 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-Evolving Skill Generation and Policy Optimization
Jun 07, 2026Skill-augmented reinforcement learning improves language agents by storing reusable procedural knowledge acquired from past experience. Existing methods typically use strong language models to analyze trajectories, generate skills, and update a retrievable skill bank during online training. However, they rarely assess whether a newly generated skill is useful before it is stored and reused. We find that this assumption is unreliable: even skills generated by proprietary frontier LLMs exhibit highly mixed utility, with many providing little benefit or even degrading performance. Once such skills enter the bank, their effects are difficult to identify, because subsequent rollout feedback is delayed and usually reflects the combined effect of multiple retrieved skills rather than the marginal contribution of any individual skill. We propose an online reinforcement learning framework for pre-storage skill validation. The framework estimates whether a candidate skill contributes useful information beyond the skills already retrieved for the current task. It uses the standard rollout budget to form two matched groups under the same task and retrieval context: base rollouts conditioned on the currently retrieved skills, and skill-augmented rollouts conditioned on the same skills plus one candidate skill induced from the base trajectories. The reward gap between these two groups estimates the candidate skill's context-dependent marginal utility, enabling the framework to promote useful skills while filtering ineffective or harmful ones without additional rollout overhead. The framework further uses this marginal-utility signal to train the policy itself as a skill generator, reducing reliance on repeated calls to proprietary models. The learned skill-generation likelihood serves as a context-dependent score for retrieval-time reranking and outdated-skill pruning as the policy evolves.
HYDRA: Unifying Multi-modal Generation and Understanding via Representation-Harmonized Tokenization
Mar 17, 2026Unified Multimodal Models struggle to bridge the fundamental gap between the abstract representations needed for visual understanding and the detailed primitives required for generation. Existing approaches typically compromise by employing decoupled encoders, stacking representation encoder atop VAEs, or utilizing discrete quantization. However, these methods often disrupt information coherence and lead to optimization conflicts. To this end, we introduce HYDRA-TOK, a representation-harmonized pure ViT in the insight that visual modeling should evolve from generation to understanding. HYDRA-TOK reformulates the standard backbone into a progressive learner that transitions from a Gen-ViT, which captures structure-preserving primitives, to a Sem-ViT for semantic encoding. Crucially, this transition is mediated by a Generation-Semantic Bottleneck (GSB), which compresses features into a low-dimensional space to filter noise for robust synthesis, then restores dimensionality to empower complex semantic comprehension. Built upon this foundation, we present HYDRA, a native unified framework integrating perception and generation within a single parameter space. Extensive experiments establish HYDRA as a new state-of-the-art. It sets a benchmark in visual reconstruction (rFID 0.08) and achieves top-tier generation performance on GenEval (0.86), DPG-Bench (86.4), and WISE (0.53), while simultaneously outperforming previous native UMMs by an average of 10.0 points across eight challenging understanding benchmarks.
Multi-Head Low-Rank Attention
Mar 02, 2026Long-context inference in large language models is bottlenecked by Key--Value (KV) cache loading during the decoding stage, where the sequential nature of generation requires repeatedly transferring the KV cache from off-chip High-Bandwidth Memory (HBM) to on-chip Static Random-Access Memory (SRAM) at each step. While Multi-Head Latent Attention (MLA) significantly reduces the total KV cache size, it suffers from a sharding bottleneck during distributed decoding via Tensor Parallelism (TP). Since its single latent head cannot be partitioned, each device is forced to redundantly load the complete KV cache for every token, consuming excessive memory traffic and diminishing TP benefits like weight sharding. In this work, we propose Multi-Head Low-Rank Attention (MLRA), which enables partitionable latent states for efficient 4-way TP decoding. Extensive experiments show that MLRA achieves state-of-the-art perplexity and downstream task performance, while also delivering a 2.8$\times$ decoding speedup over MLA. Code is available at https://github.com/SongtaoLiu0823/MLRA. Pretrained weights, along with the training and evaluation data, are available at https://huggingface.co/Soughing/MLRA.
DisCa: Accelerating Video Diffusion Transformers with Distillation-Compatible Learnable Feature Caching
Feb 05, 2026While diffusion models have achieved great success in the field of video generation, this progress is accompanied by a rapidly escalating computational burden. Among the existing acceleration methods, Feature Caching is popular due to its training-free property and considerable speedup performance, but it inevitably faces semantic and detail drop with further compression. Another widely adopted method, training-aware step-distillation, though successful in image generation, also faces drastic degradation in video generation with a few steps. Furthermore, the quality loss becomes more severe when simply applying training-free feature caching to the step-distilled models, due to the sparser sampling steps. This paper novelly introduces a distillation-compatible learnable feature caching mechanism for the first time. We employ a lightweight learnable neural predictor instead of traditional training-free heuristics for diffusion models, enabling a more accurate capture of the high-dimensional feature evolution process. Furthermore, we explore the challenges of highly compressed distillation on large-scale video models and propose a conservative Restricted MeanFlow approach to achieve more stable and lossless distillation. By undertaking these initiatives, we further push the acceleration boundaries to $11.8\times$ while preserving generation quality. Extensive experiments demonstrate the effectiveness of our method. The code is in the supplementary materials and will be publicly available.
