 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePC-CrossDiff: Point-Cluster Dual-Level Cross-Modal Differential Attention for Unified 3D Referring and Segmentation
Mar 18, 20263D Visual Grounding (3DVG) aims to localize the referent of natural language referring expressions through two core tasks: Referring Expression Comprehension (3DREC) and Segmentation (3DRES). While existing methods achieve high accuracy in simple, single-object scenes, they suffer from severe performance degradation in complex, multi-object scenes that are common in real-world settings, hindering practical deployment. Existing methods face two key challenges in complex, multi-object scenes: inadequate parsing of implicit localization cues critical for disambiguating visually similar objects, and ineffective suppression of dynamic spatial interference from co-occurring objects, resulting in degraded grounding accuracy. To address these challenges, we propose PC-CrossDiff, a unified dual-task framework with a dual-level cross-modal differential attention architecture for 3DREC and 3DRES. Specifically, the framework introduces: (i) Point-Level Differential Attention (PLDA) modules that apply bidirectional differential attention between text and point clouds, adaptively extracting implicit localization cues via learnable weights to improve discriminative representation; (ii) Cluster-Level Differential Attention (CLDA) modules that establish a hierarchical attention mechanism to adaptively enhance localization-relevant spatial relationships while suppressing ambiguous or irrelevant spatial relations through a localization-aware differential attention block. Our method achieves state-of-the-art performance on the ScanRefer, NR3D, and SR3D benchmarks. Notably, on the Implicit subsets of ScanRefer, it improves the Overall@0.50 score by +10.16% for the 3DREC task, highlighting its strong ability to parse implicit spatial cues.
SeqVLM: Proposal-Guided Multi-View Sequences Reasoning via VLM for Zero-Shot 3D Visual Grounding
Aug 28, 2025
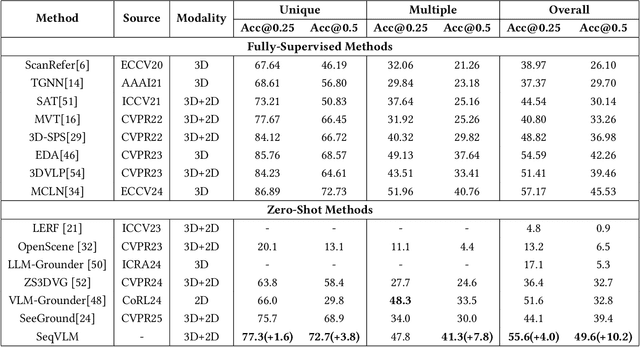

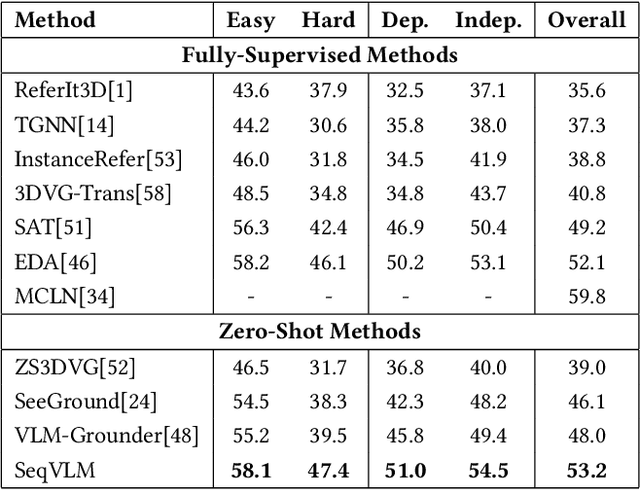
3D Visual Grounding (3DVG) aims to localize objects in 3D scenes using natural language descriptions. Although supervised methods achieve higher accuracy in constrained settings, zero-shot 3DVG holds greater promise for real-world applications since eliminating scene-specific training requirements. However, existing zero-shot methods face challenges of spatial-limited reasoning due to reliance on single-view localization, and contextual omissions or detail degradation. To address these issues, we propose SeqVLM, a novel zero-shot 3DVG framework that leverages multi-view real-world scene images with spatial information for target object reasoning. Specifically, SeqVLM first generates 3D instance proposals via a 3D semantic segmentation network and refines them through semantic filtering, retaining only semantic-relevant candidates. A proposal-guided multi-view projection strategy then projects these candidate proposals onto real scene image sequences, preserving spatial relationships and contextual details in the conversion process of 3D point cloud to images. Furthermore, to mitigate VLM computational overload, we implement a dynamic scheduling mechanism that iteratively processes sequances-query prompts, leveraging VLM's cross-modal reasoning capabilities to identify textually specified objects. Experiments on the ScanRefer and Nr3D benchmarks demonstrate state-of-the-art performance, achieving Acc@0.25 scores of 55.6% and 53.2%, surpassing previous zero-shot methods by 4.0% and 5.2%, respectively, which advance 3DVG toward greater generalization and real-world applicability. The code is available at https://github.com/JiawLin/SeqVLM.
