 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Like a Pilot: Fine-Grained Long-Horizon UAV Navigation
Jun 05, 2026Language-guided UAV agents must execute long-horizon semantic instructions while producing smooth, physically feasible continuous flight commands, yet existing Vision-Language Navigation (VLN) benchmarks typically use discrete or coarse actions and existing UAV Vision-Language-Action (VLA) tasks focus on short, atomic maneuvers. To address this gap in UAV task settings, we introduce \textbf{FLIGHT}, a \textbf{F}ine-grained \textbf{L}ong-horizon \textbf{I}nstruction-\textbf{G}uided benchmark for \textbf{H}ybrid UAV navigation and reasoning \textbf{T}asks, which combines multi-stage instructions with dense 6-DoF trajectory annotations across two dataset splits: Fine-grained VLN and Long-horizon Flow. To endow the UAV agent with the capability of real-time in-flight reasoning over task execution status and mission planning, while simultaneously accommodating high-frequency, real-time precise control, we further propose \textbf{FLIGHT VLA}, an asynchronous architecture that decouples a low-frequency Streaming Pilot Vision-Language Model (VLM) for task-state reasoning from a high-frequency diffusion action model for continuous control, supervised by explicit \textbf{Pilot Reasoning} texts that summarize the current flight state and anticipate the next subgoal. In closed-loop evaluation, FLIGHT VLA consistently surpasses representative VLN and VLA baselines on our FLIGHT benchmarks, achieving stronger multi-stage completion, subgoal adherence, and terminal control. Its trained Streaming Pilot Reasoning VLM further improves UAV video reasoning, validating the effectiveness of our design.
LIBERO-X: Robustness Litmus for Vision-Language-Action Models
Feb 06, 2026Reliable benchmarking is critical for advancing Vision-Language-Action (VLA) models, as it reveals their generalization, robustness, and alignment of perception with language-driven manipulation tasks. However, existing benchmarks often provide limited or misleading assessments due to insufficient evaluation protocols that inadequately capture real-world distribution shifts. This work systematically rethinks VLA benchmarking from both evaluation and data perspectives, introducing LIBERO-X, a benchmark featuring: 1) A hierarchical evaluation protocol with progressive difficulty levels targeting three core capabilities: spatial generalization, object recognition, and task instruction understanding. This design enables fine-grained analysis of performance degradation under increasing environmental and task complexity; 2) A high-diversity training dataset collected via human teleoperation, where each scene supports multiple fine-grained manipulation objectives to bridge the train-evaluation distribution gap. Experiments with representative VLA models reveal significant performance drops under cumulative perturbations, exposing persistent limitations in scene comprehension and instruction grounding. By integrating hierarchical evaluation with diverse training data, LIBERO-X offers a more reliable foundation for assessing and advancing VLA development.
ONER: Online Experience Replay for Incremental Anomaly Detection
Dec 05, 2024Incremental anomaly detection sequentially recognizes abnormal regions in novel categories for dynamic industrial scenarios. This remains highly challenging due to knowledge overwriting and feature conflicts, leading to catastrophic forgetting. In this work, we propose ONER, an end-to-end ONline Experience Replay method, which efficiently mitigates catastrophic forgetting while adapting to new tasks with minimal cost. Specifically, our framework utilizes two types of experiences from past tasks: decomposed prompts and semantic prototypes, addressing both model parameter updates and feature optimization. The decomposed prompts consist of learnable components that assemble to produce attention-conditioned prompts. These prompts reuse previously learned knowledge, enabling model to learn novel tasks effectively. The semantic prototypes operate at both pixel and image levels, performing regularization in the latent feature space to prevent forgetting across various tasks. Extensive experiments demonstrate that our method achieves state-of-the-art performance in incremental anomaly detection with significantly reduced forgetting, as well as efficiently adapting to new categories with minimal costs. These results confirm the efficiency and stability of ONER, making it a powerful solution for real-world applications.
