 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-directional Bias Attribution: Debiasing Large Language Models without Modifying Prompts
Feb 04, 2026Large language models (LLMs) have demonstrated impressive capabilities across a wide range of natural language processing tasks. However, their outputs often exhibit social biases, raising fairness concerns. Existing debiasing methods, such as fine-tuning on additional datasets or prompt engineering, face scalability issues or compromise user experience in multi-turn interactions. To address these challenges, we propose a framework for detecting stereotype-inducing words and attributing neuron-level bias in LLMs, without the need for fine-tuning or prompt modification. Our framework first identifies stereotype-inducing adjectives and nouns via comparative analysis across demographic groups. We then attribute biased behavior to specific neurons using two attribution strategies based on integrated gradients. Finally, we mitigate bias by directly intervening on their activations at the projection layer. Experiments on three widely used LLMs demonstrate that our method effectively reduces bias while preserving overall model performance. Code is available at the github link: https://github.com/XMUDeepLIT/Bi-directional-Bias-Attribution.
LLM-OREF: An Open Relation Extraction Framework Based on Large Language Models
Sep 18, 2025The goal of open relation extraction (OpenRE) is to develop an RE model that can generalize to new relations not encountered during training. Existing studies primarily formulate OpenRE as a clustering task. They first cluster all test instances based on the similarity between the instances, and then manually assign a new relation to each cluster. However, their reliance on human annotation limits their practicality. In this paper, we propose an OpenRE framework based on large language models (LLMs), which directly predicts new relations for test instances by leveraging their strong language understanding and generation abilities, without human intervention. Specifically, our framework consists of two core components: (1) a relation discoverer (RD), designed to predict new relations for test instances based on \textit{demonstrations} formed by training instances with known relations; and (2) a relation predictor (RP), used to select the most likely relation for a test instance from $n$ candidate relations, guided by \textit{demonstrations} composed of their instances. To enhance the ability of our framework to predict new relations, we design a self-correcting inference strategy composed of three stages: relation discovery, relation denoising, and relation prediction. In the first stage, we use RD to preliminarily predict new relations for all test instances. Next, we apply RP to select some high-reliability test instances for each new relation from the prediction results of RD through a cross-validation method. During the third stage, we employ RP to re-predict the relations of all test instances based on the demonstrations constructed from these reliable test instances. Extensive experiments on three OpenRE datasets demonstrate the effectiveness of our framework. We release our code at https://github.com/XMUDeepLIT/LLM-OREF.git.
Learnable Sequence Augmenter for Triplet Contrastive Learning in Sequential Recommendation
Mar 26, 2025Most existing contrastive learning-based sequential recommendation (SR) methods rely on random operations (e.g., crop, reorder, and substitute) to generate augmented sequences. These methods often struggle to create positive sample pairs that closely resemble the representations of the raw sequences, potentially disrupting item correlations by deleting key items or introducing noisy iterac, which misguides the contrastive learning process. To address this limitation, we propose Learnable sequence Augmentor for triplet Contrastive Learning in sequential Recommendation (LACLRec). Specifically, the self-supervised learning-based augmenter can automatically delete noisy items from sequences and insert new items that better capture item transition patterns, generating a higher-quality augmented sequence. Subsequently, we randomly generate another augmented sequence and design a ranking-based triplet contrastive loss to differentiate the similarities between the raw sequence, the augmented sequence from augmenter, and the randomly augmented sequence, providing more fine-grained contrastive signals. Extensive experiments on three real-world datasets demonstrate that both the sequence augmenter and the triplet contrast contribute to improving recommendation accuracy. LACLRec significantly outperforms the baseline model CL4SRec, and demonstrates superior performance compared to several state-of-the-art sequential recommendation algorithms.
