 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierCVAE: Hierarchical Attention-Driven Conditional Variational Autoencoders for Multi-Scale Temporal Modeling
Aug 26, 2025Temporal modeling in complex systems requires capturing dependencies across multiple time scales while managing inherent uncertainties. We propose HierCVAE, a novel architecture that integrates hierarchical attention mechanisms with conditional variational autoencoders to address these challenges. HierCVAE employs a three-tier attention structure (local, global, cross-temporal) combined with multi-modal condition encoding to capture temporal, statistical, and trend information. The approach incorporates ResFormer blocks in the latent space and provides explicit uncertainty quantification via prediction heads. Through evaluations on energy consumption datasets, HierCVAE demonstrates a 15-40% improvement in prediction accuracy and superior uncertainty calibration compared to state-of-the-art methods, excelling in long-term forecasting and complex multi-variate dependencies.
Investigating and Mitigating Stereotype-aware Unfairness in LLM-based Recommendations
Apr 05, 2025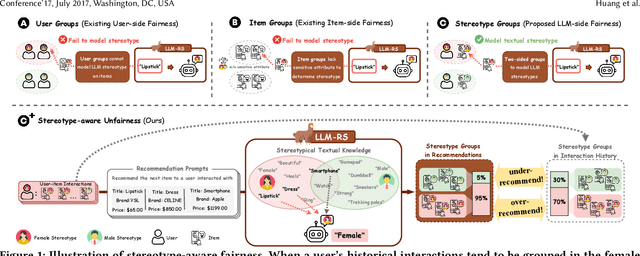

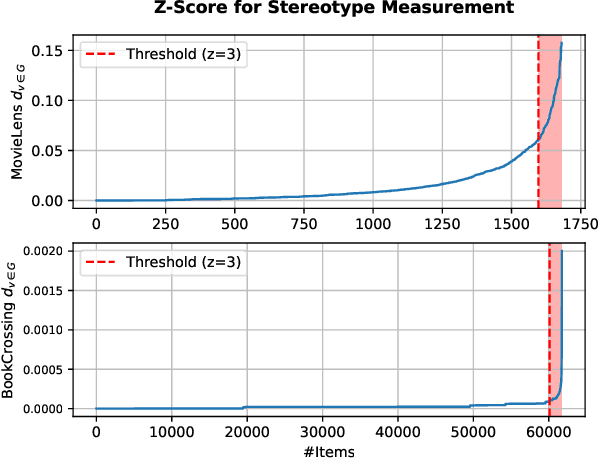
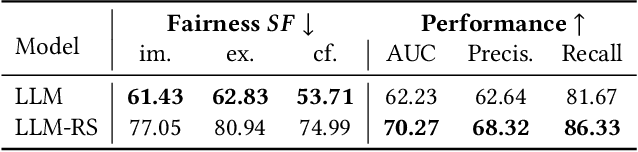
Large Language Models (LLMs) have demonstrated unprecedented language understanding and reasoning capabilities to capture diverse user preferences and advance personalized recommendations. Despite the growing interest in LLM-based personalized recommendations, unique challenges are brought to the trustworthiness of LLM-based recommender systems (LLM-RS), since LLMs are likely to inherit stereotypes that are embedded ubiquitously in word embeddings due to their training on large-scale uncurated datasets. This leads to LLM-RS exhibiting stereotypical linguistic associations between users and items. However, there remains a lack of studies investigating the simultaneous existence of stereotypes between users and items in LLM-RS. To bridge this gap, this study reveals a new variant of fairness between stereotype groups containing both users and items, to quantify discrimination against stereotypes in LLM-RS. Moreover, in this paper, to mitigate stereotype-aware unfairness in textual user and item information, we propose a novel framework (MoS), in which an insightful stereotype-wise routing strategy over multiple stereotype-relevant experts is designed to learn unbiased representations against different stereotypes in LLM- RS. Extensive experiments are conducted to analyze the influence of stereotype-aware fairness in LLM-RS and the effectiveness of our proposed methods, which consistently outperform competitive benchmarks under various fairness settings.