Unilaterally Aggregated Contrastive Learning with Hierarchical Augmentation for Anomaly Detection
Aug 20, 2023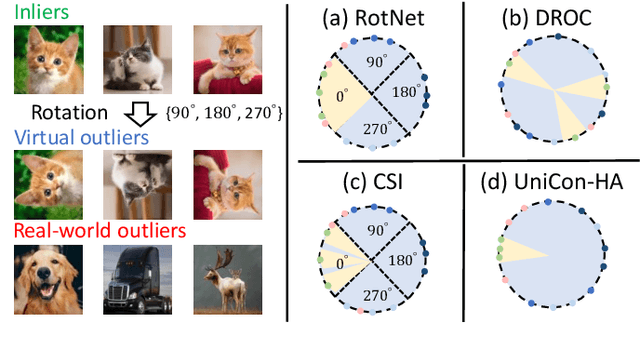



Anomaly detection (AD), aiming to find samples that deviate from the training distribution, is essential in safety-critical applications. Though recent self-supervised learning based attempts achieve promising results by creating virtual outliers, their training objectives are less faithful to AD which requires a concentrated inlier distribution as well as a dispersive outlier distribution. In this paper, we propose Unilaterally Aggregated Contrastive Learning with Hierarchical Augmentation (UniCon-HA), taking into account both the requirements above. Specifically, we explicitly encourage the concentration of inliers and the dispersion of virtual outliers via supervised and unsupervised contrastive losses, respectively. Considering that standard contrastive data augmentation for generating positive views may induce outliers, we additionally introduce a soft mechanism to re-weight each augmented inlier according to its deviation from the inlier distribution, to ensure a purified concentration. Moreover, to prompt a higher concentration, inspired by curriculum learning, we adopt an easy-to-hard hierarchical augmentation strategy and perform contrastive aggregation at different depths of the network based on the strengths of data augmentation. Our method is evaluated under three AD settings including unlabeled one-class, unlabeled multi-class, and labeled multi-class, demonstrating its consistent superiority over other competitors.
Align-DETR: Improving DETR with Simple IoU-aware BCE loss
Apr 15, 2023



DETR has set up a simple end-to-end pipeline for object detection by formulating this task as a set prediction problem, showing promising potential. However, despite the significant progress in improving DETR, this paper identifies a problem of misalignment in the output distribution, which prevents the best-regressed samples from being assigned with high confidence, hindering the model's accuracy. We propose a metric, recall of best-regressed samples, to quantitively evaluate the misalignment problem. Observing its importance, we propose a novel Align-DETR that incorporates