 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGait Recognition via Collaborating Discriminative and Generative Diffusion Models
Nov 09, 2025Gait recognition offers a non-intrusive biometric solution by identifying individuals through their walking patterns. Although discriminative models have achieved notable success in this domain, the full potential of generative models remains largely underexplored. In this paper, we introduce \textbf{CoD$^2$}, a novel framework that combines the data distribution modeling capabilities of diffusion models with the semantic representation learning strengths of discriminative models to extract robust gait features. We propose a Multi-level Conditional Control strategy that incorporates both high-level identity-aware semantic conditions and low-level visual details. Specifically, the high-level condition, extracted by the discriminative extractor, guides the generation of identity-consistent gait sequences, whereas low-level visual details, such as appearance and motion, are preserved to enhance consistency. Furthermore, the generated sequences facilitate the discriminative extractor's learning, enabling it to capture more comprehensive high-level semantic features. Extensive experiments on four datasets (SUSTech1K, CCPG, GREW, and Gait3D) demonstrate that CoD$^2$ achieves state-of-the-art performance and can be seamlessly integrated with existing discriminative methods, yielding consistent improvements.
What Would Happen Next? Predicting Consequences from An Event Causality Graph
Sep 26, 2024Existing script event prediction task forcasts the subsequent event based on an event script chain. However, the evolution of historical events are more complicated in real world scenarios and the limited information provided by the event script chain also make it difficult to accurately predict subsequent events. This paper introduces a Causality Graph Event Prediction(CGEP) task that forecasting consequential event based on an Event Causality Graph (ECG). We propose a Semantic Enhanced Distance-sensitive Graph Prompt Learning (SeDGPL) Model for the CGEP task. In SeDGPL, (1) we design a Distance-sensitive Graph Linearization (DsGL) module to reformulate the ECG into a graph prompt template as the input of a PLM; (2) propose an Event-Enriched Causality Encoding (EeCE) module to integrate both event contextual semantic and graph schema information; (3) propose a Semantic Contrast Event Prediction (ScEP) module to enhance the event representation among numerous candidate events and predict consequential event following prompt learning paradigm. %We construct two CGEP datasets based on existing MAVEN-ERE and ESC corpus for experiments. Experiment results validate our argument our proposed SeDGPL model outperforms the advanced competitors for the CGEP task.
Identifying while Learning for Document Event Causality Identification
May 31, 2024