Investigating Inference-time Scaling for Chain of Multi-modal Thought: A Preliminary Study
Feb 17, 2025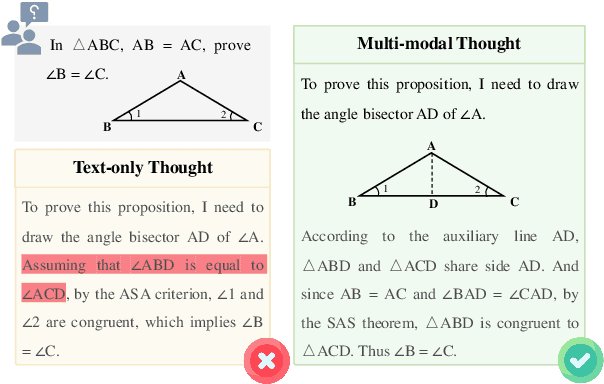
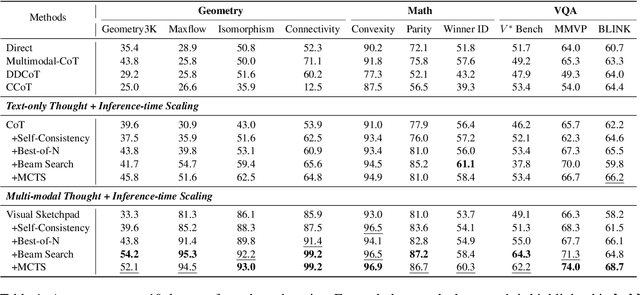
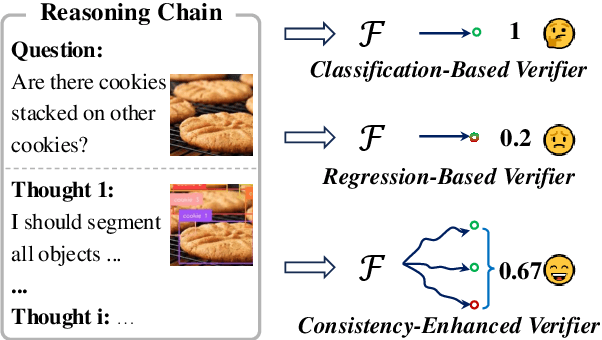
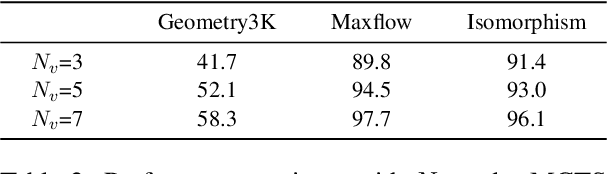
Recently, inference-time scaling of chain-of-thought (CoT) has been demonstrated as a promising approach for addressing multi-modal reasoning tasks. While existing studies have predominantly centered on text-based thinking, the integration of both visual and textual modalities within the reasoning process remains unexplored. In this study, we pioneer the exploration of inference-time scaling with multi-modal thought, aiming to bridge this gap. To provide a comprehensive analysis, we systematically investigate popular sampling-based and tree search-based inference-time scaling methods on 10 challenging tasks spanning various domains. Besides, we uniformly adopt a consistency-enhanced verifier to ensure effective guidance for both methods across different thought paradigms. Results show that multi-modal thought promotes better performance against conventional text-only thought, and blending the two types of thought fosters more diverse thinking. Despite these advantages, multi-modal thoughts necessitate higher token consumption for processing richer visual inputs, which raises concerns in practical applications. We hope that our findings on the merits and drawbacks of this research line will inspire future works in the field.
Hypergraph-Based Dynamic Graph Node Classification
Dec 29, 2024



Node classification on static graphs has achieved significant success, but achieving accurate node classification on dynamic graphs where node topology, attributes, and labels change over time has not been well addressed. Existing methods based on RNNs and self-attention only aggregate features of the same node across different time slices, which cannot adequately address and capture the diverse dynamic changes in dynamic graphs. Therefore, we propose a novel model named Hypergraph-Based Multi-granularity Dynamic Graph Node Classification (HYDG). After obtaining basic node representations for each slice through a GNN backbone, HYDG models the representations of each node in the dynamic graph through two modules. The individual-level hypergraph captures the spatio-temporal node representations between individual nodes, while the group-level hypergraph captures the multi-granularity group temporal representations among nodes of the same class. Each hyperedge captures different temporal dependencies of varying lengths by connecting multiple nodes within specific time ranges. More accurate representations are obtained through weighted information propagation and aggregation by the hypergraph neural network. Extensive experiments on five real dynamic graph datasets using two GNN backbones demonstrate the superiority of our proposed framework.