CLIP-FSAC++: Few-Shot Anomaly Classification with Anomaly Descriptor Based on CLIP
Dec 05, 2024



Industrial anomaly classification (AC) is an indispensable task in industrial manufacturing, which guarantees quality and safety of various product. To address the scarcity of data in industrial scenarios, lots of few-shot anomaly detection methods emerge recently. In this paper, we propose an effective few-shot anomaly classification (FSAC) framework with one-stage training, dubbed CLIP-FSAC++. Specifically, we introduce a cross-modality interaction module named Anomaly Descriptor following image and text encoders, which enhances the correlation of visual and text embeddings and adapts the representations of CLIP from pre-trained data to target data. In anomaly descriptor, image-to-text cross-attention module is used to obtain image-specific text embeddings and text-to-image cross-attention module is used to obtain text-specific visual embeddings. Then these modality-specific embeddings are used to enhance original representations of CLIP for better matching ability. Comprehensive experiment results are provided for evaluating our method in few-normal shot anomaly classification on VisA and MVTEC-AD for 1, 2, 4 and 8-shot settings. The source codes are at https://github.com/Jay-zzcoder/clip-fsac-pp
Fusion-then-Distillation: Toward Cross-modal Positive Distillation for Domain Adaptive 3D Semantic Segmentation
Oct 25, 2024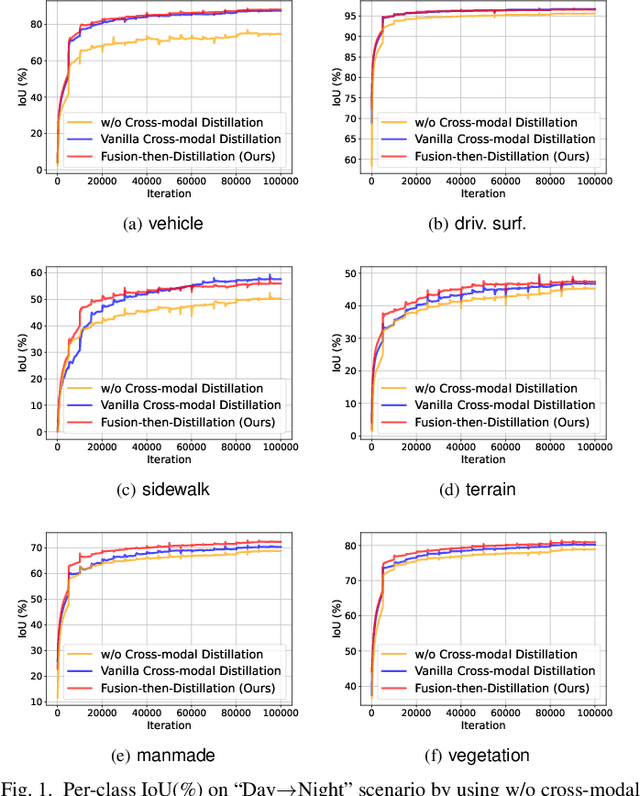
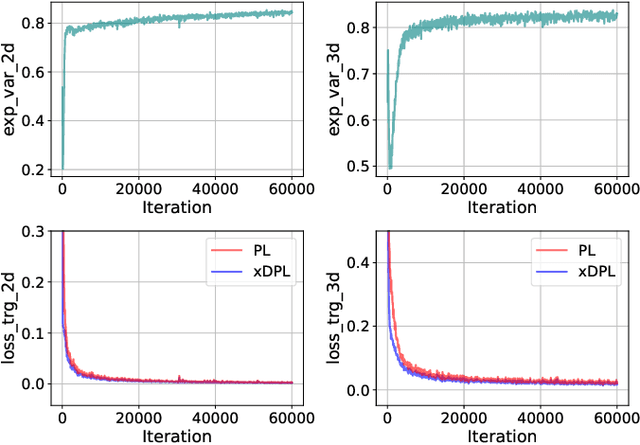
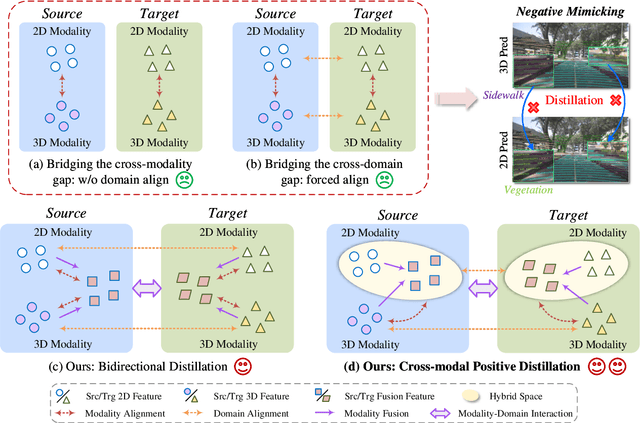
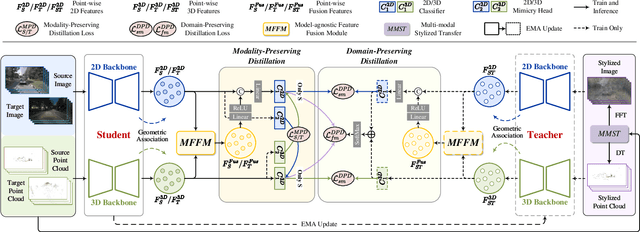
