 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-of-Distribution Detection with Positive and Negative Prompt Supervision Using Large Language Models
Nov 14, 2025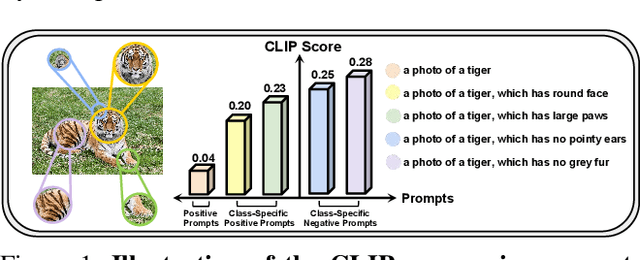
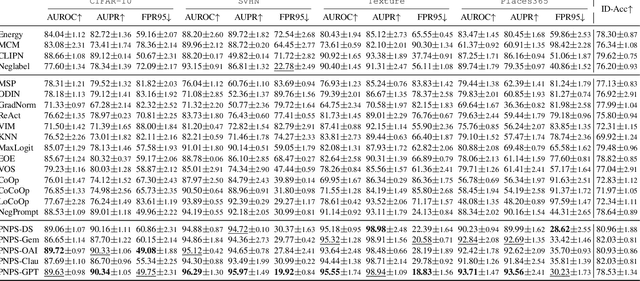
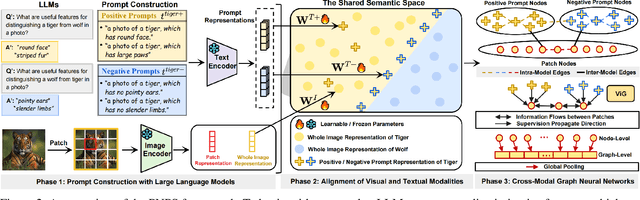
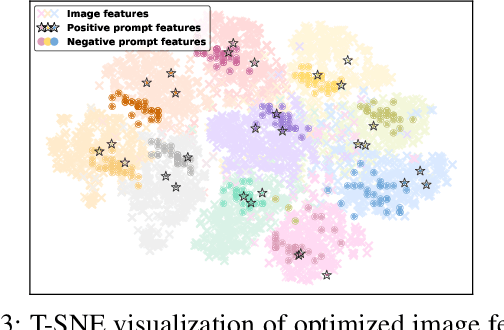
Out-of-distribution (OOD) detection is committed to delineating the classification boundaries between in-distribution (ID) and OOD images. Recent advances in vision-language models (VLMs) have demonstrated remarkable OOD detection performance by integrating both visual and textual modalities. In this context, negative prompts are introduced to emphasize the dissimilarity between image features and prompt content. However, these prompts often include a broad range of non-ID features, which may result in suboptimal outcomes due to the capture of overlapping or misleading information. To address this issue, we propose Positive and Negative Prompt Supervision, which encourages negative prompts to capture inter-class features and transfers this semantic knowledge to the visual modality to enhance OOD detection performance. Our method begins with class-specific positive and negative prompts initialized by large language models (LLMs). These prompts are subsequently optimized, with positive prompts focusing on features within each class, while negative prompts highlight features around category boundaries. Additionally, a graph-based architecture is employed to aggregate semantic-aware supervision from the optimized prompt representations and propagate it to the visual branch, thereby enhancing the performance of the energy-based OOD detector. Extensive experiments on two benchmarks, CIFAR-100 and ImageNet-1K, across eight OOD datasets and five different LLMs, demonstrate that our method outperforms state-of-the-art baselines.
