 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKID: Knowledge-Injected Dual-Head Learning for Knowledge-Grounded Harmful Meme Detection
Jan 29, 2026Internet memes have become pervasive carriers of digital culture on social platforms. However, their heavy reliance on metaphors and sociocultural context also makes them subtle vehicles for harmful content, posing significant challenges for automated content moderation. Existing approaches primarily focus on intra-modal and inter-modal signal analysis, while the understanding of implicit toxicity often depends on background knowledge that is not explicitly present in the meme itself. To address this challenge, we propose KID, a Knowledge-Injected Dual-Head Learning framework for knowledge-grounded harmful meme detection. KID adopts a label-constrained distillation paradigm to decompose complex meme understanding into structured reasoning chains that explicitly link visual evidence, background knowledge, and classification labels. These chains guide the learning process by grounding external knowledge in meme-specific contexts. In addition, KID employs a dual-head architecture that jointly optimizes semantic generation and classification objectives, enabling aligned linguistic reasoning while maintaining stable decision boundaries. Extensive experiments on five multilingual datasets spanning English, Chinese, and low-resource Bengali demonstrate that KID achieves SOTA performance on both binary and multi-label harmful meme detection tasks, improving over previous best methods by 2.1%--19.7% across primary evaluation metrics. Ablation studies further confirm the effectiveness of knowledge injection and dual-head joint learning, highlighting their complementary contributions to robust and generalizable meme understanding. The code and data are available at https://github.com/PotatoDog1669/KID.
PRISM: A Personality-Driven Multi-Agent Framework for Social Media Simulation
Dec 22, 2025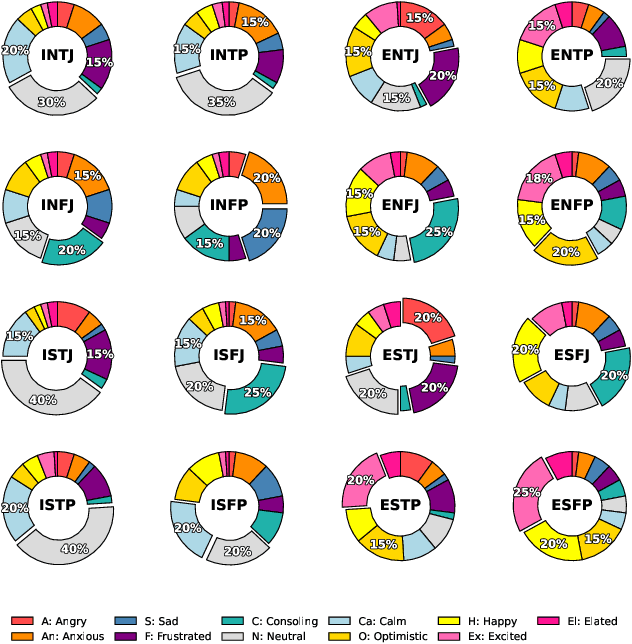
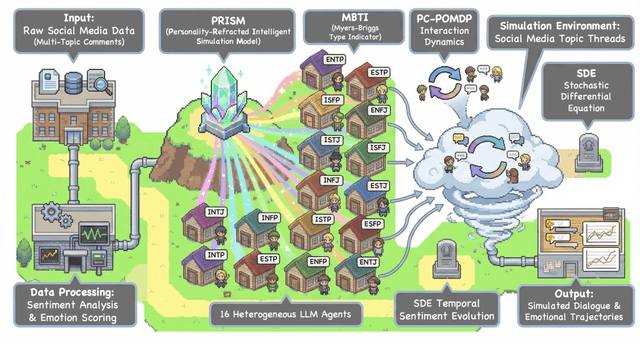
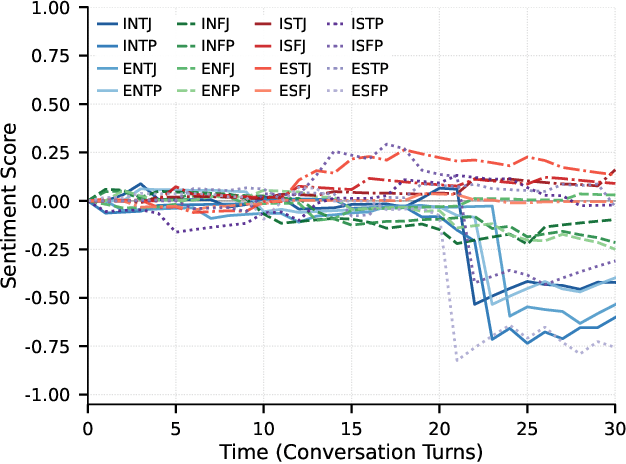

Traditional agent-based models (ABMs) of opinion dynamics often fail to capture the psychological heterogeneity driving online polarization due to simplistic homogeneity assumptions. This limitation obscures the critical interplay between individual cognitive biases and information propagation, thereby hindering a mechanistic understanding of how ideological divides are amplified. To address this challenge, we introduce the Personality-Refracted Intelligent Simulation Model (PRISM), a hybrid framework coupling stochastic differential equations (SDE) for continuous emotional evolution with a personality-conditional partially observable Markov decision process (PC-POMDP) for discrete decision-making. In contrast to continuous trait approaches, PRISM assigns distinct Myers-Briggs Type Indicator (MBTI) based cognitive policies to multimodal large language model (MLLM) agents, initialized via data-driven priors from large-scale social media datasets. PRISM achieves superior personality consistency aligned with human ground truth, significantly outperforming standard homogeneous and Big Five benchmarks. This framework effectively replicates emergent phenomena such as rational suppression and affective resonance, offering a robust tool for analyzing complex social media ecosystems.