In cross-modal unsupervised domain adaptation, a model trained on source-domain data (e.g., synthetic) is adapted to target-domain data (e.g., real-world) without access to target annotation. Previous methods seek to mutually mimic cross-modal outputs in each domain, which enforces a class probability distribution that is agreeable in different domains. However, they overlook the complementarity brought by the heterogeneous fusion in cross-modal learning. In light of this, we propose a novel fusion-then-distillation (FtD++) method to explore cross-modal positive distillation of the source and target domains for 3D semantic segmentation. FtD++ realizes distribution consistency between outputs not only for 2D images and 3D point clouds but also for source-domain and augment-domain. Specially, our method contains three key ingredients. First, we present a model-agnostic feature fusion module to generate the cross-modal fusion representation for establishing a latent space. In this space, two modalities are enforced maximum correlation and complementarity. Second, the proposed cross-modal positive distillation preserves the complete information of multi-modal input and combines the semantic content of the source domain with the style of the target domain, thereby achieving domain-modality alignment. Finally, cross-modal debiased pseudo-labeling is devised to model the uncertainty of pseudo-labels via a self-training manner. Extensive experiments report state-of-the-art results on several domain adaptive scenarios under unsupervised and semi-supervised settings. Code is available at https://github.com/Barcaaaa/FtD-PlusPlus.