A Dual-Perspective Metaphor Detection Framework Using Large Language Models
Dec 23, 2024



Metaphor detection, a critical task in natural language processing, involves identifying whether a particular word in a sentence is used metaphorically. Traditional approaches often rely on supervised learning models that implicitly encode semantic relationships based on metaphor theories. However, these methods often suffer from a lack of transparency in their decision-making processes, which undermines the reliability of their predictions. Recent research indicates that LLMs (large language models) exhibit significant potential in metaphor detection. Nevertheless, their reasoning capabilities are constrained by predefined knowledge graphs. To overcome these limitations, we propose DMD, a novel dual-perspective framework that harnesses both implicit and explicit applications of metaphor theories to guide LLMs in metaphor detection and adopts a self-judgment mechanism to validate the responses from the aforementioned forms of guidance. In comparison to previous methods, our framework offers more transparent reasoning processes and delivers more reliable predictions. Experimental results prove the effectiveness of DMD, demonstrating state-of-the-art performance across widely-used datasets.
Synchronized and Fine-Grained Head for Skeleton-Based Ambiguous Action Recognition
Dec 19, 2024



Skeleton-based action recognition using GCNs has achieved remarkable performance, but recognizing ambiguous actions, such as "waving" and "saluting", remains a significant challenge. Existing methods typically rely on a serial combination of GCNs and TCNs, where spatial and temporal features are extracted independently, leading to an unbalanced spatial-temporal information, which hinders accurate action recognition. Moreover, existing methods for ambiguous actions often overemphasize local details, resulting in the loss of crucial global context, which further complicates the task of differentiating ambiguous actions. To address these challenges, we propose a lightweight plug-and-play module called Synchronized and Fine-grained Head (SF-Head), inserted between GCN and TCN layers. SF-Head first conducts Synchronized Spatial-Temporal Extraction (SSTE) with a Feature Redundancy Loss (F-RL), ensuring a balanced interaction between the two types of features. It then performs Adaptive Cross-dimensional Feature Aggregation (AC-FA), with a Feature Consistency Loss (F-CL), which aligns the aggregated feature with their original spatial-temporal feature. This aggregation step effectively combines both global context and local details. Experimental results on NTU RGB+D 60, NTU RGB+D 120, and NW-UCLA datasets demonstrate significant improvements in distinguishing ambiguous actions. Our code will be made available at https://github.com/HaoHuang2003/SFHead.
MLDGG: Meta-Learning for Domain Generalization on Graphs
Nov 19, 2024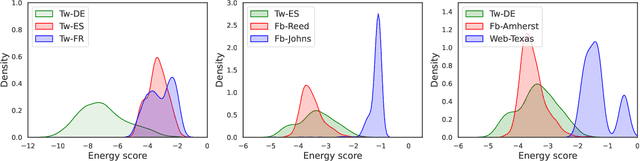

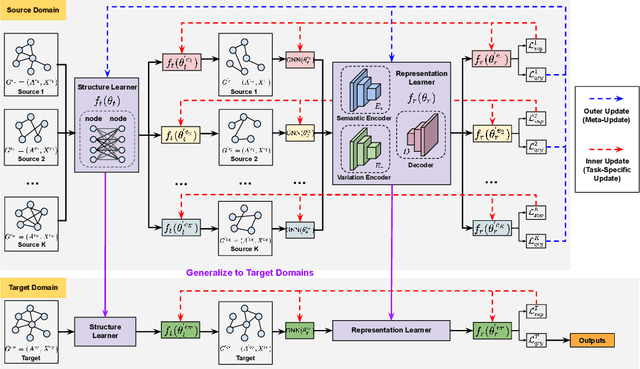
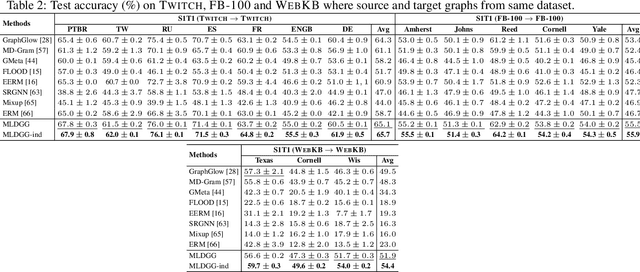
Domain generalization on graphs aims to develop models with robust generalization capabilities, ensuring effective performance on the testing set despite disparities between testing and training distributions. However, existing methods often rely on static encoders directly applied to the target domain, constraining its flexible adaptability. In contrast to conventional methodologies, which concentrate on developing specific generalized models, our framework, MLDGG, endeavors to achieve adaptable generalization across diverse domains by integrating cross-multi-domain meta-learning with structure learning and semantic identification. Initially, it introduces a generalized structure learner to mitigate the adverse effects of task-unrelated edges, enhancing the comprehensiveness of representations learned by Graph Neural Networks (GNNs) while capturing shared structural information across domains. Subsequently, a representation learner is