Segment Concealed Objects with Incomplete Supervision
Jun 10, 2025Incompletely-Supervised Concealed Object Segmentation (ISCOS) involves segmenting objects that seamlessly blend into their surrounding environments, utilizing incompletely annotated data, such as weak and semi-annotations, for model training. This task remains highly challenging due to (1) the limited supervision provided by the incompletely annotated training data, and (2) the difficulty of distinguishing concealed objects from the background, which arises from the intrinsic similarities in concealed scenarios. In this paper, we introduce the first unified method for ISCOS to address these challenges. To tackle the issue of incomplete supervision, we propose a unified mean-teacher framework, SEE, that leverages the vision foundation model, ``\emph{Segment Anything Model (SAM)}'', to generate pseudo-labels using coarse masks produced by the teacher model as prompts. To mitigate the effect of low-quality segmentation masks, we introduce a series of strategies for pseudo-label generation, storage, and supervision. These strategies aim to produce informative pseudo-labels, store the best pseudo-labels generated, and select the most reliable components to guide the student model, thereby ensuring robust network training. Additionally, to tackle the issue of intrinsic similarity, we design a hybrid-granularity feature grouping module that groups features at different granularities and aggregates these results. By clustering similar features, this module promotes segmentation coherence, facilitating more complete segmentation for both single-object and multiple-object images. We validate the effectiveness of our approach across multiple ISCOS tasks, and experimental results demonstrate that our method achieves state-of-the-art performance. Furthermore, SEE can serve as a plug-and-play solution, enhancing the performance of existing models.
* IEEE TPAMI
A Plug-and-Play Physical Motion Restoration Approach for In-the-Wild High-Difficulty Motions
Dec 23, 2024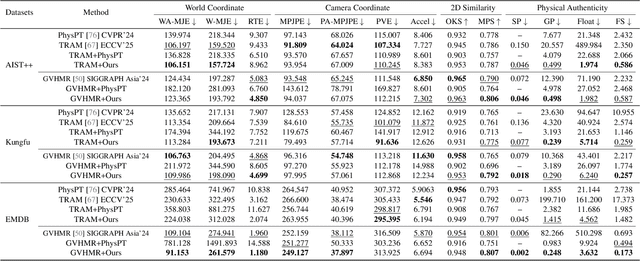
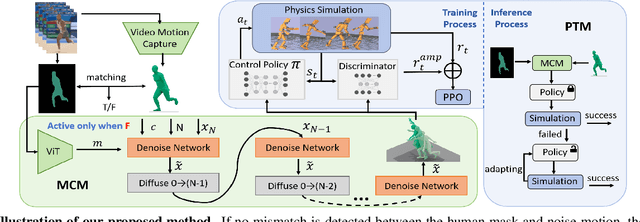
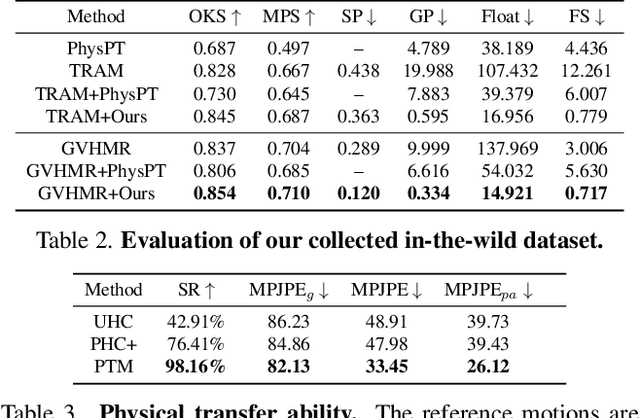