CLIP3D-AD: Extending CLIP for 3D Few-Shot Anomaly Detection with Multi-View Images Generation
Jun 27, 2024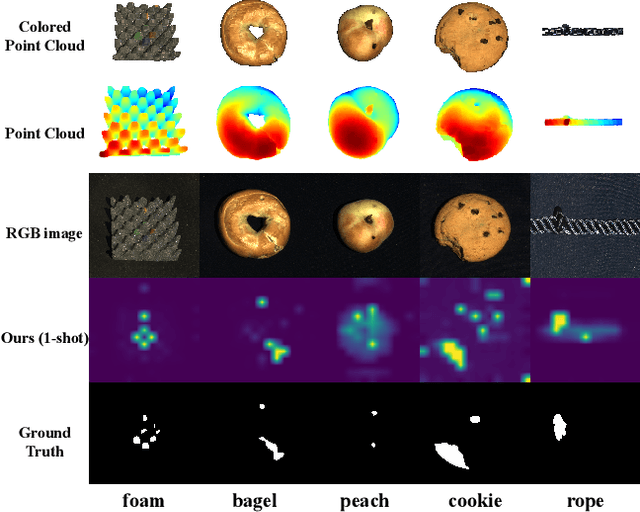
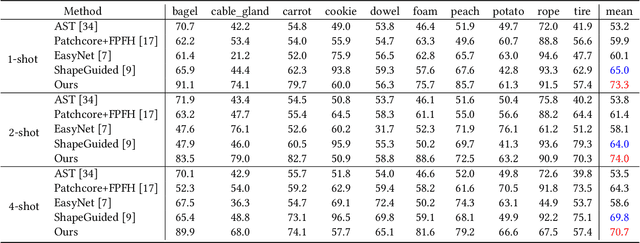
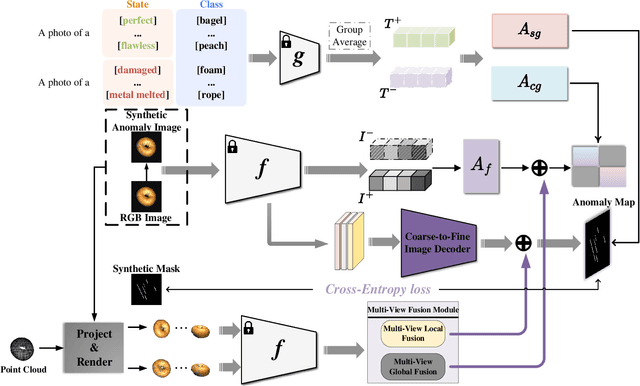
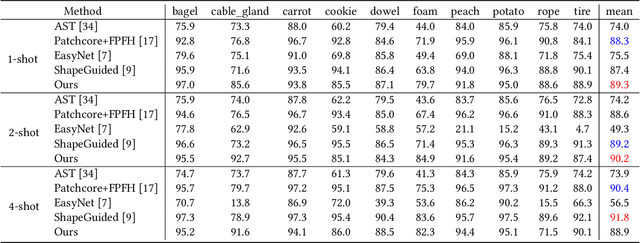
Few-shot anomaly detection methods can effectively address data collecting difficulty in industrial scenarios. Compared to 2D few-shot anomaly detection (2D-FSAD), 3D few-shot anomaly detection (3D-FSAD) is still an unexplored but essential task. In this paper, we propose CLIP3D-AD, an efficient 3D-FSAD method extended on CLIP. We successfully transfer strong generalization ability of CLIP into 3D-FSAD. Specifically, we synthesize anomalous images on given normal images as sample pairs to adapt CLIP for 3D anomaly classification and segmentation. For classification, we introduce an image adapter and a text adapter to fine-tune global visual features and text features. Meanwhile, we propose a coarse-to-fine decoder to fuse and facilitate intermediate multi-layer visual representations of CLIP. To benefit from geometry information of point cloud and eliminate modality and data discrepancy when processed by CLIP, we project and render point cloud to multi-view normal and anomalous images. Then we design multi-view fusion module to fuse features of multi-view images extracted by CLIP which are used to facilitate visual representations for further enhancing vision-language correlation. Extensive experiments demonstrate that our method has a competitive performance of 3D few-shot anomaly classification and segmentation on MVTec-3D AD dataset.
Anomaly Multi-classification in Industrial Scenarios: Transferring Few-shot Learning to a New Task
Jun 09, 2024



In industrial scenarios, it is crucial not only to identify anomalous items but also to classify the type of anomaly. However, research on anomaly multi-classification remains largely unexplored. This paper proposes a novel and valuable research task called anomaly multi-classification. Given the challenges in applying few-shot learning to this task, due to limited training data and unique characteristics of anomaly images, we introduce a baseline model that combines RelationNet and PatchCore. We propose a data generation method that creates pseudo classes and a corresponding proxy task, aiming to bridge the gap in transferring few-shot learning to industrial scenarios. Furthermore, we utilize contrastive learning to improve the vanilla baseline, achieving much better performance than directly fine-tune a ResNet. Experiments conducted on MvTec AD and MvTec3D AD demonstrate that our approach shows superior performance in this novel task.
