 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecover Semantics First, Generate Better: Improved Latent Modeling for 3D MRI Reconstruction and Cross-Contrast Synthesis
Jun 16, 2026Multi-contrast magnetic resonance imaging (MRI) provides complementary information for clinical diagnosis. However, acquiring all MRI sequences is often time-consuming and costly. Recent generative models perform cross-contrast synthesis to address this issue by inferring absent contrasts from the available ones. Nevertheless, synthesizing 3D MRI presents significant challenges. Due to the massive volume sizes, operating directly in the pixel space is computationally prohibitive; therefore, a common approach is to first compress the 3D volumes into a latent space and subsequently train generative models in that space. We observe that existing compression architectures face several critical issues: they under-preserve long-range anatomical coherence, discard clinically meaningful semantics, and rely on optimization objectives that lead to over-smoothed reconstructions. Ultimately, these shortcomings compromise the performance of subsequent generative models. In this work, we propose a semantics-first latent modeling framework for 3D MRI reconstruction and cross-contrast synthesis. Specifically, we introduce a Latent Harmonization Encoder (LHE) to capture global anatomical dependencies, ensuring coherent volumetric representations. To mitigate semantic degradation during latent compression, we further design a Semantic Recovery Block (SRB) that injects high-level priors from a self-supervised semantic teacher, enhancing contrast-aware separability in the latent space. Additionally, we propose an Anatomy-aware Frequency Loss (AFL) to adaptively preserve diagnostically relevant high-frequency structures. Extensive experiments on two public multi-contrast MRI datasets demonstrate consistent improvements in reconstruction fidelity and cross-contrast synthesis quality. Our code is available at https://github.com/script-Yang/RSF.
SegDINO: Introducing Multi-Scale Structure into DINO for Efficient Medical Image Segmentation
Jun 16, 2026Self-supervised DINO models provide strong transferable visual representations, yet applying them directly to image segmentation remains challenging. Existing approaches commonly rely on heavy decoders with complex upsampling, introducing substantial parameter and computational overhead. We observe that introducing scale into DINO features is far more critical than increasing decoder capacity. In this work, we present SegDINO, an efficient segmentation framework that integrates a DINOv3 backbone with lightweight scale modeling. SegDINO introduces Token Pyramid Adaptation (TPA) to reorganize intermediate DINO features into a pseudo multi-scale hierarchy, and Scale-Aware Decoding (SAD) for efficient intra-scale refinement and top-down multi-scale propagation. We further curate PanCT, a new CT dataset containing 284 patients with expert-annotated pancreatic tumors, to assess SegDINO's ability to handle difficult small-lesion cases. Extensive experiments on PanCT and three public benchmarks demonstrate that SegDINO achieves state-of-the-art results with high efficiency. The code is available at https://github.com/script-Yang/segdino_v2.
ClinHallu: A Benchmark for Diagnosing Stage-Wise Hallucinations in Medical MLLM Reasoning
Jun 12, 2026Building trustworthy medical multimodal large language models (MLLMs) is critical for reliable clinical decision support. Existing medical hallucination benchmarks mainly focus on data collection, but often ignore where hallucinations originate within the reasoning process. We find that hallucination sources vary across samples: errors may arise from visual misrecognition, incorrect medical knowledge recall, or flawed reasoning integration. To enable source-level hallucination diagnosis, we introduce ClinHallu, a benchmark for stage-wise hallucination diagnosis in medical MLLM reasoning. ClinHallu contains 7,031 validated instances, where each instance is augmented with a structured reasoning trace decomposed into Visual Recognition, Knowledge Recall, and Reasoning Integration. We also use stage-replacement interventions to measure how correcting specific stages affects the final answer. Beyond evaluation, we show that trace-supervised fine-tuning reduces stage-wise hallucinations. ClinHallu provides a fine-grained hallucination testbed for diagnosing and mitigating reasoning failures in medical MLLMs. The benchmark is publicly available at https://github.com/alibaba-damo-academy/ClinHallu.