a localization precision-aware classification loss in optimization. The proposed loss, IA-BCE, guides the training of DETR to build a strong correlation between classification score and localization precision. We also adopt the mixed-matching strategy, to facilitate DETR-based detectors with faster training convergence while keeping an end-to-end scheme. Moreover, to overcome the dramatic decrease in sample quality induced by the sparsity of queries, we introduce a prime sample weighting mechanism to suppress the interference of unimportant samples. Extensive experiments are conducted with very competitive results reported. In particular, it delivers a 46 (+3.8)% AP on the DAB-DETR baseline with the ResNet-50 backbone and reaches a new SOTA performance of 50.2% AP in the 1x setting on the COCO validation set when employing the strong baseline DINO. Our code is available at https://github.com/FelixCaae/AlignDETR.
Video Anomaly Detection by Solving Decoupled Spatio-Temporal Jigsaw Puzzles
Jul 22, 2022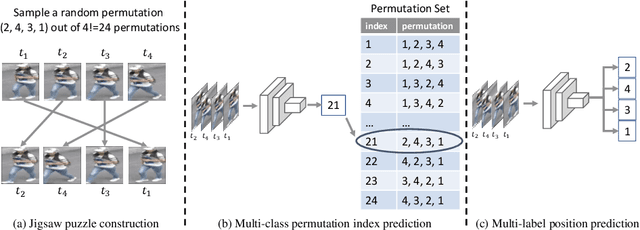
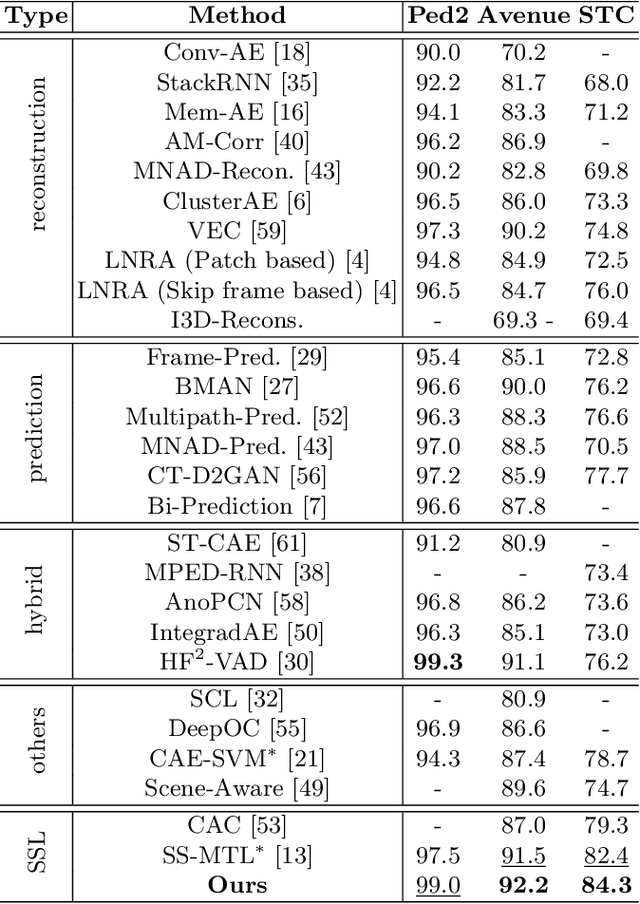
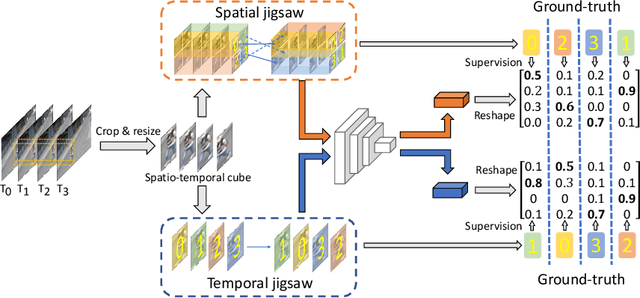
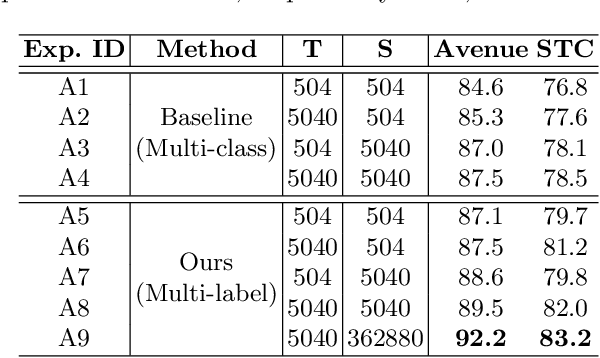
Video Anomaly Detection (VAD) is an important topic in computer vision. Motivated by the recent advances in self-supervised learning, this paper addresses VAD by solving an intuitive yet challenging pretext task, i.e., spatio-temporal jigsaw puzzles, which is cast as a multi-label fine-grained classification problem. Our method exhibits several advantages over existing works: 1) the spatio-temporal jigsaw puzzles are decoupled in terms of spatial and temporal dimensions, responsible for capturing highly discriminative appearance and motion features, respectively; 2) full permutations are used to provide abundant jigsaw puzzles covering various difficulty levels, allowing the network to distinguish subtle spatio-temporal differences between normal and abnormal events; and 3) the pretext task is tackled in an end-to-end manner without relying on any pre-trained models. Our method outperforms state-of-the-art counterparts on three public benchmarks. Especially on ShanghaiTech Campus, the result is superior to reconstruction and prediction-based methods by a large margin.