Decoupling Representation and Knowledge for Few-Shot Intent Classification and Slot Filling
Dec 21, 2023



Few-shot intent classification and slot filling are important but challenging tasks due to the scarcity of finely labeled data. Therefore, current works first train a model on source domains with sufficiently labeled data, and then transfer the model to target domains where only rarely labeled data is available. However, experience transferring as a whole usually suffers from gaps that exist among source domains and target domains. For instance, transferring domain-specific-knowledge-related experience is difficult. To tackle this problem, we propose a new method that explicitly decouples the transferring of general-semantic-representation-related experience and the domain-specific-knowledge-related experience. Specifically, for domain-specific-knowledge-related experience, we design two modules to capture intent-slot relation and slot-slot relation respectively. Extensive experiments on Snips and FewJoint datasets show that our method achieves state-of-the-art performance. The method improves the joint accuracy metric from 27.72% to 42.20% in the 1-shot setting, and from 46.54% to 60.79% in the 5-shot setting.
Topology-inspired Cross-domain Network for Developmental Cervical Stenosis Quantification
Sep 18, 2023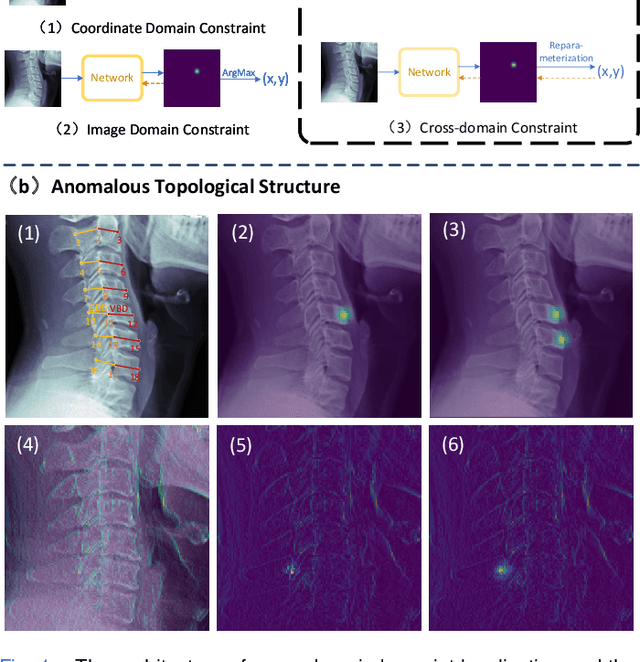
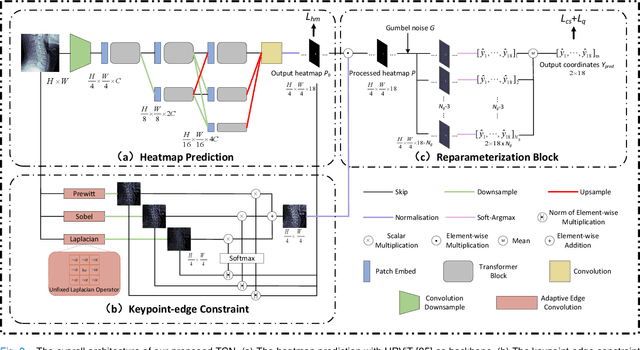
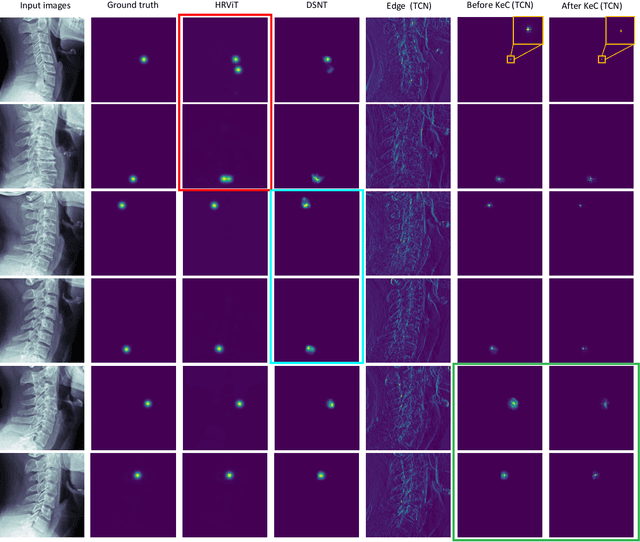
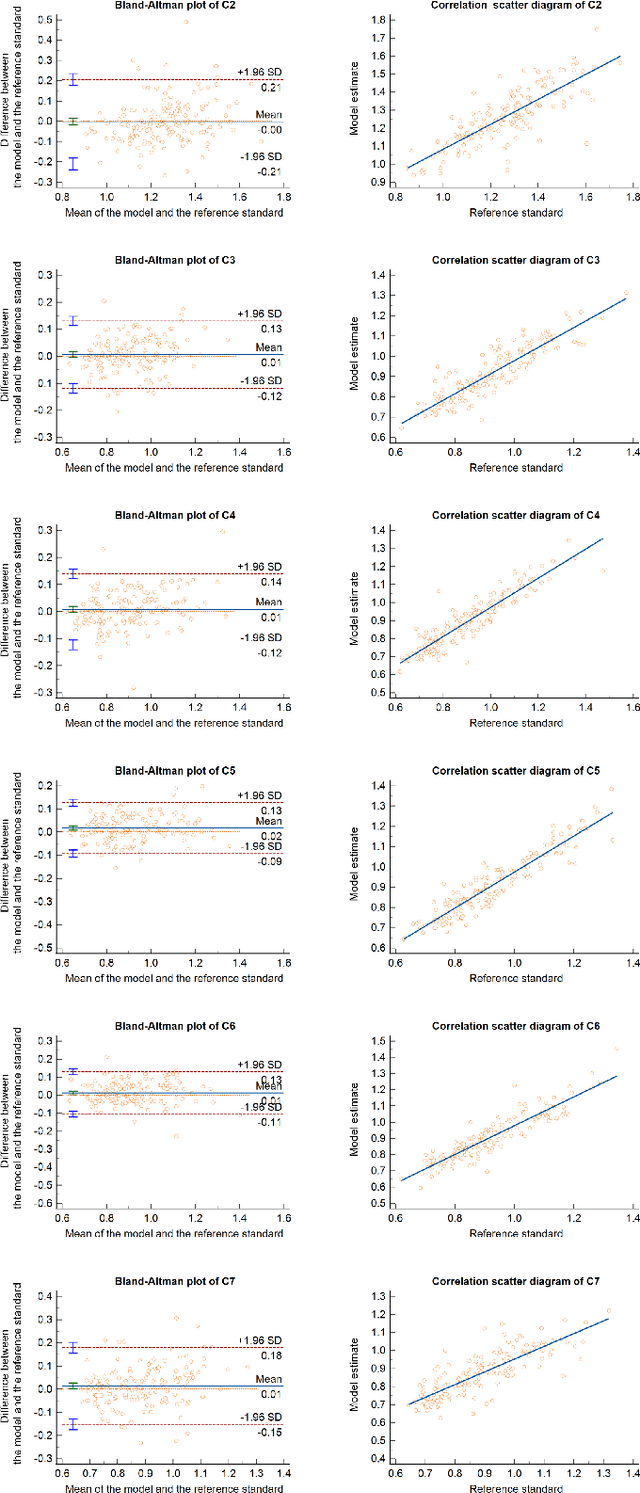
Developmental Canal Stenosis (DCS) quantification is crucial in cervical spondylosis screening. Compared with quantifying DCS manually, a more efficient and time-saving manner is provided by deep keypoint localization networks, which can be implemented in either the coordinate or the image domain. However, the vertebral visualization features often lead to abnormal topological structures during