PolySpeech-100: A Large-Scale Benchmark for Speech Understanding Across 100+ Languages and Dialects
May 31, 2026While End-to-End (E2E) Speech-Large Language Models (Speech-LLMs) are rapidly evolving, their evaluation methodologies remain limited to the era of simple transcription. Existing benchmarks suffer from three critical limitations: a pronounced bias towards high-resource languages, a focus on low-level recognition (ASR) rather than semantic reasoning, and a neglect of regional dialects. To bridge this gap, we introduce PolySpeech-100, a massive-scale benchmark designed to assess `native-level' speech comprehension across 110 linguistic variants. We employ a novel hybrid construction pipeline that augments gold-standard human recordings with instruction-driven synthetic speech, allowing us to cover 19 distinct Chinese dialects and over 80 low-resource languages. Extensive evaluation of 22 state-of-the-art models (including Gemini-3, GPT-Audio, and Qwen2.5-Omni) yields pivotal insights. First, we demonstrate that open-source E2E models outperform Cascade (ASR+LLM) systems on heavy dialects, proving that direct audio processing preserves critical paralinguistic cues and prosodic features (e.g., intonation, stress) that are often lost in standard transcription. Second, we reveal a significant performance gap: while commercial models maintain robustness, open-source models suffer catastrophic degradation on low-resource languages. Finally, counter-intuitively, we observe that under standard zero-shot settings, Chain-of-Thought prompting frequently degrades speech understanding performance for most evaluated models, revealing a potential modality alignment gap in current architectures. PolySpeech-100 establishes a rigorous standard for the next generation of inclusive, omni-capable Speech-LLMs. The data, demo, and code are publicly available at https://github.com/YoungSeng/PolySpeech-100.
Egocentric Co-Pilot: Web-Native Smart-Glasses Agents for Assistive Egocentric AI
Mar 01, 2026What if accessing the web did not require a screen, a stable desk, or even free hands? For people navigating crowded cities, living with low vision, or experiencing cognitive overload, smart glasses coupled with AI agents could turn the web into an always-on assistive layer over daily life. We present Egocentric Co-Pilot, a web-native neuro-symbolic framework that runs on smart glasses and uses a Large Language Model (LLM) to orchestrate a toolbox of perception, reasoning, and web tools. An egocentric reasoning core combines Temporal Chain-of-Thought with Hierarchical Context Compression to support long-horizon question answering and decision support over continuous first-person video, far beyond a single model's context window. Additionally, a lightweight multimodal intent layer maps noisy speech and gaze into structured commands. We further implement and evaluate a cloud-native WebRTC pipeline integrating streaming speech, video, and control messages into a unified channel for smart glasses and browsers. In parallel, we deploy an on-premise WebSocket baseline, exposing concrete trade-offs between local inference and cloud offloading in terms of latency, mobility, and resource use. Experiments on Egolife and HD-EPIC demonstrate competitive or state-of-the-art egocentric QA performance, and a human-in-the-loop study on smart glasses shows higher task completion and user satisfaction than leading commercial baselines. Taken together, these results indicate that web-connected egocentric co-pilots can be a practical path toward more accessible, context-aware assistance in everyday life. By grounding operation in web-native communication primitives and modular, auditable tool use, Egocentric Co-Pilot offers a concrete blueprint for assistive, always-on web agents that support education, accessibility, and social inclusion for people who may benefit most from contextual, egocentric AI.
Optimizing Multimodal LLMs for Egocentric Video Understanding: A Solution for the HD-EPIC VQA Challenge
Jan 15, 2026Multimodal Large Language Models (MLLMs) struggle with complex video QA benchmarks like HD-EPIC VQA due to ambiguous queries/options, poor long-range temporal reasoning, and non-standardized outputs. We propose a framework integrating query/choice pre-processing, domain-specific Qwen2.5-VL fine-tuning, a novel Temporal Chain-of-Thought (T-CoT) prompting for multi-step reasoning, and robust post-processing. This system achieves 41.6% accuracy on HD-EPIC VQA, highlighting the need for holistic pipeline optimization in demanding video understanding. Our code, fine-tuned models are available at https://github.com/YoungSeng/Egocentric-Co-Pilot.
