 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePath planning for unmanned surface vehicle based on predictive artificial potential field. International Journal of Advanced Robotic Systems
Feb 22, 2026Path planning for high-speed unmanned surface vehicles requires more complex solutions to reduce sailing time and save energy. This article proposes a new predictive artificial potential field that incorporates time information and predictive potential to plan smoother paths. It explores the principles of the artificial potential field, considering vehicle dynamics and local minimum reachability. The study first analyzes the most advanced traditional artificial potential field and its drawbacks in global and local path planning. It then introduces three modifications to the predictive artificial potential field-angle limit, velocity adjustment, and predictive potential to enhance the feasibility and flatness of the generated path. A comparison between the traditional and predictive artificial potential fields demonstrates that the latter successfully restricts the maximum turning angle, shortens sailing time, and intelligently avoids obstacles. Simulation results further verify that the predictive artificial potential field addresses the concave local minimum problem and improves reachability in special scenarios, ultimately generating a more efficient path that reduces sailing time and conserves energy for unmanned surface vehicles.
GenCAMO: Scene-Graph Contextual Decoupling for Environment-aware and Mask-free Camouflage Image-Dense Annotation Generation
Jan 03, 2026Conceal dense prediction (CDP), especially RGB-D camouflage object detection and open-vocabulary camouflage object segmentation, plays a crucial role in advancing the understanding and reasoning of complex camouflage scenes. However, high-quality and large-scale camouflage datasets with dense annotation remain scarce due to expensive data collection and labeling costs. To address this challenge, we explore leveraging generative models to synthesize realistic camouflage image-dense data for training CDP models with fine-grained representations, prior knowledge, and auxiliary reasoning. Concretely, our contributions are threefold: (i) we introduce GenCAMO-DB, a large-scale camouflage dataset with multi-modal annotations, including depth maps, scene graphs, attribute descriptions, and text prompts; (ii) we present GenCAMO, an environment-aware and mask-free generative framework that produces high-fidelity camouflage image-dense annotations; (iii) extensive experiments across multiple modalities demonstrate that GenCAMO significantly improves dense prediction performance on complex camouflage scenes by providing high-quality synthetic data. The code and datasets will be released after paper acceptance.
Towards Cross-Modal Text-Molecule Retrieval with Better Modality Alignment
Oct 31, 2024Cross-modal text-molecule retrieval model aims to learn a shared feature space of the text and molecule modalities for accurate similarity calculation, which facilitates the rapid screening of molecules with specific properties and activities in drug design. However, previous works have two main defects. First, they are inadequate in capturing modality-shared features considering the significant gap between text sequences and molecule graphs. Second, they mainly rely on contrastive learning and adversarial training for cross-modality alignment, both of which mainly focus on the first-order similarity, ignoring the second-order similarity that can capture more structural information in the embedding space. To address these issues, we propose a novel cross-modal text-molecule retrieval model with two-fold improvements. Specifically, on the top of two modality-specific encoders, we stack a memory bank based feature projector that contain learnable memory vectors to extract modality-shared features better. More importantly, during the model training, we calculate four kinds of similarity distributions (text-to-text, text-to-molecule, molecule-to-molecule, and molecule-to-text similarity distributions) for each instance, and then minimize the distance between these similarity distributions (namely second-order similarity losses) to enhance cross-modal alignment. Experimental results and analysis strongly demonstrate the effectiveness of our model. Particularly, our model achieves SOTA performance, outperforming the previously-reported best result by 6.4%.
RGDA-DDI: Residual graph attention network and dual-attention based framework for drug-drug interaction prediction
Aug 27, 2024Recent studies suggest that drug-drug interaction (DDI) prediction via computational approaches has significant importance for understanding the functions and co-prescriptions of multiple drugs. However, the existing silico DDI prediction methods either ignore the potential interactions among drug-drug pairs (DDPs), or fail to explicitly model and fuse the multi-scale drug feature representations for better prediction. In this study, we propose RGDA-DDI, a residual graph attention network (residual-GAT) and dual-attention based framework for drug-drug interaction prediction. A residual-GAT module is introduced to simultaneously learn multi-scale feature representations from drugs and DDPs. In addition, a dual-attention based feature fusion block is constructed to learn local joint interaction representations. A series of evaluation metrics demonstrate that the RGDA-DDI significantly improved DDI prediction performance on two public benchmark datasets, which provides a new insight into drug development.
Multi-level protein pre-training with Vabs-Net
Feb 05, 2024In recent years, there has been a surge in the development of 3D structure-based pre-trained protein models, representing a significant advancement over pre-trained protein language models in various downstream tasks. However, most existing structure-based pre-trained models primarily focus on the residue level, i.e., alpha carbon atoms, while ignoring other atoms like side chain atoms. We argue that modeling proteins at both residue and atom levels is important since the side chain atoms can also be crucial for numerous downstream tasks, for example, molecular docking. Nevertheless, we find that naively combining residue and atom information during pre-training typically fails. We identify a key reason is the information leakage caused by the inclusion of atom structure in the input, which renders residue-level pre-training tasks trivial and results in insufficiently expressive residue representations. To address this issue, we introduce a span mask pre-training strategy on 3D protein chains to learn meaningful representations of both residues and atoms. This leads to a simple yet effective approach to learning protein representation suitable for diverse downstream tasks. Extensive experimental results on binding site prediction and function prediction tasks demonstrate our proposed pre-training approach significantly outperforms other methods. Our code will be made public.