keypoint localization, including keypoint distortion with edges and weakly connected structures, which cannot be fully suppressed in either the coordinate or image domain alone. To overcome this limitation, a keypoint-edge and a reparameterization modules are utilized to restrict these abnormal structures in a cross-domain manner. The keypoint-edge constraint module restricts the keypoints on the edges of vertebrae, which ensures that the distribution pattern of keypoint coordinates is consistent with those for DCS quantification. And the reparameterization module constrains the weakly connected structures in image-domain heatmaps with coordinates combined. Moreover, the cross-domain network improves spatial generalization by utilizing heatmaps and incorporating coordinates for accurate localization, which avoids the trade-off between these two properties in an individual domain. Comprehensive results of distinct quantification tasks show the superiority and generability of the proposed Topology-inspired Cross-domain Network (TCN) compared with other competing localization methods.
TFROM: A Two-sided Fairness-Aware Recommendation Model for Both Customers and Providers
Apr 19, 2021



At present, most research on the fairness of recommender systems is conducted either from the perspective of customers or from the perspective of product (or service) providers. However, such a practice ignores the fact that when fairness is guaranteed to one side, the fairness and rights of the other side are likely to reduce. In this paper, we consider recommendation scenarios from the perspective of two sides (customers and providers). From the perspective of providers, we consider the fairness of the providers' exposure in recommender system. For customers, we consider the fairness of the reduced quality of recommendation results due to the introduction of fairness measures. We