VQ-Seg: Vector-Quantized Token Perturbation for Semi-Supervised Medical Image Segmentation
Jan 15, 2026Consistency learning with feature perturbation is a widely used strategy in semi-supervised medical image segmentation. However, many existing perturbation methods rely on dropout, and thus require a careful manual tuning of the dropout rate, which is a sensitive hyperparameter and often difficult to optimize and may lead to suboptimal regularization. To overcome this limitation, we propose VQ-Seg, the first approach to employ vector quantization (VQ) to discretize the feature space and introduce a novel and controllable Quantized Perturbation Module (QPM) that replaces dropout. Our QPM perturbs discrete representations by shuffling the spatial locations of codebook indices, enabling effective and controllable regularization. To mitigate potential information loss caused by quantization, we design a dual-branch architecture where the post-quantization feature space is shared by both image reconstruction and segmentation tasks. Moreover, we introduce a Post-VQ Feature Adapter (PFA) to incorporate guidance from a foundation model (FM), supplementing the high-level semantic information lost during quantization. Furthermore, we collect a large-scale Lung Cancer (LC) dataset comprising 828 CT scans annotated for central-type lung carcinoma. Extensive experiments on the LC dataset and other public benchmarks demonstrate the effectiveness of our method, which outperforms state-of-the-art approaches. Code available at: https://github.com/script-Yang/VQ-Seg.
Plug-and-Play Clarifier: A Zero-Shot Multimodal Framework for Egocentric Intent Disambiguation
Nov 12, 2025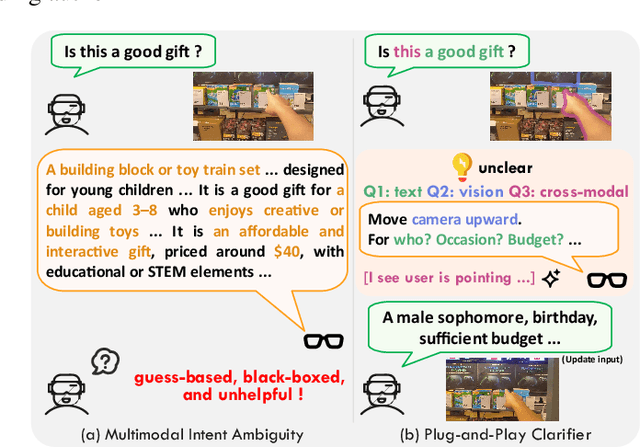
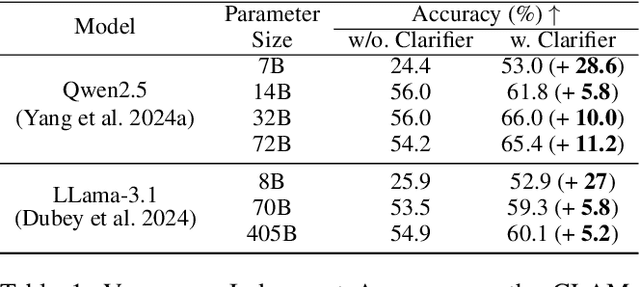
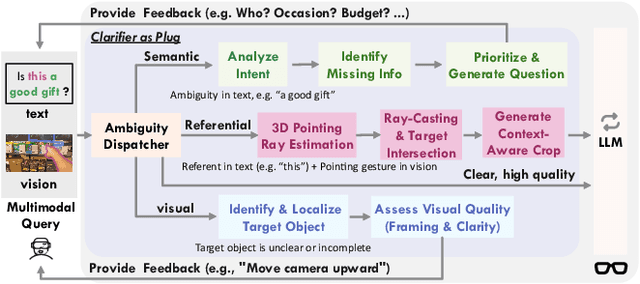
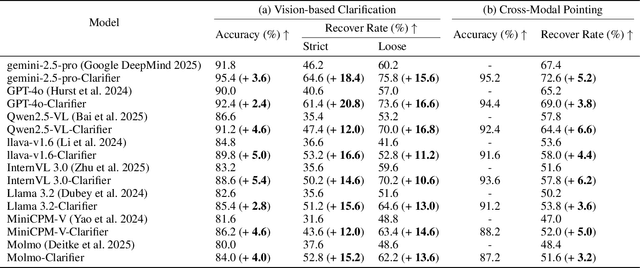
The performance of egocentric AI agents is fundamentally limited by multimodal intent ambiguity. This challenge arises from a combination of underspecified language, imperfect visual data, and deictic gestures, which frequently leads to task failure. Existing monolithic Vision-Language Models (VLMs) struggle to resolve these multimodal ambiguous inputs, often failing silently or hallucinating responses. To address these ambiguities, we introduce the Plug-and-Play Clarifier, a zero-shot and modular framework that decomposes the problem into discrete, solvable sub-tasks. Specifically, our framework consists of three synergistic modules: (1) a text clarifier that uses dialogue-driven reasoning to interactively disambiguate linguistic intent, (2) a vision clarifier that delivers real-time guidance feedback, instructing users to adjust their positioning for improved capture quality, and (3) a cross-modal clarifier with grounding mechanism that robustly interprets 3D pointing gestures and identifies the specific objects users are pointing to. Extensive experiments demonstrate that our framework improves the intent clarification performance of small language models (4--8B) by approximately 30%, making them competitive with significantly larger counterparts. We also observe consistent gains when applying our framework to these larger models. Furthermore, our vision clarifier increases corrective guidance accuracy by over 20%, and our cross-modal clarifier improves semantic answer accuracy for referential grounding by 5%. Overall, our method provides a plug-and-play framework that effectively resolves multimodal ambiguity and significantly enhances user experience in egocentric interaction.
