 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Motion Video Generation: A Survey
Sep 04, 2025Human motion video generation has garnered significant research interest due to its broad applications, enabling innovations such as photorealistic singing heads or dynamic avatars that seamlessly dance to music. However, existing surveys in this field focus on individual methods, lacking a comprehensive overview of the entire generative process. This paper addresses this gap by providing an in-depth survey of human motion video generation, encompassing over ten sub-tasks, and detailing the five key phases of the generation process: input, motion planning, motion video generation, refinement, and output. Notably, this is the first survey that discusses the potential of large language models in enhancing human motion video generation. Our survey reviews the latest developments and technological trends in human motion video generation across three primary modalities: vision, text, and audio. By covering over two hundred papers, we offer a thorough overview of the field and highlight milestone works that have driven significant technological breakthroughs. Our goal for this survey is to unveil the prospects of human motion video generation and serve as a valuable resource for advancing the comprehensive applications of digital humans. A complete list of the models examined in this survey is available in Our Repository https://github.com/Winn1y/Awesome-Human-Motion-Video-Generation.
* Accepted by TPAMI. Github Repo: https://github.com/Winn1y/Awesome-Human-Motion-Video-Generation IEEE Access: https://ieeexplore.ieee.org/document/11106267
MemorySAM: Memorize Modalities and Semantics with Segment Anything Model 2 for Multi-modal Semantic Segmentation
Mar 09, 2025Research has focused on Multi-Modal Semantic Segmentation (MMSS), where pixel-wise predictions are derived from multiple visual modalities captured by diverse sensors. Recently, the large vision model, Segment Anything Model 2 (SAM2), has shown strong zero-shot segmentation performance on both images and videos. When extending SAM2 to MMSS, two issues arise: 1. How can SAM2 be adapted to multi-modal data? 2. How can SAM2 better understand semantics? Inspired by cross-frame correlation in videos, we propose to treat multi-modal data as a sequence of frames representing the same scene. Our key idea is to ''memorize'' the modality-agnostic information and 'memorize' the semantics related to the targeted scene. To achieve this, we apply SAM2's memory mechanisms across multi-modal data to capture modality-agnostic features. Meanwhile, to memorize the semantic knowledge, we propose a training-only Semantic Prototype Memory Module (SPMM) to store category-level prototypes across training for facilitating SAM2's transition from instance to semantic segmentation. A prototypical adaptation loss is imposed between global and local prototypes iteratively to align and refine SAM2's semantic understanding. Extensive experimental results demonstrate that our proposed MemorySAM outperforms SoTA methods by large margins on both synthetic and real-world benchmarks (65.38% on DELIVER, 52.88% on MCubeS). Source code will be made publicly available.
Learning Robust Anymodal Segmentor with Unimodal and Cross-modal Distillation
Nov 26, 2024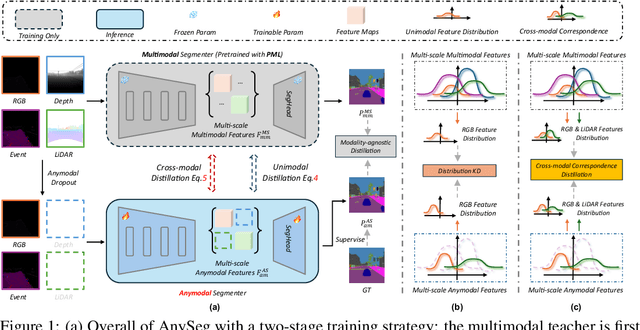
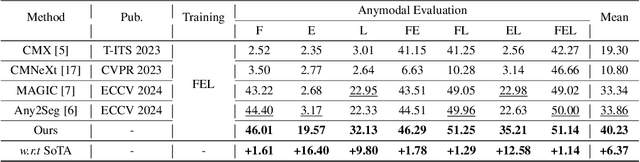
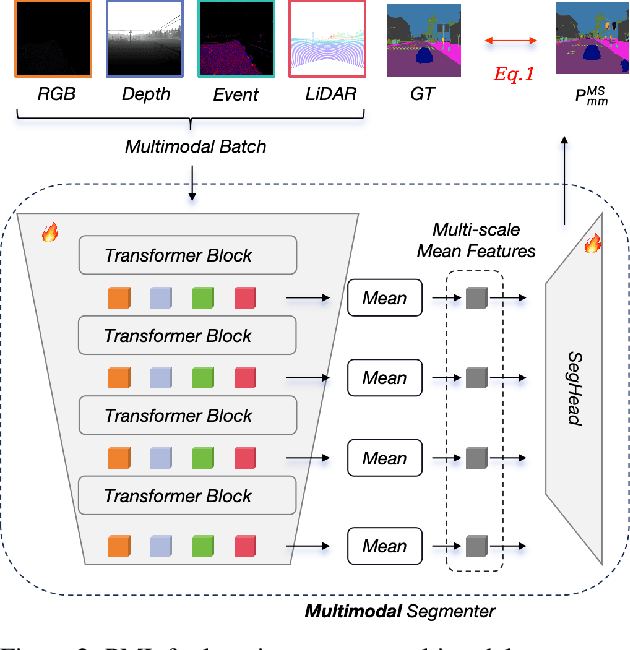

