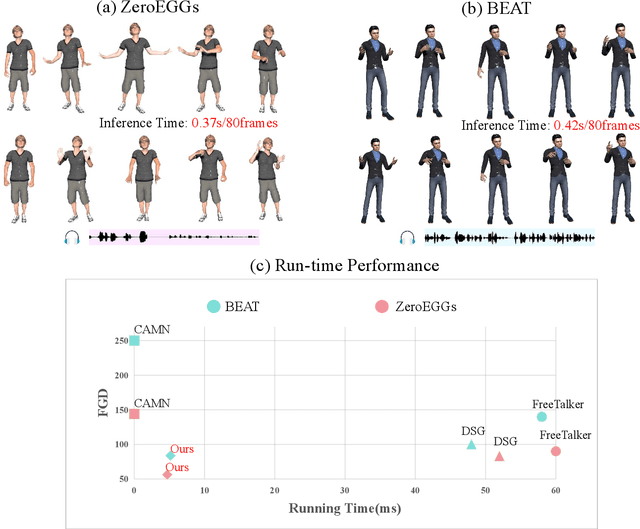

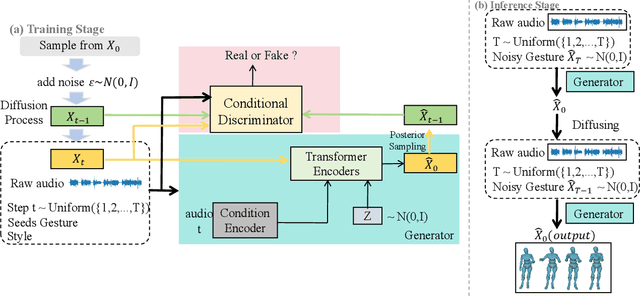

Audio-driven simultaneous gesture generation is vital for human-computer communication, AI games, and film production. While previous research has shown promise, there are still limitations. Methods based on VAEs are accompanied by issues of local jitter and global instability, whereas methods based on diffusion models are hampered by low generation efficiency. This is because the denoising process of DDPM in the latter relies on the assumption that the noise added at each step is sampled from a unimodal distribution, and the noise values are small. DDIM borrows the idea from the Euler method for solving differential equations, disrupts the Markov chain process, and increases the noise step size to reduce the number of denoising steps, thereby accelerating generation. However, simply increasing the step size during the step-by-step denoising process causes the results to gradually deviate from the original data distribution, leading to a significant drop in the quality of the generated actions and the emergence of unnatural artifacts. In this paper, we break the assumptions of DDPM and achieves breakthrough progress in denoising speed and fidelity. Specifically, we introduce a conditional GAN to capture audio control signals and implicitly match the multimodal denoising distribution between the diffusion and denoising steps within the same sampling step, aiming to sample larger noise values and apply fewer denoising steps for high-speed generation.
ExpGest: Expressive Speaker Generation Using Diffusion Model and Hybrid Audio-Text Guidance
Oct 12, 2024



Existing gesture generation methods primarily focus on upper body gestures based on audio features, neglecting speech content, emotion, and locomotion. These limitations result in stiff, mechanical gestures that fail to convey the true meaning of audio content. We introduce ExpGest, a novel framework leveraging synchronized text and audio information to generate expressive full-body gestures. Unlike AdaIN or one-hot encoding methods, we design a noise emotion classifier for optimizing adversarial direction noise, avoiding melody distortion and guiding results towards specified emotions. Moreover, aligning semantic and gestures in the latent space provides better generalization capabilities. ExpGest, a diffusion model-based gesture generation framework, is the first attempt to offer mixed generation modes, including audio-driven gestures and text-shaped motion. Experiments show that our framework effectively learns from combined text-driven motion and audio-induced gesture datasets, and preliminary results demonstrate that ExpGest achieves more expressive, natural, and controllable global motion in speakers compared to state-of-the-art models.
ReinDiffuse: Crafting Physically Plausible Motions with Reinforced Diffusion Model
Oct 09, 2024



Generating human motion from textual descriptions is a challenging task. Existing methods either struggle with physical credibility or are limited by the complexities of physics simulations. In this paper, we present \emph{ReinDiffuse} that combines reinforcement learning with motion diffusion model to generate physically credible human motions that align with textual descriptions. Our method adapts Motion Diffusion Model to output a parameterized distribution of actions, making them compatible with reinforcement learning paradigms. We employ reinforcement learning with the objective of maximizing physically plausible rewards to optimize motion generation for physical fidelity. Our approach outperforms existing state-of-the-art models on two major datasets, HumanML3D and KIT-ML, achieving significant improvements in physical plausibility and motion quality. Project: \url{https://reindiffuse.github.io/}
Freetalker: Controllable Speech and Text-Driven Gesture Generation Based on Diffusion Models for Enhanced Speaker Naturalness
Jan 07, 2024