From Statistical Methods to Deep Learning, Automatic Keyphrase Prediction: A Survey
May 04, 2023



Keyphrase prediction aims to generate phrases (keyphrases) that highly summarizes a given document. Recently, researchers have conducted in-depth studies on this task from various perspectives. In this paper, we comprehensively summarize representative studies from the perspectives of dominant models, datasets and evaluation metrics. Our work analyzes up to 167 previous works, achieving greater coverage of this task than previous surveys. Particularly, we focus highly on deep learning-based keyphrase prediction, which attracts increasing attention of this task in recent years. Afterwards, we conduct several groups of experiments to carefully compare representative models. To the best of our knowledge, our work is the first attempt to compare these models using the identical commonly-used datasets and evaluation metric, facilitating in-depth analyses of their disadvantages and advantages. Finally, we discuss the possible research directions of this task in the future.
Deep Keyphrase Completion
Oct 29, 2021
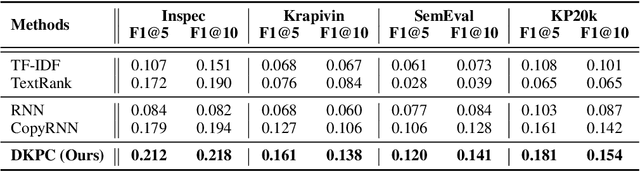
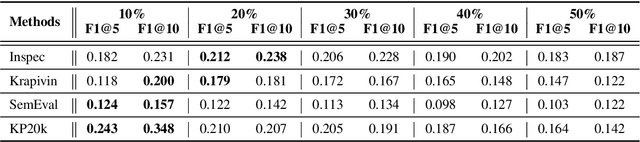

Keyphrase provides accurate information of document content that is highly compact, concise, full of meanings, and widely used for discourse comprehension, organization, and text retrieval. Though previous studies have made substantial efforts for automated keyphrase extraction and generation, surprisingly, few studies have been made for \textit{keyphrase completion} (KPC). KPC aims to generate more keyphrases for document (e.g. scientific publication) taking advantage of document content along with a very limited number of known keyphrases, which can be applied to improve text indexing system, etc. In this paper, we propose a novel KPC method with an encoder-decoder framework. We name it \textit{deep keyphrase completion} (DKPC) since it attempts to capture the deep semantic meaning of the document content together with known keyphrases via a deep learning framework. Specifically, the encoder and the decoder in DKPC play different roles to make full use of the known keyphrases. The former considers the keyphrase-guiding factors, which aggregates information of known keyphrases into context. On the contrary, the latter considers the keyphrase-inhibited factor to inhibit semantically repeated keyphrase generation. Extensive experiments on benchmark datasets demonstrate the efficacy of our proposed model.
A Novel Video Salient Object Detection Method via Semi-supervised Motion Quality Perception
Aug 07, 2020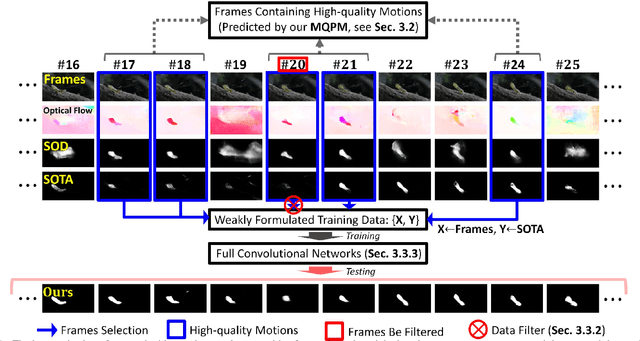

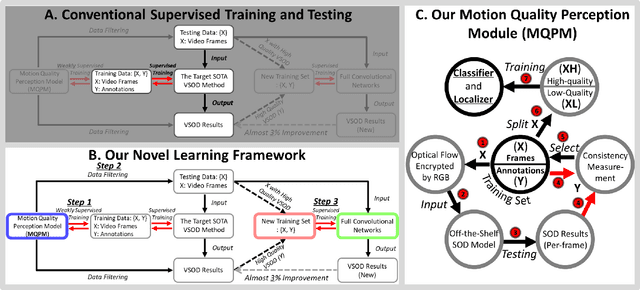
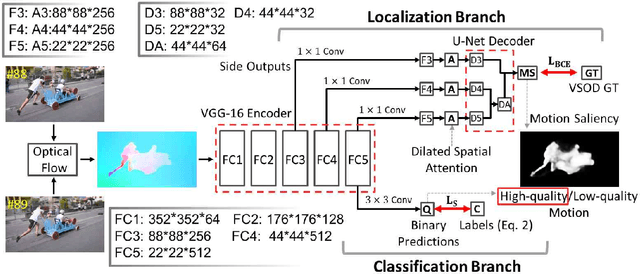
Previous video salient object detection (VSOD) approaches have mainly focused on designing fancy networks to achieve their performance improvements. However, with the slow-down in development of deep learning techniques recently, it may become more and more difficult to anticipate another breakthrough via fancy networks solely. To this end, this paper proposes a universal learning scheme to get a further 3\% performance improvement for all state-of-the-art (SOTA) methods. The major highlight of our method is that we resort the "motion quality"---a brand new concept, to select a sub-group of video frames from the original testing set to construct a new training set. The selected frames in this new training set should all contain high-quality motions, in which the salient objects will have large probability to be successfully detected by the "target SOTA method"---the one we want to improve. Consequently, we can achieve a significant performance improvement by using this new training set to start a new round of network training. During this new round training, the VSOD results of the target SOTA method will be applied as the pseudo training objectives. Our novel learning scheme is simple yet effective, and its semi-supervised methodology may have large potential to inspire the VSOD community in the future.