Simultaneously using multimodal inputs from multiple sensors to train segmentors is intuitively advantageous but practically challenging. A key challenge is unimodal bias, where multimodal segmentors over rely on certain modalities, causing performance drops when others are missing, common in real world applications. To this end, we develop the first framework for learning robust segmentor that can handle any combinations of visual modalities. Specifically, we first introduce a parallel multimodal learning strategy for learning a strong teacher. The cross-modal and unimodal distillation is then achieved in the multi scale representation space by transferring the feature level knowledge from multimodal to anymodal segmentors, aiming at addressing the unimodal bias and avoiding over-reliance on specific modalities. Moreover, a prediction level modality agnostic semantic distillation is proposed to achieve semantic knowledge transferring for segmentation. Extensive experiments on both synthetic and real-world multi-sensor benchmarks demonstrate that our method achieves superior performance.
Freetalker: Controllable Speech and Text-Driven Gesture Generation Based on Diffusion Models for Enhanced Speaker Naturalness
Jan 07, 2024



Current talking avatars mostly generate co-speech gestures based on audio and text of the utterance, without considering the non-speaking motion of the speaker. Furthermore, previous works on co-speech gesture generation have designed network structures based on individual gesture datasets, which results in limited data volume, compromised generalizability, and restricted speaker movements. To tackle these issues, we introduce FreeTalker, which, to the best of our knowledge, is the first framework for the generation of both spontaneous (e.g., co-speech gesture) and non-spontaneous (e.g., moving around the podium) speaker motions. Specifically, we train a diffusion-based model for speaker motion generation that employs unified representations of both speech-driven gestures and text-driven motions, utilizing heterogeneous data sourced from various motion datasets. During inference, we utilize classifier-free guidance to highly control the style in the clips. Additionally, to create smooth transitions between clips, we utilize DoubleTake, a method that leverages a generative prior and ensures seamless motion blending. Extensive experiments show that our method generates natural and controllable speaker movements. Our code, model, and demo are are available at \url{https://youngseng.github.io/FreeTalker/}.
The DiffuseStyleGesture+ entry to the GENEA Challenge 2023
Aug 26, 2023In this paper, we introduce the DiffuseStyleGesture+, our solution for the Generation and Evaluation of Non-verbal Behavior for Embodied Agents (GENEA) Challenge 2023, which aims to foster the development of realistic, automated systems for generating conversational gestures. Participants are provided with a pre-processed dataset and their systems are evaluated through crowdsourced scoring. Our proposed model, DiffuseStyleGesture+, leverages a diffusion model to generate gestures automatically. It incorporates a variety of modalities, including audio, text, speaker ID, and seed gestures. These diverse modalities are mapped to a hidden space and processed by a modified diffusion model to produce the corresponding gesture for a given speech input. Upon evaluation, the DiffuseStyleGesture+ demonstrated performance on par with the top-tier models in the challenge, showing no significant differences with those models in human-likeness, appropriateness for the interlocutor, and achieving competitive performance with the best model on appropriateness for agent speech. This indicates that our model is competitive and effective in generating realistic and appropriate gestures for given speech. The code, pre-trained models, and demos are available at https://github.com/YoungSeng/DiffuseStyleGesture/tree/DiffuseStyleGesturePlus/BEAT-TWH-main.