Current talking avatars mostly generate co-speech gestures based on audio and text of the utterance, without considering the non-speaking motion of the speaker. Furthermore, previous works on co-speech gesture generation have designed network structures based on individual gesture datasets, which results in limited data volume, compromised generalizability, and restricted speaker movements. To tackle these issues, we introduce FreeTalker, which, to the best of our knowledge, is the first framework for the generation of both spontaneous (e.g., co-speech gesture) and non-spontaneous (e.g., moving around the podium) speaker motions. Specifically, we train a diffusion-based model for speaker motion generation that employs unified representations of both speech-driven gestures and text-driven motions, utilizing heterogeneous data sourced from various motion datasets. During inference, we utilize classifier-free guidance to highly control the style in the clips. Additionally, to create smooth transitions between clips, we utilize DoubleTake, a method that leverages a generative prior and ensures seamless motion blending. Extensive experiments show that our method generates natural and controllable speaker movements. Our code, model, and demo are are available at \url{https://youngseng.github.io/FreeTalker/}.
SignAvatars: A Large-scale 3D Sign Language Holistic Motion Dataset and Benchmark
Oct 31, 2023
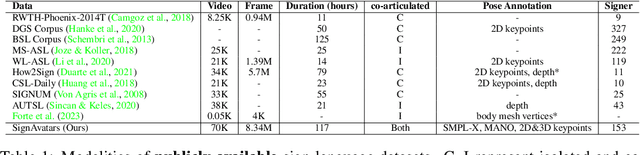

In this paper, we present SignAvatars, the first large-scale multi-prompt 3D sign language (SL) motion dataset designed to bridge the communication gap for hearing-impaired individuals. While there has been an exponentially growing number of research regarding digital communication, the majority of existing communication technologies primarily cater to spoken or written languages, instead of SL, the essential communication method for hearing-impaired communities. Existing SL datasets, dictionaries, and sign language production (SLP) methods are typically limited to 2D as the annotating 3D models and avatars for SL is usually an entirely manual and labor-intensive process conducted by SL experts, often resulting in unnatural avatars. In response to these challenges, we compile and curate the SignAvatars dataset, which comprises 70,000 videos from 153 signers, totaling 8.34 million frames, covering both isolated signs and continuous, co-articulated signs, with multiple prompts including HamNoSys, spoken language, and words. To yield 3D holistic annotations, including meshes and biomechanically-valid poses of body, hands, and face, as well as 2D and 3D keypoints, we introduce an automated annotation pipeline operating on our large corpus of SL videos. SignAvatars facilitates various tasks such as 3D sign language recognition (SLR) and the novel 3D SL production (SLP) from diverse inputs like text scripts, individual words, and HamNoSys notation. Hence, to evaluate the potential of SignAvatars, we further propose a unified benchmark of 3D SL holistic motion production. We believe that this work is a significant step forward towards bringing the digital world to the hearing-impaired communities. Our project page is at https://signavatars.github.io/
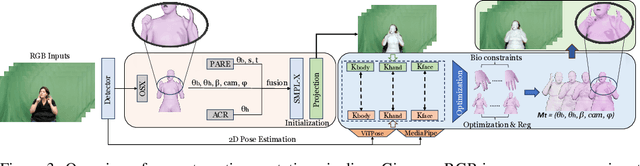
BoPR: Body-aware Part Regressor for Human Shape and Pose Estimation
Mar 24, 2023This paper presents a novel approach for estimating human body shape and pose from monocular images that effectively addresses the challenges of occlusions and depth ambiguity. Our proposed method BoPR, the Body-aware Part Regressor, first extracts features of both the body and part regions using an attention-guided mechanism. We then utilize these features to encode extra part-body dependency for per-part regression, with part features as queries and body feature as a reference. This allows our network to infer the spatial relationship of occluded parts with the body by leveraging visible parts and body reference information. Our method outperforms existing state-of-the-art methods on two benchmark datasets, and our experiments show that it significantly surpasses existing methods in terms of depth ambiguity and occlusion handling. These results provide strong evidence of the effectiveness of our approach.The code and data are available for research purposes at https://github.com/cyk990422/BoPR.