VAEVQ: Enhancing Discrete Visual Tokenization through Variational Modeling
Nov 10, 2025Vector quantization (VQ) transforms continuous image features into discrete representations, providing compressed, tokenized inputs for generative models. However, VQ-based frameworks suffer from several issues, such as non-smooth latent spaces, weak alignment between representations before and after quantization, and poor coherence between the continuous and discrete domains. These issues lead to unstable codeword learning and underutilized codebooks, ultimately degrading the performance of both reconstruction and downstream generation tasks. To this end, we propose VAEVQ, which comprises three key components: (1) Variational Latent Quantization (VLQ), replacing the AE with a VAE for quantization to leverage its structured and smooth latent space, thereby facilitating more effective codeword activation; (2) Representation Coherence Strategy (RCS), adaptively modulating the alignment strength between pre- and post-quantization features to enhance consistency and prevent overfitting to noise; and (3) Distribution Consistency Regularization (DCR), aligning the entire codebook distribution with the continuous latent distribution to improve utilization. Extensive experiments on two benchmark datasets demonstrate that VAEVQ outperforms state-of-the-art methods.
K-Stain: Keypoint-Driven Correspondence for H&E-to-IHC Virtual Staining
Nov 10, 2025Virtual staining offers a promising method for converting Hematoxylin and Eosin (H&E) images into Immunohistochemical (IHC) images, eliminating the need for costly chemical processes. However, existing methods often struggle to utilize spatial information effectively due to misalignment in tissue slices. To overcome this challenge, we leverage keypoints as robust indicators of spatial correspondence, enabling more precise alignment and integration of structural details in synthesized IHC images. We introduce K-Stain, a novel framework that employs keypoint-based spatial and semantic relationships to enhance synthesized IHC image fidelity. K-Stain comprises three main components: (1) a Hierarchical Spatial Keypoint Detector (HSKD) for identifying keypoints in stain images, (2) a Keypoint-aware Enhancement Generator (KEG) that integrates these keypoints during image generation, and (3) a Keypoint Guided Discriminator (KGD) that improves the discriminator's sensitivity to spatial details. Our approach leverages contextual information from adjacent slices, resulting in more accurate and visually consistent IHC images. Extensive experiments show that K-Stain outperforms state-of-the-art methods in quantitative metrics and visual quality.