Indirect-Instant Attention Optimization for Crowd Counting in Dense Scenes
Jun 12, 2022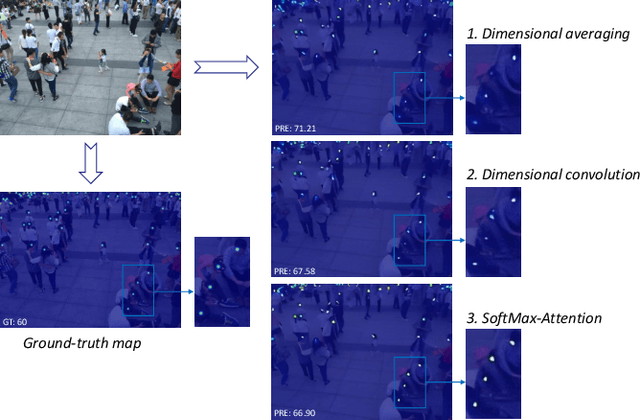

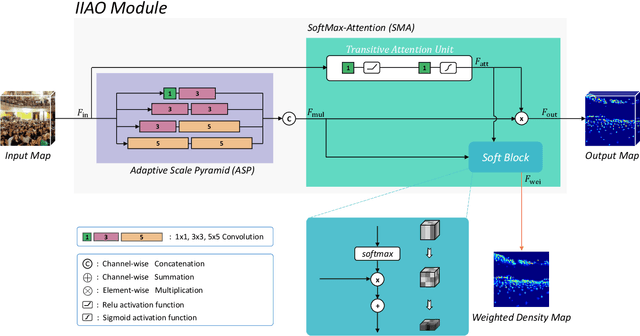

One of appealing approaches to guiding learnable parameter optimization, such as feature maps, is global attention, which enlightens network intelligence at a fraction of the cost. However, its loss calculation process still falls short: 1)We can only produce one-dimensional 'pseudo labels' for attention, since the artificial threshold involved in the procedure is not robust; 2) The attention awaiting loss calculation is necessarily high-dimensional, and decreasing it by convolution will inevitably introduce additional learnable parameters, thus confusing the source of the loss. To this end, we devise a simple but efficient Indirect-Instant Attention Optimization (IIAO) module based on SoftMax-Attention , which transforms high-dimensional attention map into a one-dimensional feature map in the mathematical sense for loss calculation midway through the network, while automatically providing adaptive multi-scale fusion to feature pyramid module. The special transformation yields relatively coarse features and, originally, the predictive fallibility of regions varies by crowd density distribution, so we tailor the Regional Correlation Loss (RCLoss) to retrieve continuous error-prone regions and smooth spatial information . Extensive experiments have proven that our approach surpasses previous SOTA methods in many benchmark datasets.
Learning Oriented Remote Sensing Object Detection via Naive Geometric Computing
Dec 01, 2021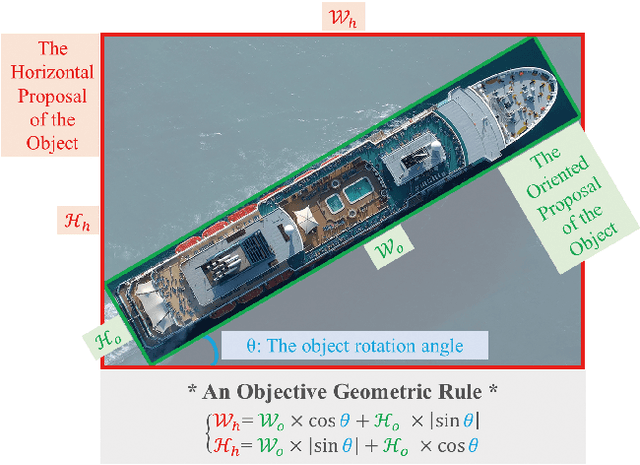
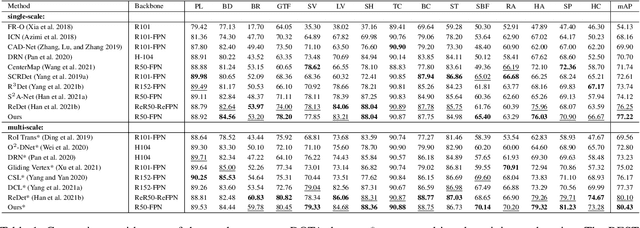
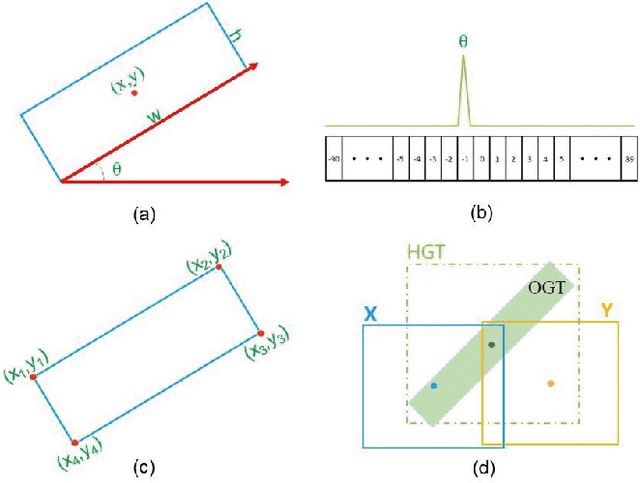
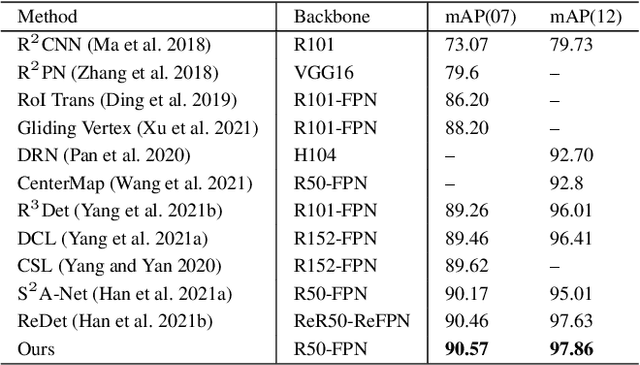
Detecting oriented objects along with estimating their rotation information is one crucial step for analyzing remote sensing images. Despite that many methods proposed recently have achieved remarkable performance, most of them directly learn to predict object directions under the supervision of only one (e.g. the rotation angle) or a few (e.g. several coordinates) groundtruth values individually. Oriented object detection would be more accurate and robust if extra constraints, with respect to proposal and rotation information regression, are adopted for joint supervision during training. To this end, we