ImageBERT: Cross-modal Pre-training with Large-scale Weak-supervised Image-Text Data
Jan 23, 2020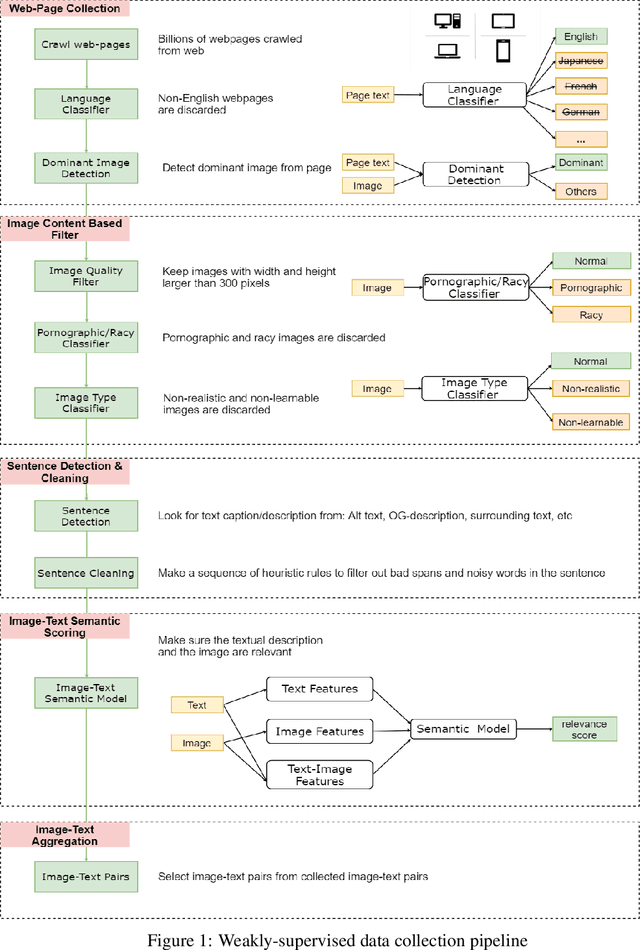
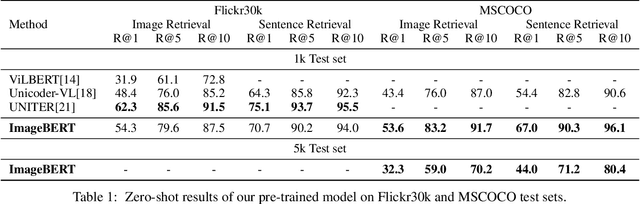

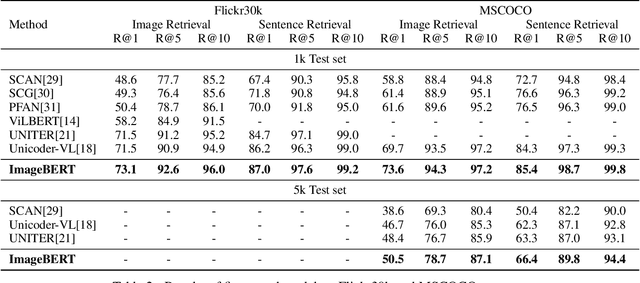
In this paper, we introduce a new vision-language pre-trained model -- ImageBERT -- for image-text joint embedding. Our model is a Transformer-based model, which takes different modalities as input and models the relationship between them. The model is pre-trained on four tasks simultaneously: Masked Language Modeling (MLM), Masked Object Classification (MOC), Masked Region Feature Regression (MRFR), and Image Text Matching (ITM). To further enhance the pre-training quality, we have collected a Large-scale weAk-supervised Image-Text (LAIT) dataset from Web. We first pre-train the model on this dataset, then conduct a second stage pre-training on Conceptual Captions and SBU Captions. Our experiments show that multi-stage pre-training strategy outperforms single-stage pre-training. We also fine-tune and evaluate our pre-trained ImageBERT model on image retrieval and text retrieval tasks, and achieve new state-of-the-art results on both MSCOCO and Flickr30k datasets.