Addressing Personalized Bias for Unbiased Learning to Rank
Aug 28, 2025Unbiased learning to rank (ULTR), which aims to learn unbiased ranking models from biased user behavior logs, plays an important role in Web search. Previous research on ULTR has studied a variety of biases in users' clicks, such as position bias, presentation bias, and outlier bias. However, existing work often assumes that the behavior logs are collected from an ``average'' user, neglecting the differences between different users in their search and browsing behaviors. In this paper, we introduce personalized factors into the ULTR framework, which we term the user-aware ULTR problem. Through a formal causal analysis of this problem, we demonstrate that existing user-oblivious methods are biased when different users have different preferences over queries and personalized propensities of examining documents. To address such a personalized bias, we propose a novel user-aware inverse-propensity-score estimator for learning-to-rank objectives. Specifically, our approach models the distribution of user browsing behaviors for each query and aggregates user-weighted examination probabilities to determine propensities. We theoretically prove that the user-aware estimator is unbiased under some mild assumptions and shows lower variance compared to the straightforward way of calculating a user-dependent propensity for each impression. Finally, we empirically verify the effectiveness of our user-aware estimator by conducting extensive experiments on two semi-synthetic datasets and a real-world dataset.
CAPE: Context-Aware Prompt Perturbation Mechanism with Differential Privacy
May 09, 2025



Large Language Models (LLMs) have gained significant popularity due to their remarkable capabilities in text understanding and generation. However, despite their widespread deployment in inference services such as ChatGPT, concerns about the potential leakage of sensitive user data have arisen. Existing solutions primarily rely on privacy-enhancing technologies to mitigate such risks, facing the trade-off among efficiency, privacy, and utility. To narrow this gap, we propose Cape, a context-aware prompt perturbation mechanism based on differential privacy, to enable efficient inference with an improved privacy-utility trade-off. Concretely, we introduce a hybrid utility function that better captures the token similarity. Additionally, we propose a bucketized sampling mechanism to handle large sampling space, which might lead to long-tail phenomenons. Extensive experiments across multiple datasets, along with ablation studies, demonstrate that Cape achieves a better privacy-utility trade-off compared to prior state-of-the-art works.