High-Layer Attention Pruning with Rescaling
Jul 02, 2025Pruning is a highly effective approach for compressing large language models (LLMs), significantly reducing inference latency. However, conventional training-free structured pruning methods often employ a heuristic metric that indiscriminately removes some attention heads across all pruning layers, without considering their positions within the network architecture. In this work, we propose a novel pruning algorithm that strategically prunes attention heads in the model's higher layers. Since the removal of attention heads can alter the magnitude of token representations, we introduce an adaptive rescaling parameter that calibrates the representation scale post-pruning to counteract this effect. We conduct comprehensive experiments on a wide range of LLMs, including LLaMA3.1-8B, Mistral-7B-v0.3, Qwen2-7B, and Gemma2-9B. Our evaluation includes both generation and discriminative tasks across 27 datasets. The results consistently demonstrate that our method outperforms existing structured pruning methods. This improvement is particularly notable in generation tasks, where our approach significantly outperforms existing baselines.
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Dec 03, 2024



Recent advancements in video generation have significantly impacted daily life for both individuals and industries. However, the leading video generation models remain closed-source, resulting in a notable performance gap between industry capabilities and those available to the public. In this report, we introduce HunyuanVideo, an innovative open-source video foundation model that demonstrates performance in video generation comparable to, or even surpassing, that of leading closed-source models. HunyuanVideo encompasses a comprehensive framework that integrates several key elements, including data curation, advanced architectural design, progressive model scaling and training, and an efficient infrastructure tailored for large-scale model training and inference. As a result, we successfully trained a video generative model with over 13 billion parameters, making it the largest among all open-source models. We conducted extensive experiments and implemented a series of targeted designs to ensure high visual quality, motion dynamics, text-video alignment, and advanced filming techniques. According to evaluations by professionals, HunyuanVideo outperforms previous state-of-the-art models, including Runway Gen-3, Luma 1.6, and three top-performing Chinese video generative models. By releasing the code for the foundation model and its applications, we aim to bridge the gap between closed-source and open-source communities. This initiative will empower individuals within the community to experiment with their ideas, fostering a more dynamic and vibrant video generation ecosystem. The code is publicly available at https://github.com/Tencent/HunyuanVideo.
SDDBench: A Benchmark for Synthesizable Drug Design
Nov 13, 2024



A significant challenge in wet lab experiments with current drug design generative models is the trade-off between pharmacological properties and synthesizability. Molecules predicted to have highly desirable properties are often difficult to synthesize, while those that are easily synthesizable tend to exhibit less favorable properties. As a result, evaluating the synthesizability of molecules in general drug design scenarios remains a significant challenge in the field of drug discovery. The commonly used synthetic accessibility (SA) score aims to evaluate the ease of synthesizing generated molecules, but it falls short of guaranteeing that synthetic routes can actually be found. Inspired by recent advances in top-down synthetic route generation, we propose a new, data-driven metric to evaluate molecule synthesizability. Our approach directly assesses the feasibility of synthetic routes for a given molecule through our proposed round-trip score. This novel metric leverages the synergistic duality between retrosynthetic planners and reaction predictors, both of which are trained on extensive reaction datasets. To demonstrate the efficacy of our method, we conduct a comprehensive evaluation of round-trip scores alongside search success rate across a range of representative molecule generative models. Code is available at https://github.com/SongtaoLiu0823/SDDBench.