Event Causality Identification (ECI) aims to detect whether there exists a causal relation between two events in a document. Existing studies adopt a kind of identifying after learning paradigm, where events' representations are first learned and then used for the identification. Furthermore, they mainly focus on the causality existence, but ignoring causal direction. In this paper, we take care of the causal direction and propose a new identifying while learning mode for the ECI task. We argue that a few causal relations can be easily identified with high confidence, and the directionality and structure of these identified causalities can be utilized to update events' representations for boosting next round of causality identification. To this end, this paper designs an *iterative learning and identifying framework*: In each iteration, we construct an event causality graph, on which events' causal structure representations are updated for boosting causal identification. Experiments on two public datasets show that our approach outperforms the state-of-the-art algorithms in both evaluations for causality existence identification and direction identification.
Encoding Hierarchical Schema via Concept Flow for Multifaceted Ideology Detection
May 29, 2024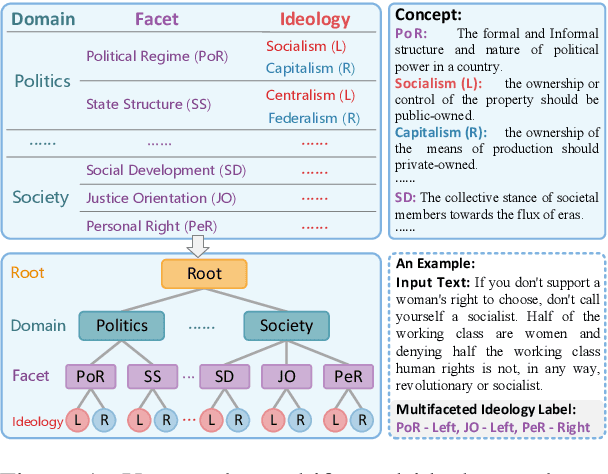
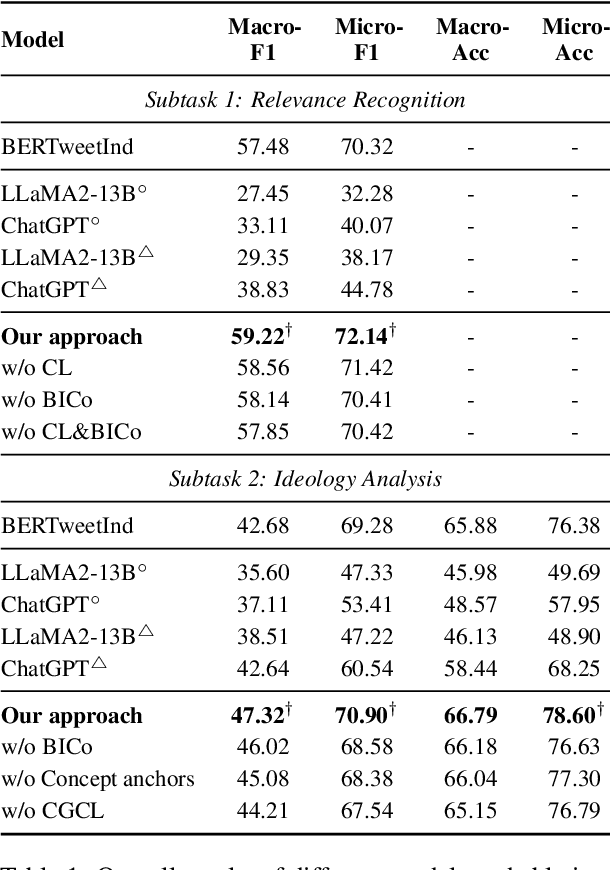
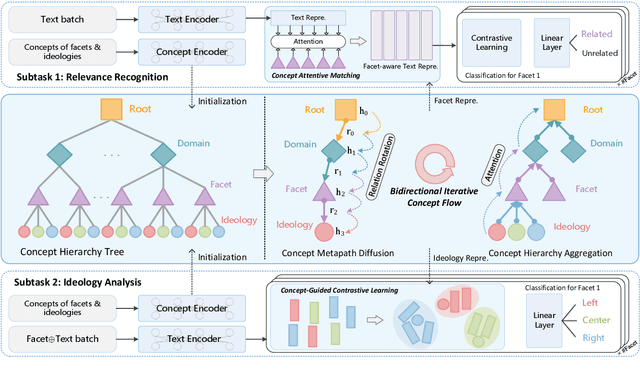

Multifaceted ideology detection (MID) aims to detect the ideological leanings of texts towards multiple facets. Previous studies on ideology detection mainly focus on one generic facet and ignore label semantics and explanatory descriptions of ideologies, which are a kind of instructive information and reveal the specific concepts of ideologies. In this paper, we develop a novel concept semantics-enhanced framework for the MID task. Specifically, we propose a bidirectional iterative concept flow (BICo) method to encode multifaceted ideologies. BICo enables the concepts to flow across levels of the schema tree and enriches concept representations with multi-granularity semantics. Furthermore, we explore concept attentive matching and concept-guided contrastive learning strategies to guide the model to capture ideology features with the learned concept semantics. Extensive experiments on the benchmark dataset show that our approach achieves state-of-the-art performance in MID, including in the cross-topic scenario.
In-context Contrastive Learning for Event Causality Identification
May 17, 2024