TrustRAG: An Information Assistant with Retrieval Augmented Generation
Feb 19, 2025\Ac{RAG} has emerged as a crucial technique for enhancing large models with real-time and domain-specific knowledge. While numerous improvements and open-source tools have been proposed to refine the \ac{RAG} framework for accuracy, relatively little attention has been given to improving the trustworthiness of generated results. To address this gap, we introduce TrustRAG, a novel framework that enhances \ac{RAG} from three perspectives: indexing, retrieval, and generation. Specifically, in the indexing stage, we propose a semantic-enhanced chunking strategy that incorporates hierarchical indexing to supplement each chunk with contextual information, ensuring semantic completeness. In the retrieval stage, we introduce a utility-based filtering mechanism to identify high-quality information, supporting answer generation while reducing input length. In the generation stage, we propose fine-grained citation enhancement, which detects opinion-bearing sentences in responses and infers citation relationships at the sentence-level, thereby improving citation accuracy. We open-source the TrustRAG framework and provide a demonstration studio designed for excerpt-based question answering tasks \footnote{https://huggingface.co/spaces/golaxy/TrustRAG}. Based on these, we aim to help researchers: 1) systematically enhancing the trustworthiness of \ac{RAG} systems and (2) developing their own \ac{RAG} systems with more reliable outputs.
INFELM: In-depth Fairness Evaluation of Large Text-To-Image Models
Jan 07, 2025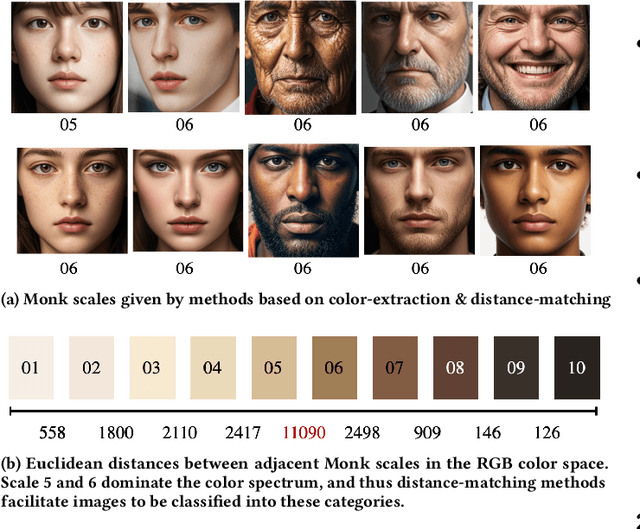


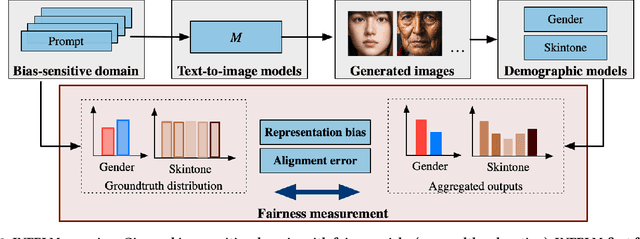
The rapid development of large language models (LLMs) and large vision models (LVMs) have propelled the evolution of multi-modal AI systems, which have demonstrated the remarkable potential for industrial applications by emulating human-like cognition. However, they also pose significant ethical challenges, including amplifying harmful content and reinforcing societal biases. For instance, biases in some industrial image generation models highlighted the urgent need for robust fairness assessments. Most existing evaluation frameworks focus on the comprehensiveness of various aspects of the models, but they exhibit critical limitations, including insufficient attention to content generation alignment and social bias-sensitive domains. More importantly, their reliance on pixel-detection techniques is prone to inaccuracies. To address these issues, this paper presents INFELM, an in-depth fairness evaluation on widely-used text-to-image models. Our key contributions are: (1) an advanced skintone classifier incorporating facial topology and refined skin pixel representation to enhance classification precision by at least 16.04%, (2) a bias-sensitive content alignment measurement for understanding societal impacts, (3) a generalizable representation bias evaluation for diverse demographic groups, and (4) extensive experiments analyzing large-scale text-to-image model outputs across six social-bias-sensitive domains. We find that existing models in the study generally do not meet the empirical fairness criteria, and representation bias is generally more pronounced than alignment errors. INFELM establishes a robust benchmark for fairness assessment, supporting the development of multi-modal AI systems that align with ethical and human-centric principles.