Graph Adversarial Diffusion Convolution
Jun 04, 2024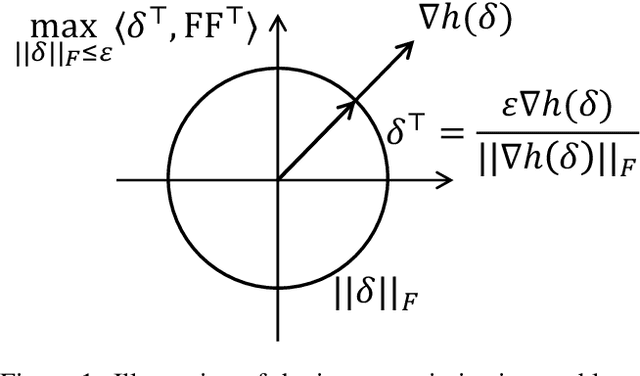
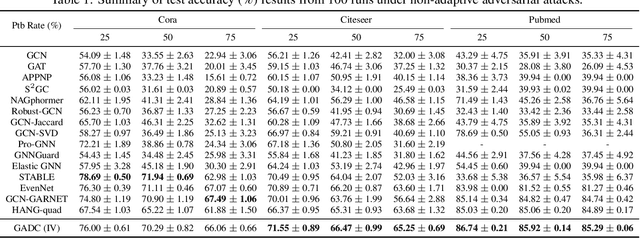

This paper introduces a min-max optimization formulation for the Graph Signal Denoising (GSD) problem. In this formulation, we first maximize the second term of GSD by introducing perturbations to the graph structure based on Laplacian distance and then minimize the overall loss of the GSD. By solving the min-max optimization problem, we derive a new variant of the Graph Diffusion Convolution (GDC) architecture, called Graph Adversarial Diffusion Convolution (GADC). GADC differs from GDC by incorporating an additional term that enhances robustness against adversarial attacks on the graph structure and noise in node features. Moreover, GADC improves the performance of GDC on heterophilic graphs. Extensive experiments demonstrate the effectiveness of GADC across various datasets. Code is available at https://github.com/SongtaoLiu0823/GADC.
Preference Optimization for Molecule Synthesis with Conditional Residual Energy-based Models
Jun 04, 2024
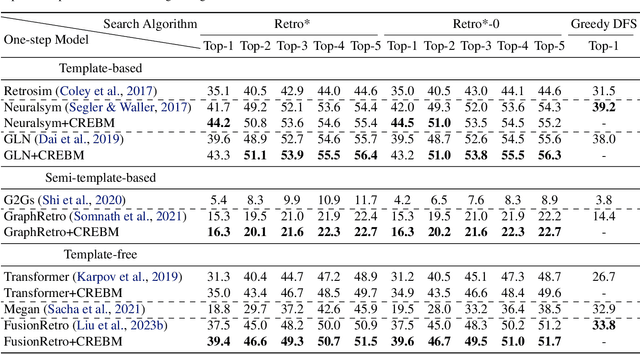
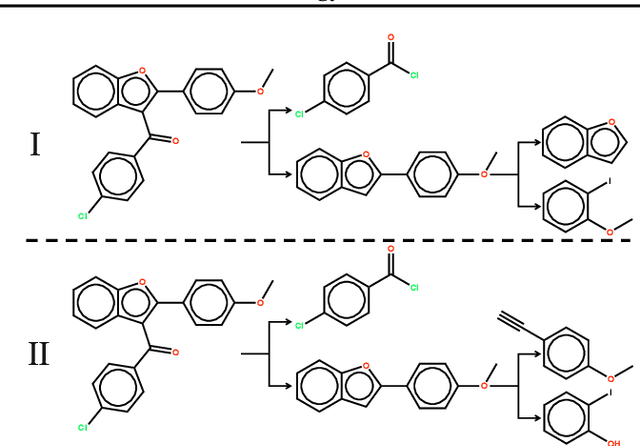
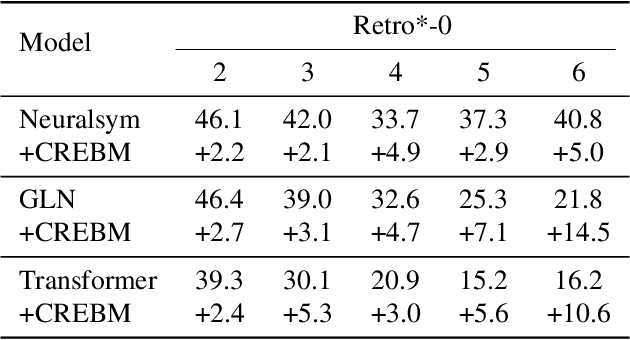
Molecule synthesis through machine learning is one of the fundamental problems in drug discovery. Current data-driven strategies employ one-step retrosynthesis models and search algorithms to predict synthetic routes in a top-bottom manner. Despite their effective performance, these strategies face limitations in the molecule synthetic route generation due to a greedy selection of the next molecule set without any lookahead. Furthermore, existing strategies cannot control the generation of synthetic routes based on possible criteria such as material costs, yields, and step count. In this work, we propose a general and principled framework via conditional residual energy-based models (EBMs), that focus on the quality of the entire synthetic route based on the specific criteria. By incorporating an additional energy-based function into our probabilistic model, our proposed algorithm can enhance the quality of the most probable synthetic routes (with higher probabilities) generated by various strategies in a plug-and-play fashion. Extensive experiments demonstrate that our framework can consistently boost performance across various strategies and outperforms previous state-of-the-art top-1 accuracy by a margin of 2.5%. Code is available at https://github.com/SongtaoLiu0823/CREBM.
