 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Flight Over the Gap: A Survey from Perspective to Panoramic Vision
Sep 04, 2025



Driven by the demand for spatial intelligence and holistic scene perception, omnidirectional images (ODIs), which provide a complete 360\textdegree{} field of view, are receiving growing attention across diverse applications such as virtual reality, autonomous driving, and embodied robotics. Despite their unique characteristics, ODIs exhibit remarkable differences from perspective images in geometric projection, spatial distribution, and boundary continuity, making it challenging for direct domain adaption from perspective methods. This survey reviews recent panoramic vision techniques with a particular emphasis on the perspective-to-panorama adaptation. We first revisit the panoramic imaging pipeline and projection methods to build the prior knowledge required for analyzing the structural disparities. Then, we summarize three challenges of domain adaptation: severe geometric distortions near the poles, non-uniform sampling in Equirectangular Projection (ERP), and periodic boundary continuity. Building on this, we cover 20+ representative tasks drawn from more than 300 research papers in two dimensions. On one hand, we present a cross-method analysis of representative strategies for addressing panoramic specific challenges across different tasks. On the other hand, we conduct a cross-task comparison and classify panoramic vision into four major categories: visual quality enhancement and assessment, visual understanding, multimodal understanding, and visual generation. In addition, we discuss open challenges and future directions in data, models, and applications that will drive the advancement of panoramic vision research. We hope that our work can provide new insight and forward looking perspectives to advance the development of panoramic vision technologies. Our project page is https://insta360-research-team.github.io/Survey-of-Panorama
RAPID Hand: A Robust, Affordable, Perception-Integrated, Dexterous Manipulation Platform for Generalist Robot Autonomy
Jun 09, 2025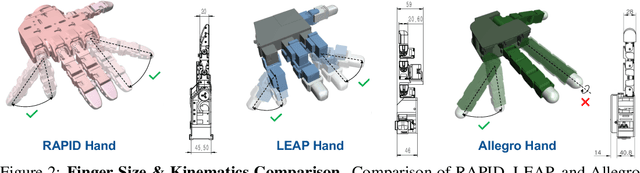
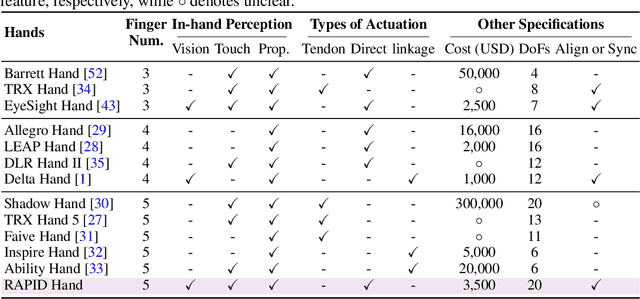
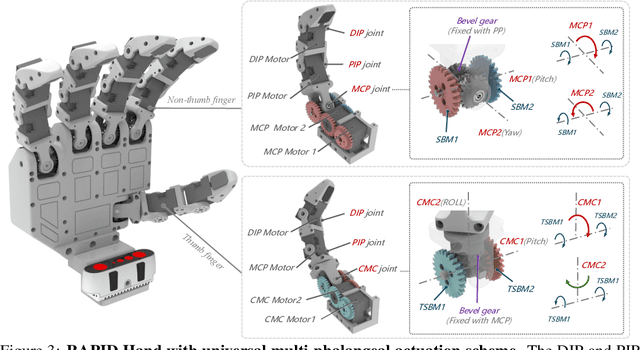
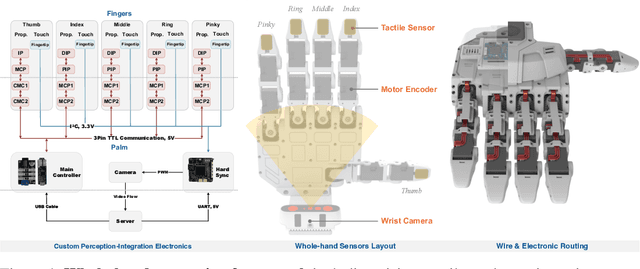
This paper addresses the scarcity of low-cost but high-dexterity platforms for collecting real-world multi-fingered robot manipulation data towards generalist robot autonomy. To achieve it, we propose the RAPID Hand, a co-optimized hardware and software platform where the compact 20-DoF hand, robust whole-hand perception, and high-DoF teleoperation interface are jointly designed. Specifically, RAPID Hand adopts a compact and practical hand ontology and a hardware-level perception framework that stably integrates wrist-mounted vision, fingertip tactile sensing, and proprioception with sub-7 ms latency and spatial alignment. Collecting high-quality demonstrations on high-DoF hands is challenging, as existing teleoperation methods struggle with precision and stability on complex multi-fingered systems. We address this by co-optimizing hand design, perception integration, and teleoperation interface through a universal actuation scheme, custom perception electronics, and two retargeting constraints. We evaluate the platform's hardware, perception, and teleoperation interface. Training a diffusion policy on collected data shows superior performance over prior works, validating the system's capability for reliable, high-quality data collection. The platform is constructed from low-cost and off-the-shelf components and will be made public to ensure reproducibility and ease of adoption.