innovatively propose a mechanism that simultaneously learns the regression of horizontal proposals, oriented proposals, and rotation angles of objects in a consistent manner, via naive geometric computing, as one additional steady constraint (see Figure 1). An oriented center prior guided label assignment strategy is proposed for further enhancing the quality of proposals, yielding better performance. Extensive experiments demonstrate the model equipped with our idea significantly outperforms the baseline by a large margin to achieve a new state-of-the-art result without any extra computational burden during inference. Our proposed idea is simple and intuitive that can be readily implemented. Source codes and trained models are involved in supplementary files.
Student-Teacher Feature Pyramid Matching for Unsupervised Anomaly Detection
Mar 15, 2021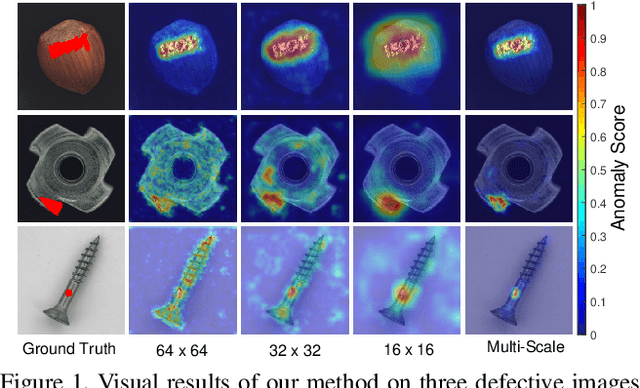

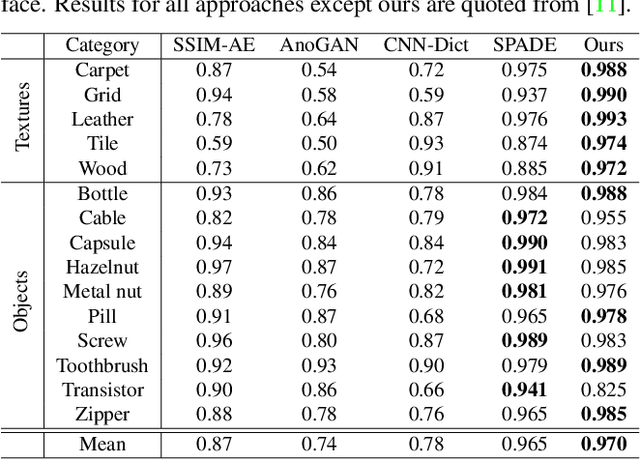
Anomaly detection is a challenging task and usually formulated as an unsupervised learning problem for the unexpectedness of anomalies. This paper proposes a simple yet powerful approach to this issue, which is implemented in the student-teacher framework for its advantages but substantially extends it in terms of both accuracy and efficiency. Given a strong model pre-trained on image classification as the teacher, we distill the knowledge into a single student network with the identical architecture to learn the distribution of anomaly-free images and this one-step transfer preserves the crucial clues as much as possible. Moreover, we integrate the multi-scale feature matching strategy into the framework, and this hierarchical feature alignment enables the student network to receive a mixture of multi-level knowledge from the feature pyramid under better supervision, thus allowing to detect anomalies of various sizes. The difference between feature pyramids generated by the two networks serves as a scoring function indicating the probability of anomaly occurring. Due to such operations, our approach achieves accurate and fast pixel-level anomaly detection. Very competitive results are delivered on three major benchmarks, significantly superior to the state of the art ones. In addition, it makes inferences at a very high speed (with 100 FPS for images of the size at 256x256), at least dozens of times faster than the latest counterparts.
