 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Video Salient Object Detection Method via Semi-supervised Motion Quality Perception
Paper and Code
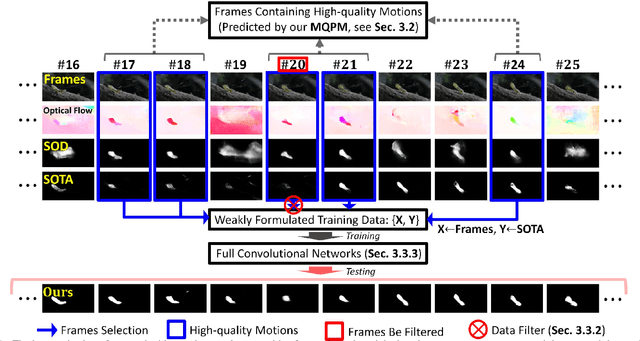

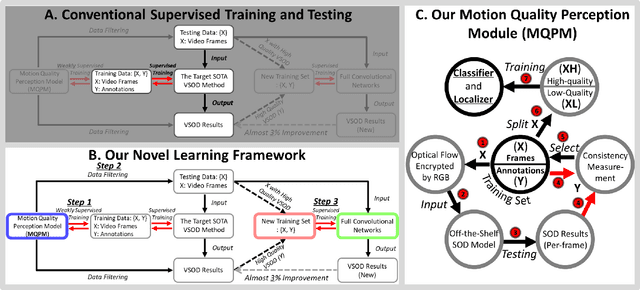
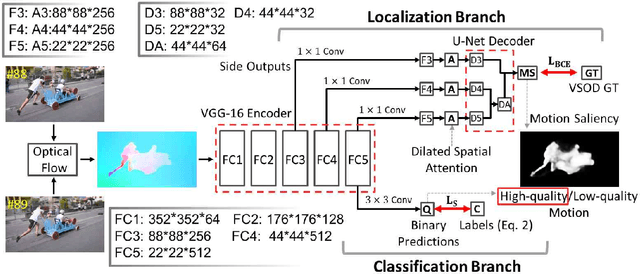
Previous video salient object detection (VSOD) approaches have mainly focused on designing fancy networks to achieve their performance improvements. However, with the slow-down in development of deep learning techniques recently, it may become more and more difficult to anticipate another breakthrough via fancy networks solely. To this end, this paper proposes a universal learning scheme to get a further 3\% performance improvement for all state-of-the-art (SOTA) methods. The major highlight of our method is that we resort the "motion quality"---a brand new concept, to select a sub-group of video frames from the original testing set to construct a new training set. The selected frames in this new training set should all contain high-quality motions, in which the salient objects will have large probability to be successfully detected by the "target SOTA method"---the one we want to improve. Consequently, we can achieve a significant performance improvement by using this new training set to start a new round of network training. During this new round training, the VSOD results of the target SOTA method will be applied as the pseudo training objectives. Our novel learning scheme is simple yet effective, and its semi-supervised methodology may have large potential to inspire the VSOD community in the future.