IDEAL: Leveraging Infinite and Dynamic Characterizations of Large Language Models for Query-focused Summarization
Jul 15, 2024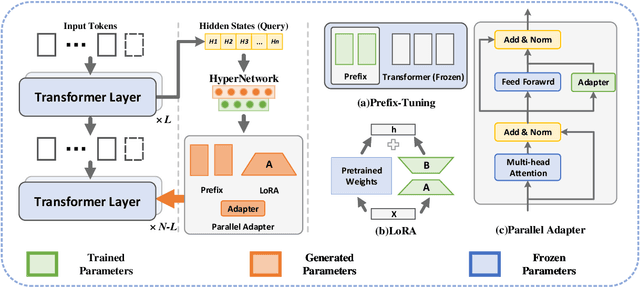
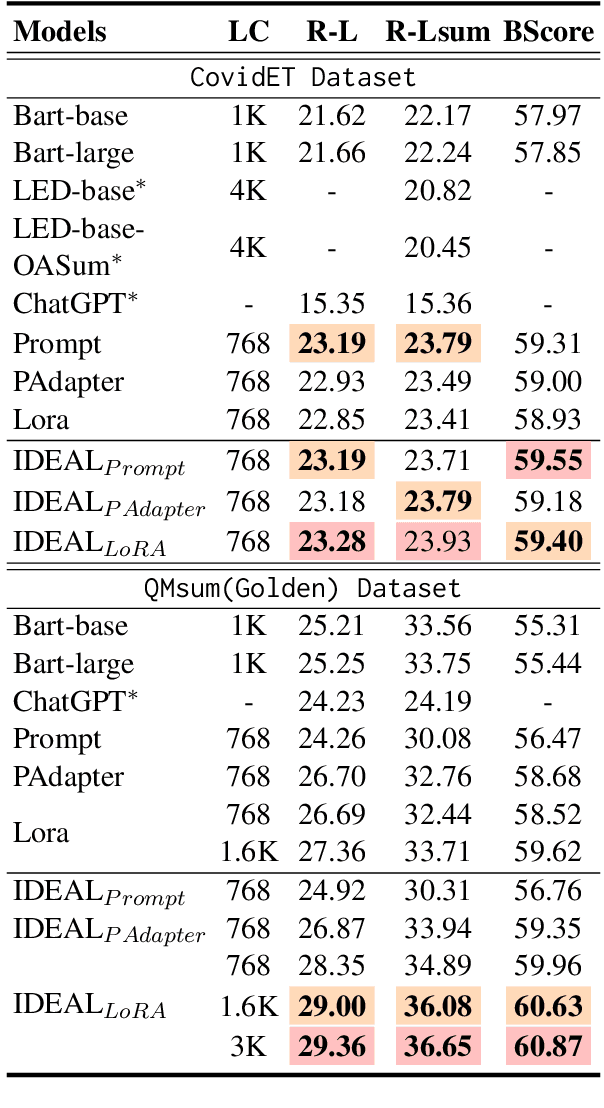
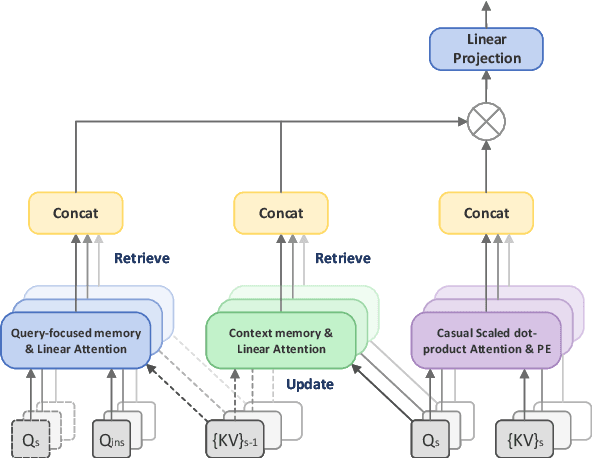
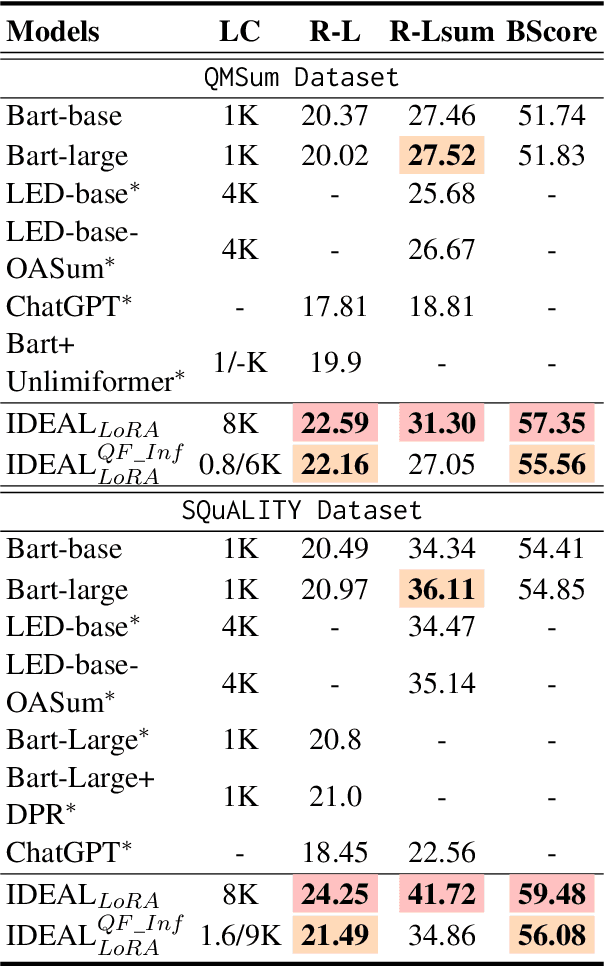
Query-focused summarization (QFS) aims to produce summaries that answer particular questions of interest, enabling greater user control and personalization. With the advent of large language models (LLMs), shows their impressive capability of textual understanding through large-scale pretraining, which implies the great potential of extractive snippet generation. In this paper, we systematically investigated two indispensable characteristics that the LLMs-based QFS models should be harnessed, Lengthy Document Summarization and Efficiently Fine-grained Query-LLM Alignment, respectively. Correspondingly, we propose two modules called Query-aware HyperExpert and Query-focused Infini-attention to access the aforementioned characteristics. These innovations pave the way for broader application and accessibility in the field of QFS technology. Extensive experiments conducted on existing QFS benchmarks indicate the effectiveness and generalizability of the proposed approach. Our code is publicly available at https://github.com/DCDmllm/IDEAL_Summary.
Budget Recycling Differential Privacy
Mar 18, 2024



Differential Privacy (DP) mechanisms usually {force} reduction in data utility by producing ``out-of-bound'' noisy results for a tight privacy budget. We introduce the Budget Recycling Differential Privacy (BR-DP) framework, designed to provide soft-bounded noisy outputs for a broad range of existing DP mechanisms. By ``soft-bounded," we refer to the mechanism's ability to release most outputs within a predefined error boundary, thereby improving utility and maintaining privacy simultaneously. The core of BR-DP consists of two components: a DP kernel responsible for generating a noisy answer per iteration, and a recycler that probabilistically recycles/regenerates or releases the noisy answer. We delve into the privacy accounting of BR-DP, culminating in the development of a budgeting principle that optimally sub-allocates the available budget between the DP kernel and the recycler. Furthermore, we introduce algorithms for tight BR-DP accounting in composition scenarios, and our findings indicate that BR-DP achieves reduced privacy leakage post-composition compared to DP. Additionally, we explore the concept of privacy amplification via subsampling within the BR-DP framework and propose optimal sampling rates for BR-DP across various queries. We experiment with real data, and the results demonstrate BR-DP's effectiveness in lifting the utility-privacy tradeoff provided by DP mechanisms.