Extracting physically plausible 3D human motion from videos is a critical task. Although existing simulation-based motion imitation methods can enhance the physical quality of daily motions estimated from monocular video capture, extending this capability to high-difficulty motions remains an open challenge. This can be attributed to some flawed motion clips in video-based motion capture results and the inherent complexity in modeling high-difficulty motions. Therefore, sensing the advantage of segmentation in localizing human body, we introduce a mask-based motion correction module (MCM) that leverages motion context and video mask to repair flawed motions, producing imitation-friendly motions; and propose a physics-based motion transfer module (PTM), which employs a pretrain and adapt approach for motion imitation, improving physical plausibility with the ability to handle in-the-wild and challenging motions. Our approach is designed as a plug-and-play module to physically refine the video motion capture results, including high-difficulty in-the-wild motions. Finally, to validate our approach, we collected a challenging in-the-wild test set to establish a benchmark, and our method has demonstrated effectiveness on both the new benchmark and existing public datasets.https://physicalmotionrestoration.github.io
InterDance:Reactive 3D Dance Generation with Realistic Duet Interactions
Dec 22, 2024



Humans perform a variety of interactive motions, among which duet dance is one of the most challenging interactions. However, in terms of human motion generative models, existing works are still unable to generate high-quality interactive motions, especially in the field of duet dance. On the one hand, it is due to the lack of large-scale high-quality datasets. On the other hand, it arises from the incomplete representation of interactive motion and the lack of fine-grained optimization of interactions. To address these challenges, we propose, InterDance, a large-scale duet dance dataset that significantly enhances motion quality, data scale, and the variety of dance genres. Built upon this dataset, we propose a new motion representation that can accurately and comprehensively describe interactive motion. We further introduce a diffusion-based framework with an interaction refinement guidance strategy to optimize the realism of interactions progressively. Extensive experiments demonstrate the effectiveness of our dataset and algorithm.
AToM: Aligning Text-to-Motion Model at Event-Level with GPT-4Vision Reward
Nov 27, 2024