MLDGG: Meta-Learning for Domain Generalization on Graphs
Nov 19, 2024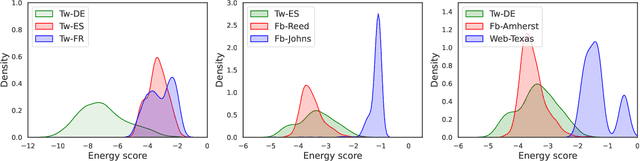

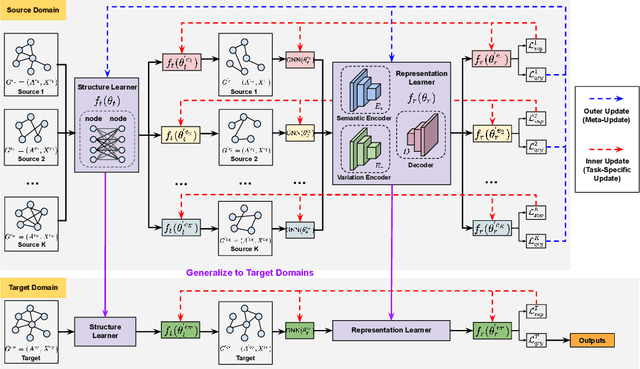
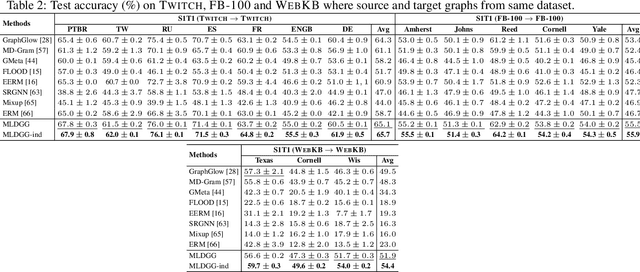
Domain generalization on graphs aims to develop models with robust generalization capabilities, ensuring effective performance on the testing set despite disparities between testing and training distributions. However, existing methods often rely on static encoders directly applied to the target domain, constraining its flexible adaptability. In contrast to conventional methodologies, which concentrate on developing specific generalized models, our framework, MLDGG, endeavors to achieve adaptable generalization across diverse domains by integrating cross-multi-domain meta-learning with structure learning and semantic identification. Initially, it introduces a generalized structure learner to mitigate the adverse effects of task-unrelated edges, enhancing the comprehensiveness of representations learned by Graph Neural Networks (GNNs) while capturing shared structural information across domains. Subsequently, a representation learner is designed to disentangle domain-invariant semantic and domain-specific variation information in node embedding by leveraging causal reasoning for semantic identification, further enhancing generalization. In the context of meta-learning, meta-parameters for both learners are optimized to facilitate knowledge transfer and enable effective adaptation to graphs through fine-tuning within the target domains, where target graphs are inaccessible during training. Our empirical results demonstrate that MLDGG surpasses baseline methods, showcasing its effectiveness in three different distribution shift settings.
GDDA: Semantic OOD Detection on Graphs under Covariate Shift via Score-Based Diffusion Models
Oct 23, 2024Out-of-distribution (OOD) detection poses a significant challenge for Graph Neural Networks (GNNs), particularly in open-world scenarios with varying distribution shifts. Most existing OOD detection methods on graphs primarily focus on identifying instances in test data domains caused by either semantic shifts (changes in data classes) or covariate shifts (changes in data features), while leaving the simultaneous occurrence of both distribution shifts under-explored. In this work, we address both types of shifts simultaneously and introduce a novel challenge for OOD detection on graphs: graph-level semantic OOD detection under covariate shift. In this scenario, variations between the training and test domains result from the concurrent presence of both covariate and semantic shifts, where only graphs associated with unknown classes are identified as OOD samples (OODs). To tackle this challenge, we propose a novel two-phase framework called Graph Disentangled Diffusion Augmentation (GDDA). The first phase focuses on disentangling graph representations into domain-invariant semantic factors and domain-specific style factors. In the second phase, we introduce a novel distribution-shift-controlled score-based generative diffusion model that generates latent factors outside the training semantic and style spaces. Additionally, auxiliary pseudo-in-distribution (InD) and pseudo-OOD graph representations are employed to enhance the effectiveness of the energy-based semantic OOD detector. Extensive empirical studies on three benchmark datasets demonstrate that our approach outperforms state-of-the-art baselines.