Prior Does Matter: Visual Navigation via Denoising Diffusion Bridge Models
Apr 14, 2025Recent advancements in diffusion-based imitation learning, which show impressive performance in modeling multimodal distributions and training stability, have led to substantial progress in various robot learning tasks. In visual navigation, previous diffusion-based policies typically generate action sequences by initiating from denoising Gaussian noise. However, the target action distribution often diverges significantly from Gaussian noise, leading to redundant denoising steps and increased learning complexity. Additionally, the sparsity of effective action distributions makes it challenging for the policy to generate accurate actions without guidance. To address these issues, we propose a novel, unified visual navigation framework leveraging the denoising diffusion bridge models named NaviBridger. This approach enables action generation by initiating from any informative prior actions, enhancing guidance and efficiency in the denoising process. We explore how diffusion bridges can enhance imitation learning in visual navigation tasks and further examine three source policies for generating prior actions. Extensive experiments in both simulated and real-world indoor and outdoor scenarios demonstrate that NaviBridger accelerates policy inference and outperforms the baselines in generating target action sequences. Code is available at https://github.com/hren20/NaiviBridger.
OPG-Policy: Occluded Push-Grasp Policy Learning with Amodal Segmentation
Mar 06, 2025Goal-oriented grasping in dense clutter, a fundamental challenge in robotics, demands an adaptive policy to handle occluded target objects and diverse configurations. Previous methods typically learn policies based on partially observable segments of the occluded target to generate motions. However, these policies often struggle to generate optimal motions due to uncertainties regarding the invisible portions of different occluded target objects across various scenes, resulting in low motion efficiency. To this end, we propose OPG-Policy, a novel framework that leverages amodal segmentation to predict occluded portions of the target and develop an adaptive push-grasp policy for cluttered scenarios where the target object is partially observed. Specifically, our approach trains a dedicated amodal segmentation module for diverse target objects to generate amodal masks. These masks and scene observations are mapped to the future rewards of grasp and push motion primitives via deep Q-learning to learn the motion critic. Afterward, the push and grasp motion candidates predicted by the critic, along with the relevant domain knowledge, are fed into the coordinator to generate the optimal motion implemented by the robot. Extensive experiments conducted in both simulated and real-world environments demonstrate the effectiveness of our approach in generating motion sequences for retrieving occluded targets, outperforming other baseline methods in success rate and motion efficiency.
VinT-6D: A Large-Scale Object-in-hand Dataset from Vision, Touch and Proprioception
Jan 06, 2025



This paper addresses the scarcity of large-scale datasets for accurate object-in-hand pose estimation, which is crucial for robotic in-hand manipulation within the ``Perception-Planning-Control" paradigm. Specifically, we introduce VinT-6D, the first extensive multi-modal dataset integrating vision, touch, and proprioception, to enhance robotic manipulation. VinT-6D comprises 2 million VinT-Sim and 0.1 million VinT-Real splits, collected via simulations in MuJoCo and Blender and a custom-designed real-world platform. This dataset is tailored for robotic hands, offering models with whole-hand tactile perception and high-quality, well-aligned data. To the best of our knowledge, the VinT-Real is the largest considering the collection difficulties in the real-world environment so that it can bridge the gap of simulation to real compared to the previous works. Built upon VinT-6D, we present a benchmark method that shows significant improvements in performance by fusing multi-modal information. The project is available at https://VinT-6D.github.io/.