Event Causality Identification (ECI) aims at determining the existence of a causal relation between two events. Although recent prompt learning-based approaches have shown promising improvements on the ECI task, their performance are often subject to the delicate design of multiple prompts and the positive correlations between the main task and derivate tasks. The in-context learning paradigm provides explicit guidance for label prediction in the prompt learning paradigm, alleviating its reliance on complex prompts and derivative tasks. However, it does not distinguish between positive and negative demonstrations for analogy learning. Motivated from such considerations, this paper proposes an In-Context Contrastive Learning (ICCL) model that utilizes contrastive learning to enhance the effectiveness of both positive and negative demonstrations. Additionally, we apply contrastive learning to event pairs to better facilitate event causality identification. Our ICCL is evaluated on the widely used corpora, including the EventStoryLine and Causal-TimeBank, and results show significant performance improvements over the state-of-the-art algorithms.
One Backpropagation in Two Tower Recommendation Models
Mar 27, 2024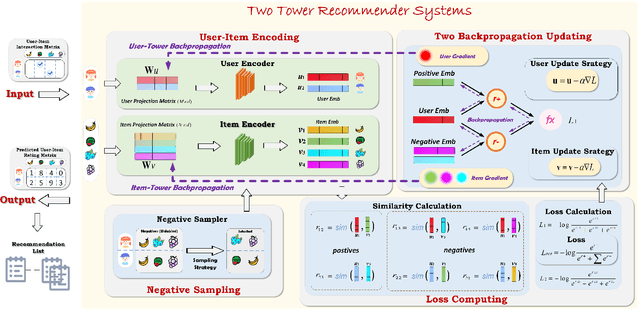
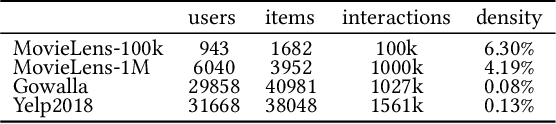
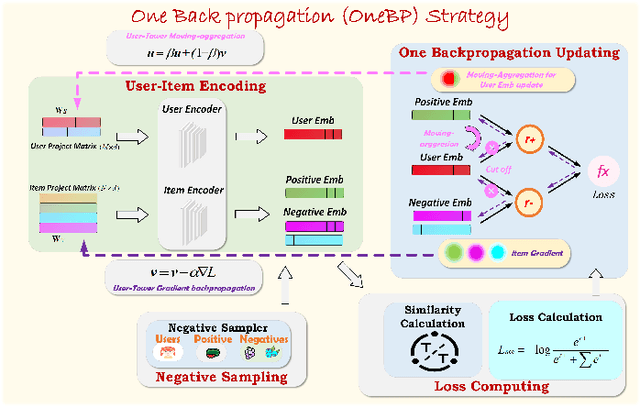
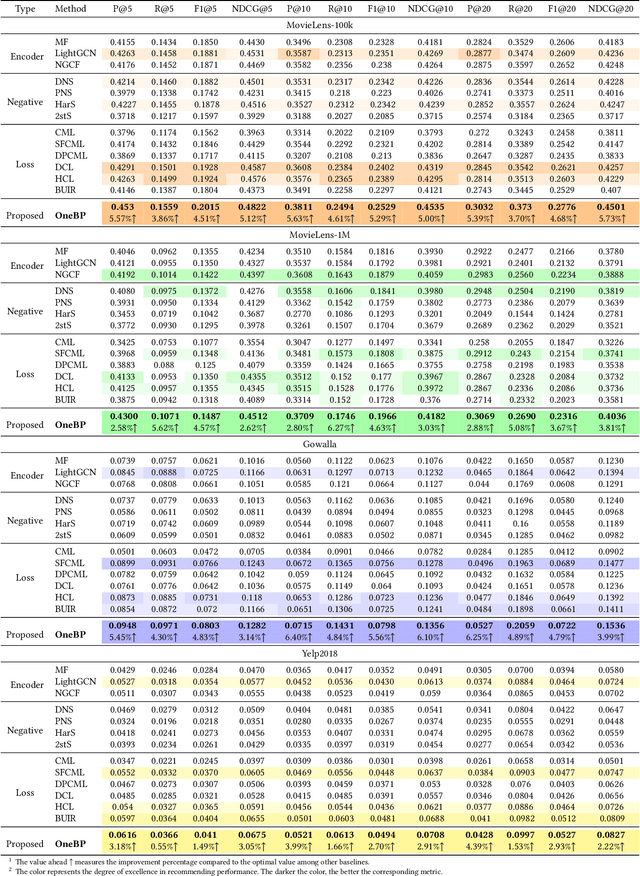
Recent years have witnessed extensive researches on developing two tower recommendation models for relieving information overload. Four building modules can be identified in such models, namely, user-item encoding, negative sampling, loss computing and back-propagation updating. To the best of our knowledge, existing algorithms have researched only on the first three modules, yet neglecting the backpropagation module. They all adopt a kind of two backpropagation strategy, which are based on an implicit assumption of equally treating users and items in the training phase. In this paper, we challenge such an equal training assumption and propose a novel one backpropagation updating strategy, which keeps the normal gradient backpropagation for the item encoding tower, but cuts off the backpropagation for the user encoding tower. Instead, we propose a moving-aggregation updating strategy to update a user encoding in each training epoch. Except the proposed backpropagation updating module, we implement the other three modules with the most straightforward choices. Experiments on four public datasets validate the effectiveness and efficiency of our model in terms of improved recommendation performance and reduced computation overload over the state-of-the-art competitors.
Adaptive Prompt Learning with Distilled Connective Knowledge for Implicit Discourse Relation Recognition
Sep 14, 2023