designed to disentangle domain-invariant semantic and domain-specific variation information in node embedding by leveraging causal reasoning for semantic identification, further enhancing generalization. In the context of meta-learning, meta-parameters for both learners are optimized to facilitate knowledge transfer and enable effective adaptation to graphs through fine-tuning within the target domains, where target graphs are inaccessible during training. Our empirical results demonstrate that MLDGG surpasses baseline methods, showcasing its effectiveness in three different distribution shift settings.
Towards Cross-Modal Text-Molecule Retrieval with Better Modality Alignment
Oct 31, 2024Cross-modal text-molecule retrieval model aims to learn a shared feature space of the text and molecule modalities for accurate similarity calculation, which facilitates the rapid screening of molecules with specific properties and activities in drug design. However, previous works have two main defects. First, they are inadequate in capturing modality-shared features considering the significant gap between text sequences and molecule graphs. Second, they mainly rely on contrastive learning and adversarial training for cross-modality alignment, both of which mainly focus on the first-order similarity, ignoring the second-order similarity that can capture more structural information in the embedding space. To address these issues, we propose a novel cross-modal text-molecule retrieval model with two-fold improvements. Specifically, on the top of two modality-specific encoders, we stack a memory bank based feature projector that contain learnable memory vectors to extract modality-shared features better. More importantly, during the model training, we calculate four kinds of similarity distributions (text-to-text, text-to-molecule, molecule-to-molecule, and molecule-to-text similarity distributions) for each instance, and then minimize the distance between these similarity distributions (namely second-order similarity losses) to enhance cross-modal alignment. Experimental results and analysis strongly demonstrate the effectiveness of our model. Particularly, our model achieves SOTA performance, outperforming the previously-reported best result by 6.4%.
GDDA: Semantic OOD Detection on Graphs under Covariate Shift via Score-Based Diffusion Models
Oct 23, 2024Out-of-distribution (OOD) detection poses a significant challenge for Graph Neural Networks (GNNs), particularly in open-world scenarios with varying distribution shifts. Most existing OOD detection methods on graphs primarily focus on identifying instances in test data domains caused by either semantic shifts (changes in data classes) or covariate shifts (changes in data features), while leaving the simultaneous occurrence of both distribution shifts under-explored. In this work, we address both types of shifts simultaneously and introduce a novel challenge for OOD detection on graphs: graph-level semantic OOD detection under covariate shift. In this scenario, variations between the training and test domains result from the concurrent presence of both covariate and semantic shifts, where only graphs associated with unknown classes are identified as OOD samples (OODs). To tackle this challenge, we propose a novel two-phase framework called Graph Disentangled Diffusion Augmentation (GDDA). The first phase focuses on disentangling graph representations into domain-invariant semantic factors and domain-specific style factors. In the second phase, we introduce a novel distribution-shift-controlled score-based generative diffusion model that generates latent factors outside the training semantic and style spaces. Additionally, auxiliary pseudo-in-distribution (InD) and pseudo-OOD graph representations are employed to enhance the effectiveness of the energy-based semantic OOD detector. Extensive empirical studies on three benchmark datasets demonstrate that our approach outperforms state-of-the-art baselines.