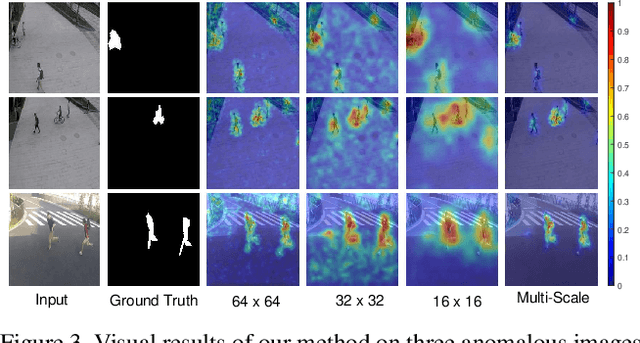
A Novel Video Salient Object Detection Method via Semi-supervised Motion Quality Perception
Aug 07, 2020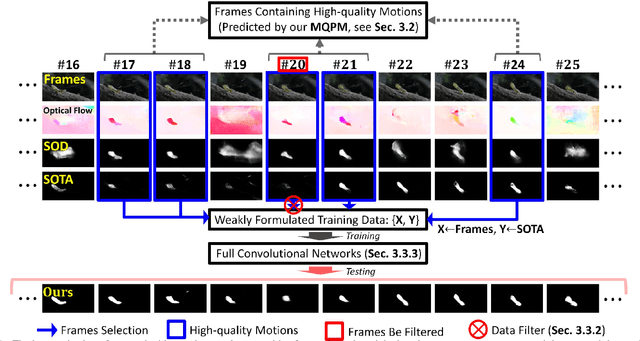

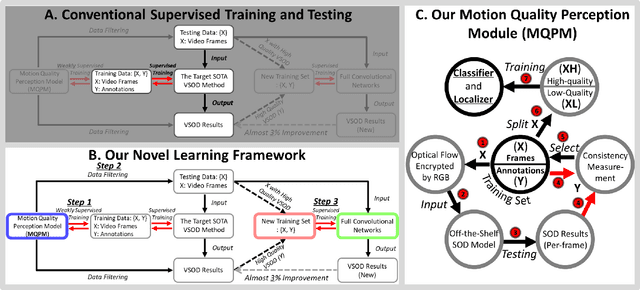
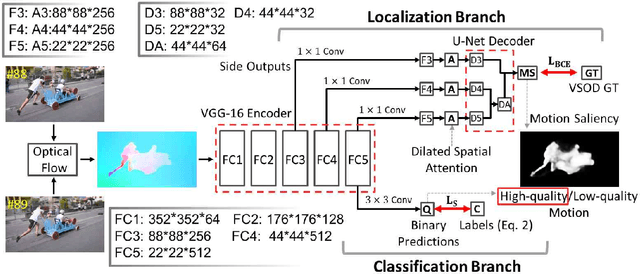
Previous video salient object detection (VSOD) approaches have mainly focused on designing fancy networks to achieve their performance improvements. However, with the slow-down in development of deep learning techniques recently, it may become more and more difficult to anticipate another breakthrough via fancy networks solely. To this end, this paper proposes a universal learning scheme to get a further 3\% performance improvement for all state-of-the-art (SOTA) methods. The major highlight of our method is that we resort the "motion quality"---a brand new concept, to select a sub-group of video frames from the original testing set to construct a new training set. The selected frames in this new training set should all contain high-quality motions, in which the salient objects will have large probability to be successfully detected by the "target SOTA method"---the one we want to improve. Consequently, we can achieve a significant performance improvement by using this new training set to start a new round of network training. During this new round training, the VSOD results of the target SOTA method will be applied as the pseudo training objectives. Our novel learning scheme is simple yet effective, and its semi-supervised methodology may have large potential to inspire the VSOD community in the future.