AnonPSI: An Anonymity Assessment Framework for PSI
Nov 29, 2023



Private Set Intersection (PSI) is a widely used protocol that enables two parties to securely compute a function over the intersected part of their shared datasets and has been a significant research focus over the years. However, recent studies have highlighted its vulnerability to Set Membership Inference Attacks (SMIA), where an adversary might deduce an individual's membership by invoking multiple PSI protocols. This presents a considerable risk, even in the most stringent versions of PSI, which only return the cardinality of the intersection. This paper explores the evaluation of anonymity within the PSI context. Initially, we highlight the reasons why existing works fall short in measuring privacy leakage, and subsequently propose two attack strategies that address these deficiencies. Furthermore, we provide theoretical guarantees on the performance of our proposed methods. In addition to these, we illustrate how the integration of auxiliary information, such as the sum of payloads associated with members of the intersection (PSI-SUM), can enhance attack efficiency. We conducted a comprehensive performance evaluation of various attack strategies proposed utilizing two real datasets. Our findings indicate that the methods we propose markedly enhance attack efficiency when contrasted with previous research endeavors. {The effective attacking implies that depending solely on existing PSI protocols may not provide an adequate level of privacy assurance. It is recommended to combine privacy-enhancing technologies synergistically to enhance privacy protection even further.
G2T: A Simple but Effective Framework for Topic Modeling based on Pretrained Language Model and Community Detection
Apr 14, 2023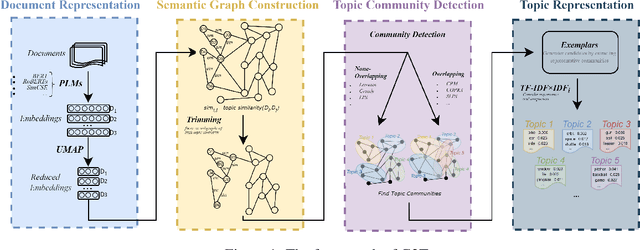
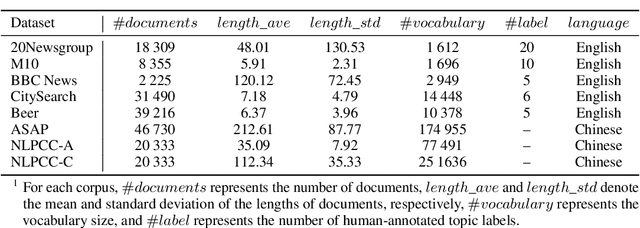

It has been reported that clustering-based topic models, which cluster high-quality sentence embeddings with an appropriate word selection method, can generate better topics than generative probabilistic topic models. However, these approaches suffer from the inability to select appropriate parameters and incomplete models that overlook the quantitative relation between words with topics and topics with text. To solve these issues, we propose graph to topic (G2T), a simple but effective framework for topic modelling. The framework is composed of four modules. First, document representation is acquired using pretrained language models. Second, a semantic graph is constructed according to the similarity between document representations. Third, communities in document semantic graphs are identified, and the relationship between topics and documents is quantified accordingly. Fourth, the word--topic distribution is computed based on a variant of TFIDF. Automatic evaluation suggests that G2T achieved state-of-the-art performance on both English and Chinese documents with different lengths. Human judgements demonstrate that G2T can produce topics with better interpretability and coverage than baselines. In addition, G2T can not only determine the topic number automatically but also give the probabilistic distribution of words in topics and topics in documents. Finally, G2T is publicly available, and the distillation experiments provide instruction on how it works.