Implicit discourse relation recognition (IDRR) aims at recognizing the discourse relation between two text segments without an explicit connective. Recently, the prompt learning has just been applied to the IDRR task with great performance improvements over various neural network-based approaches. However, the discrete nature of the state-art-of-art prompting approach requires manual design of templates and answers, a big hurdle for its practical applications. In this paper, we propose a continuous version of prompt learning together with connective knowledge distillation, called AdaptPrompt, to reduce manual design efforts via continuous prompting while further improving performance via knowledge transfer. In particular, we design and train a few virtual tokens to form continuous templates and automatically select the most suitable one by gradient search in the embedding space. We also design an answer-relation mapping rule to generate a few virtual answers as the answer space. Furthermore, we notice the importance of annotated connectives in the training dataset and design a teacher-student architecture for knowledge transfer. Experiments on the up-to-date PDTB Corpus V3.0 validate our design objectives in terms of the better relation recognition performance over the state-of-the-art competitors.
Debiased Pairwise Learning from Positive-Unlabeled Implicit Feedback
Jul 29, 2023



Learning contrastive representations from pairwise comparisons has achieved remarkable success in various fields, such as natural language processing, computer vision, and information retrieval. Collaborative filtering algorithms based on pairwise learning also rooted in this paradigm. A significant concern is the absence of labels for negative instances in implicit feedback data, which often results in the random selected negative instances contains false negatives and inevitably, biased embeddings. To address this issue, we introduce a novel correction method for sampling bias that yields a modified loss for pairwise learning called debiased pairwise loss (DPL). The key idea underlying DPL is to correct the biased probability estimates that result from false negatives, thereby correcting the gradients to approximate those of fully supervised data. The implementation of DPL only requires a small modification of the codes. Experimental studies on five public datasets validate the effectiveness of proposed learning method.
DAPrompt: Deterministic Assumption Prompt Learning for Event Causality Identification
Jul 19, 2023



Event Causality Identification (ECI) aims at determining whether there is a causal relation between two event mentions. Conventional prompt learning designs a prompt template to first predict an answer word and then maps it to the final decision. Unlike conventional prompts, we argue that predicting an answer word may not be a necessary prerequisite for the ECI task. Instead, we can first make a deterministic assumption on the existence of causal relation between two events and then evaluate its rationality to either accept or reject the assumption. The design motivation is to try the most utilization of the encyclopedia-like knowledge embedded in a pre-trained language model. In light of such considerations, we propose a deterministic assumption prompt learning model, called DAPrompt, for the ECI task. In particular, we design a simple deterministic assumption template concatenating with the input event pair, which includes two masks as predicted events' tokens. We use the probabilities of predicted events to evaluate the assumption rationality for the final event causality decision. Experiments on the EventStoryLine corpus and Causal-TimeBank corpus validate our design objective in terms of significant performance improvements over the state-of-the-art algorithms.
Reducing Popularity Bias in Recommender Systems through AUC-Optimal Negative Sampling
Jun 02, 2023



Popularity bias is a persistent issue associated with recommendation systems, posing challenges to both fairness and efficiency. Existing literature widely acknowledges that reducing popularity bias often requires sacrificing recommendation accuracy. In this paper, we challenge this commonly held belief. Our analysis under general bias-variance decomposition framework shows that reducing bias can actually lead to improved model performance under certain conditions. To achieve this win-win situation, we propose to intervene in model training through negative sampling thereby modifying model predictions. Specifically, we provide an optimal negative sampling rule that maximizes partial AUC to preserve the accuracy of any given model, while correcting sample information and prior information to reduce popularity bias in a flexible and principled way. Our experimental results on real-world datasets demonstrate the superiority of our approach in improving recommendation performance and reducing popularity bias.