Recently, text-to-motion models have opened new possibilities for creating realistic human motion with greater efficiency and flexibility. However, aligning motion generation with event-level textual descriptions presents unique challenges due to the complex relationship between textual prompts and desired motion outcomes. To address this, we introduce AToM, a framework that enhances the alignment between generated motion and text prompts by leveraging reward from GPT-4Vision. AToM comprises three main stages: Firstly, we construct a dataset MotionPrefer that pairs three types of event-level textual prompts with generated motions, which cover the integrity, temporal relationship and frequency of motion. Secondly, we design a paradigm that utilizes GPT-4Vision for detailed motion annotation, including visual data formatting, task-specific instructions and scoring rules for each sub-task. Finally, we fine-tune an existing text-to-motion model using reinforcement learning guided by this paradigm. Experimental results demonstrate that AToM significantly improves the event-level alignment quality of text-to-motion generation.
Lodge++: High-quality and Long Dance Generation with Vivid Choreography Patterns
Oct 27, 2024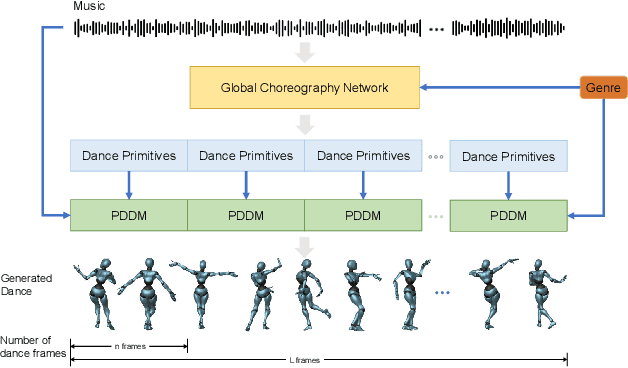
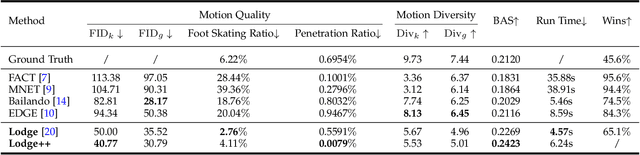
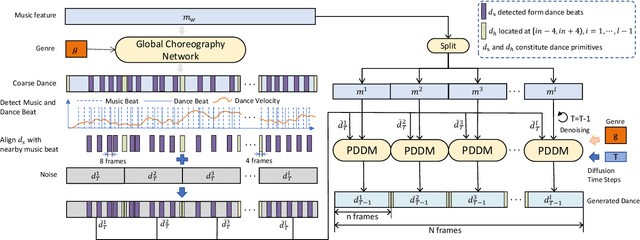
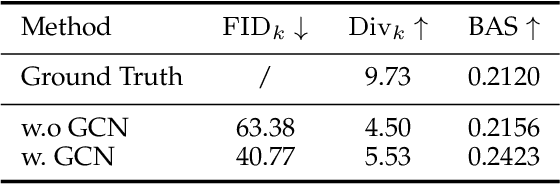
We propose Lodge++, a choreography framework to generate high-quality, ultra-long, and vivid dances given the music and desired genre. To handle the challenges in computational efficiency, the learning of complex and vivid global choreography patterns, and the physical quality of local dance movements, Lodge++ adopts a two-stage strategy to produce dances from coarse to fine. In the first stage, a global choreography network is designed to generate coarse-grained dance primitives that capture complex global choreography patterns. In the second stage, guided by these dance primitives, a primitive-based dance diffusion model is proposed to further generate high-quality, long-sequence dances in parallel, faithfully adhering to the complex choreography patterns. Additionally, to improve the physical plausibility, Lodge++ employs a penetration guidance module to resolve character self-penetration, a foot refinement module to optimize foot-ground contact, and a multi-genre discriminator to maintain genre consistency throughout the dance. Lodge++ is validated by extensive experiments, which show that our method can rapidly generate ultra-long dances suitable for various dance genres, ensuring well-organized global choreography patterns and high-quality local motion.