Encoding Hierarchical Schema via Concept Flow for Multifaceted Ideology Detection
May 29, 2024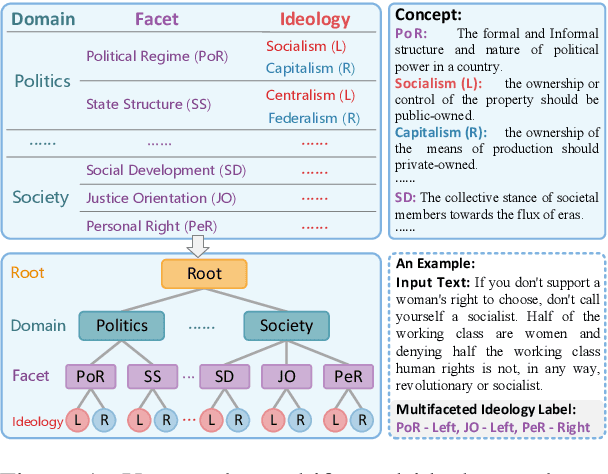
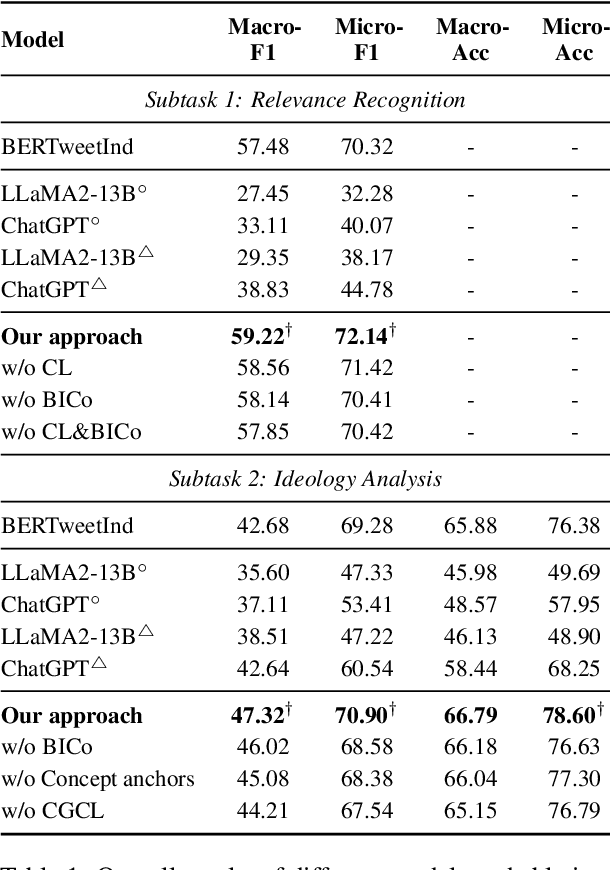
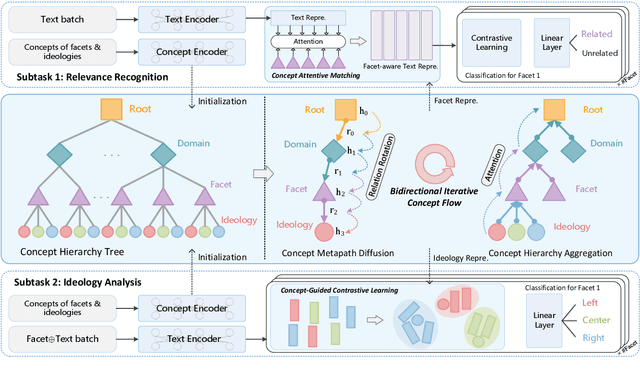

Multifaceted ideology detection (MID) aims to detect the ideological leanings of texts towards multiple facets. Previous studies on ideology detection mainly focus on one generic facet and ignore label semantics and explanatory descriptions of ideologies, which are a kind of instructive information and reveal the specific concepts of ideologies. In this paper, we develop a novel concept semantics-enhanced framework for the MID task. Specifically, we propose a bidirectional iterative concept flow (BICo) method to encode multifaceted ideologies. BICo enables the concepts to flow across levels of the schema tree and enriches concept representations with multi-granularity semantics. Furthermore, we explore concept attentive matching and concept-guided contrastive learning strategies to guide the model to capture ideology features with the learned concept semantics. Extensive experiments on the benchmark dataset show that our approach achieves state-of-the-art performance in MID, including in the cross-topic scenario.