theoretically analyzed the relationship between recommendation quality, customers fairness, and provider fairness, and design a two-sided fairness-aware recommendation model (TFROM) for both customers and providers. Specifically, we design two versions of TFROM for offline and online recommendation. The effectiveness of the model is verified on three real-world data sets. The experimental results show that TFROM provides better two-sided fairness while still maintaining a higher level of personalization than the baseline algorithms.
FAST: A Fairness Assured Service Recommendation Strategy Considering Service Capacity Constraint
Dec 02, 2020

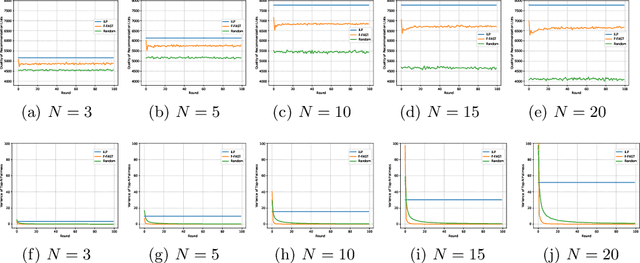

An excessive number of customers often leads to a degradation in service quality. However, the capacity constraints of services are ignored by recommender systems, which may lead to unsatisfactory recommendation. This problem can be solved by limiting the number of users who receive the recommendation for a service, but this may be viewed as unfair. In this paper, we propose a novel metric Top-N Fairness to measure the individual fairness of multi-round recommendations of services with capacity constraints. By considering the fact that users are often only affected by top-ranked items in a recommendation, Top-N Fairness only considers a sub-list consisting of top N services. Based on the metric, we design FAST, a Fairness Assured service recommendation STrategy. FAST adjusts the original recommendation list to provide users with recommendation results that guarantee the long-term fairness of multi-round recommendations. We prove the convergence property of the variance of Top-N Fairness of FAST theoretically. FAST is tested on the Yelp dataset and synthetic datasets. The experimental results show that FAST achieves better recommendation fairness while still maintaining high recommendation quality.