Fusion-then-Distillation: Toward Cross-modal Positive Distillation for Domain Adaptive 3D Semantic Segmentation
Oct 25, 2024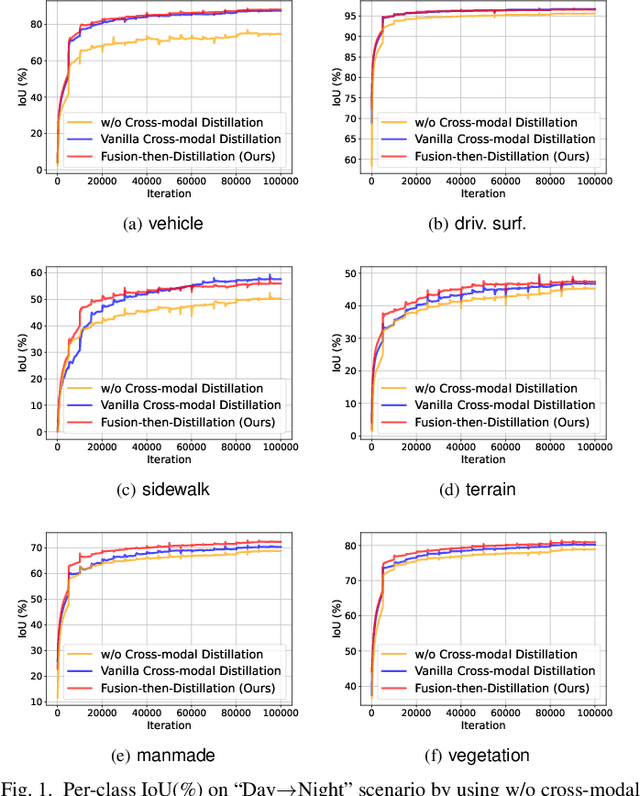
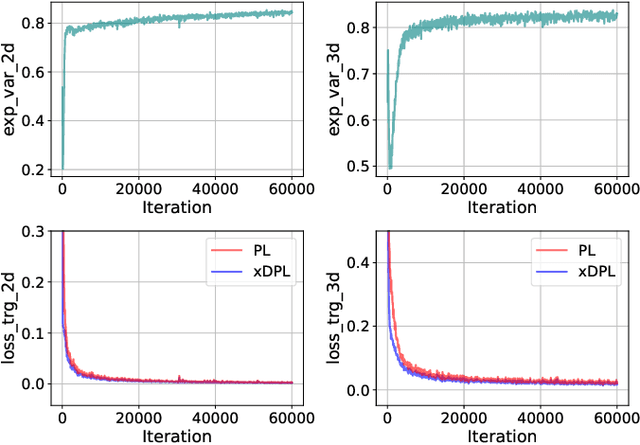
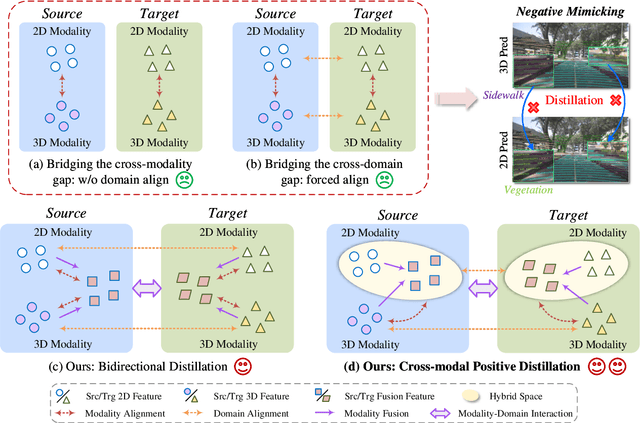
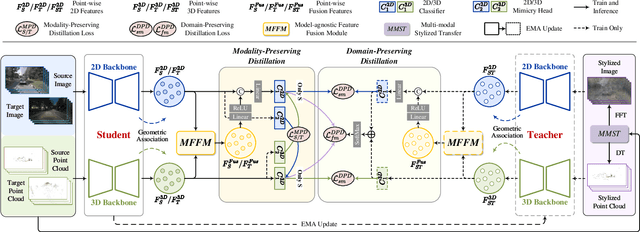
In cross-modal unsupervised domain adaptation, a model trained on source-domain data (e.g., synthetic) is adapted to target-domain data (e.g., real-world) without access to target annotation. Previous methods seek to mutually mimic cross-modal outputs in each domain, which enforces a class probability distribution that is agreeable in different domains. However, they overlook the complementarity brought by the heterogeneous fusion in cross-modal learning. In light of this, we propose a novel fusion-then-distillation (FtD++) method to explore cross-modal positive distillation of the source and target domains for 3D semantic segmentation. FtD++ realizes distribution consistency between outputs not only for 2D images and 3D point clouds but also for source-domain and augment-domain. Specially, our method contains three key ingredients. First, we present a model-agnostic feature fusion module to generate the cross-modal fusion representation for establishing a latent space. In this space, two modalities are enforced maximum correlation and complementarity. Second, the proposed cross-modal positive distillation preserves the complete information of multi-modal input and combines the semantic content of the source domain with the style of the target domain, thereby achieving domain-modality alignment. Finally, cross-modal debiased pseudo-labeling is devised to model the uncertainty of pseudo-labels via a self-training manner. Extensive experiments report state-of-the-art results on several domain adaptive scenarios under unsupervised and semi-supervised settings. Code is available at https://github.com/Barcaaaa/FtD-PlusPlus.
Robust Pseudo-label Learning with Neighbor Relation for Unsupervised Visible-Infrared Person Re-Identification
May 09, 2024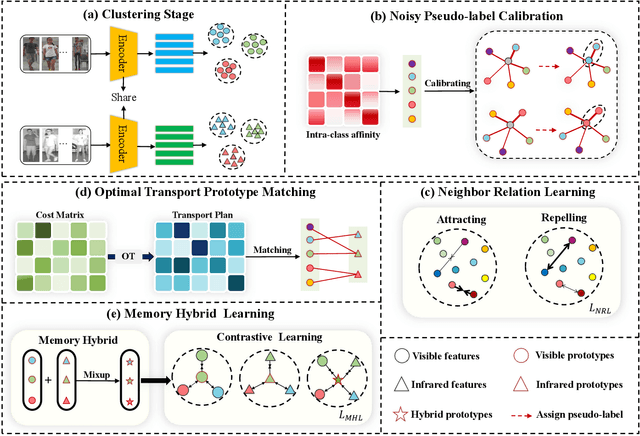
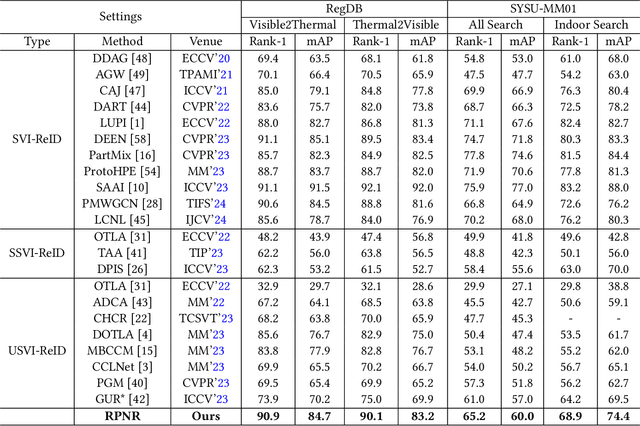
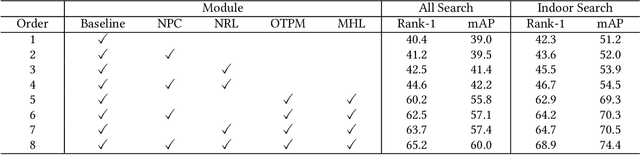