Graphs Generalization under Distribution Shifts
Mar 25, 2024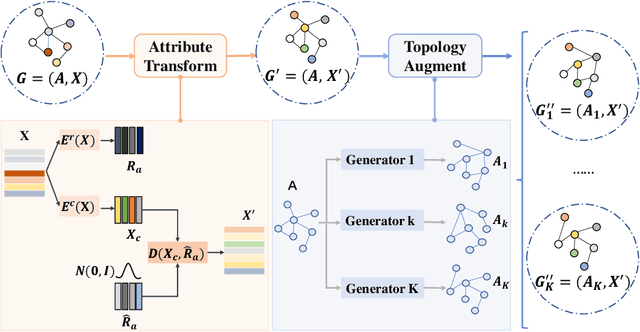
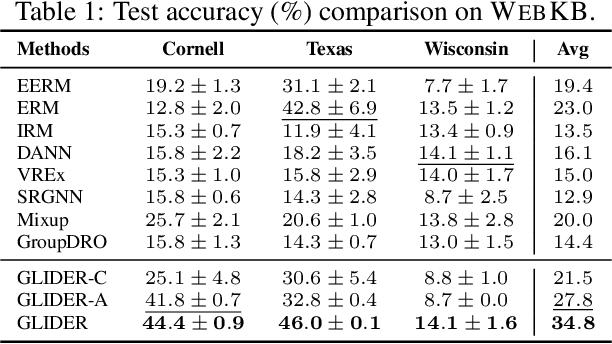
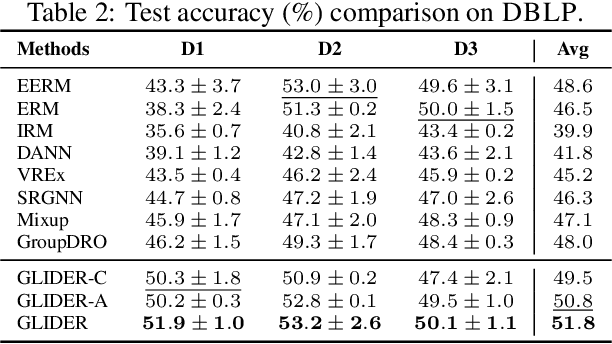
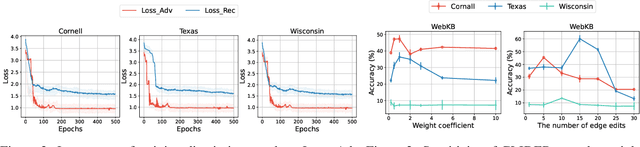
Traditional machine learning methods heavily rely on the independent and identically distribution assumption, which imposes limitations when the test distribution deviates from the training distribution. To address this crucial issue, out-of-distribution (OOD) generalization, which aims to achieve satisfactory generalization performance when faced with unknown distribution shifts, has made a significant process. However, the OOD method for graph-structured data currently lacks clarity and remains relatively unexplored due to two primary challenges. Firstly, distribution shifts on graphs often occur simultaneously on node attributes and graph topology. Secondly, capturing invariant information amidst diverse distribution shifts proves to be a formidable challenge. To overcome these obstacles, in this paper, we introduce a novel framework, namely Graph Learning Invariant Domain genERation (GLIDER). The goal is to (1) diversify variations across domains by modeling the potential seen or unseen variations of attribute distribution and topological structure and (2) minimize the discrepancy of the variation in a representation space where the target is to predict semantic labels. Extensive experiment results indicate that our model outperforms baseline methods on node-level OOD generalization across domains in distribution shift on node features and topological structures simultaneously.
Supervised Algorithmic Fairness in Distribution Shifts: A Survey
Feb 05, 2024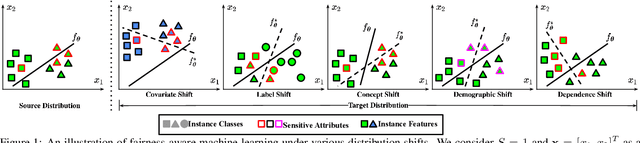

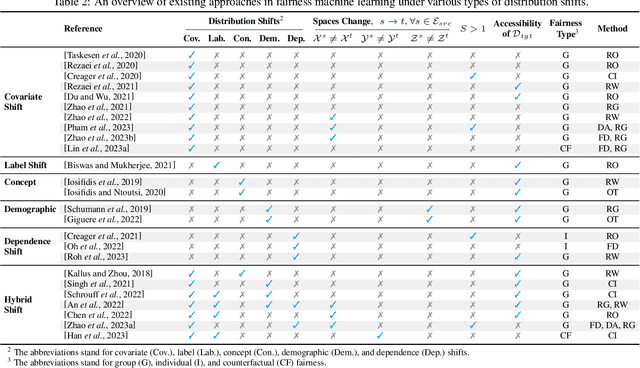
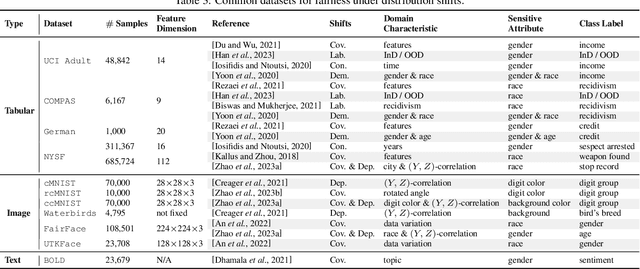
Supervised fairness-aware machine learning under distribution shifts is an emerging field that addresses the challenge of maintaining equitable and unbiased predictions when faced with changes in data distributions from source to target domains. In real-world applications, machine learning models are often trained on a specific dataset but deployed in environments where the data distribution may shift over time due to various factors. This shift can lead to unfair predictions, disproportionately affecting certain groups characterized by sensitive attributes, such as race and gender. In this survey, we provide a summary of various types of distribution shifts and comprehensively investigate existing methods based on these shifts, highlighting six commonly used approaches in the literature. Additionally, this survey lists publicly available datasets and evaluation metrics for empirical studies. We further explore the interconnection with related research fields, discuss the significant challenges, and identify potential directions for future studies.