Unsupervised Visible-Infrared Person Re-identification (USVI-ReID) presents a formidable challenge, which aims to match pedestrian images across visible and infrared modalities without any annotations. Recently, clustered pseudo-label methods have become predominant in USVI-ReID, although the inherent noise in pseudo-labels presents a significant obstacle. Most existing works primarily focus on shielding the model from the harmful effects of noise, neglecting to calibrate noisy pseudo-labels usually associated with hard samples, which will compromise the robustness of the model. To address this issue, we design a Robust Pseudo-label Learning with Neighbor Relation (RPNR) framework for USVI-ReID. To be specific, we first introduce a straightforward yet potent Noisy Pseudo-label Calibration module to correct noisy pseudo-labels. Due to the high intra-class variations, noisy pseudo-labels are difficult to calibrate completely. Therefore, we introduce a Neighbor Relation Learning module to reduce high intra-class variations by modeling potential interactions between all samples. Subsequently, we devise an Optimal Transport Prototype Matching module to establish reliable cross-modality correspondences. On that basis, we design a Memory Hybrid Learning module to jointly learn modality-specific and modality-invariant information. Comprehensive experiments conducted on two widely recognized benchmarks, SYSU-MM01 and RegDB, demonstrate that RPNR outperforms the current state-of-the-art GUR with an average Rank-1 improvement of 10.3%. The source codes will be released soon.
Lodge: A Coarse to Fine Diffusion Network for Long Dance Generation Guided by the Characteristic Dance Primitives
Mar 26, 2024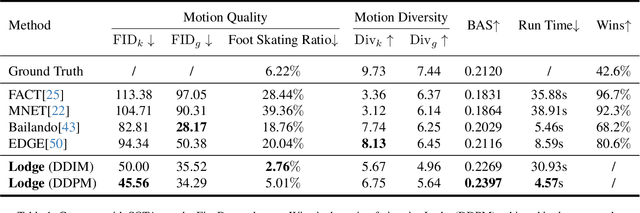
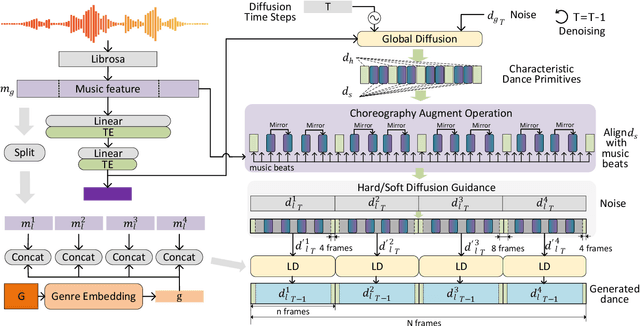


We propose Lodge, a network capable of generating extremely long dance sequences conditioned on given music. We design Lodge as a two-stage coarse to fine diffusion architecture, and propose the characteristic dance primitives that possess significant expressiveness as intermediate representations between two diffusion models. The first stage is global diffusion, which focuses on comprehending the coarse-level music-dance correlation and production characteristic dance primitives. In contrast, the second-stage is the local diffusion, which parallelly generates detailed motion sequences under the guidance of the dance primitives and choreographic rules. In addition, we propose a Foot Refine Block to optimize the contact between the feet and the ground, enhancing the physical realism of the motion. Our approach can parallelly generate dance sequences of extremely long length, striking a balance between global choreographic patterns and local motion quality and expressiveness. Extensive experiments validate the efficacy of our method.