 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen KV Cache Reuse Fails in Multi-Agent Systems: Cross-Candidate Interaction is Crucial for LLM Judges
Jan 13, 2026Multi-agent LLM systems routinely generate multiple candidate responses that are aggregated by an LLM judge. To reduce the dominant prefill cost in such pipelines, recent work advocates KV cache reuse across partially shared contexts and reports substantial speedups for generation agents. In this work, we show that these efficiency gains do not transfer uniformly to judge-centric inference. Across GSM8K, MMLU, and HumanEval, we find that reuse strategies that are effective for execution agents can severely perturb judge behavior: end-task accuracy may appear stable, yet the judge's selection becomes highly inconsistent with dense prefill. We quantify this risk using Judge Consistency Rate (JCR) and provide diagnostics showing that reuse systematically weakens cross-candidate attention, especially for later candidate blocks. Our ablation further demonstrates that explicit cross-candidate interaction is crucial for preserving dense-prefill decisions. Overall, our results identify a previously overlooked failure mode of KV cache reuse and highlight judge-centric inference as a distinct regime that demands dedicated, risk-aware system design.
Large Language Models Have Intrinsic Meta-Cognition, but Need a Good Lens
Jun 10, 2025Previous research has primarily focused on the cognitive error detection capabilities of Large Language Models (LLMs), often prompting them to analyze mistakes in reasoning chains. However, few studies have examined the meta-cognitive abilities of LLMs (e.g., their self-awareness of step errors), which are crucial for their reliability. While studies on LLM self-evaluation present some measures, such as perplexity, which can reflect the answer correctness and be viewed as the lens of meta-cognition, they lack step-level analysis and adaptation. This paper studies the evaluation of LLM meta-cognition using the current lenses and how to improve these lenses. Specifically, we propose AutoMeco, an Automated Meta-cognition Evaluation framework for benchmarking the existing lenses. Furthermore, a training-free Markovian Intrinsic Reward Adjustment strategy, MIRA, is proposed to boost current meta-cognition lenses. Experimental results on three mathematical reasoning datasets and three LLMs show the reasonableness of AutoMeco by comparing it with Best-of-N verification. Moreover, the meta-cognition ability of LLMs can be better evaluated using MIRA.
VReST: Enhancing Reasoning in Large Vision-Language Models through Tree Search and Self-Reward Mechanism
Jun 10, 2025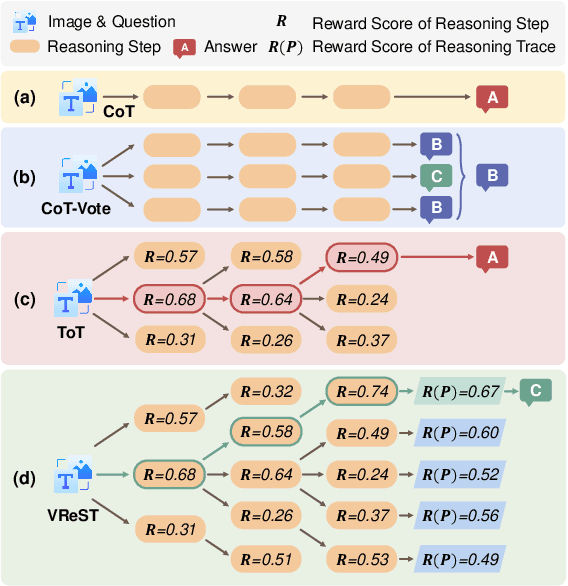
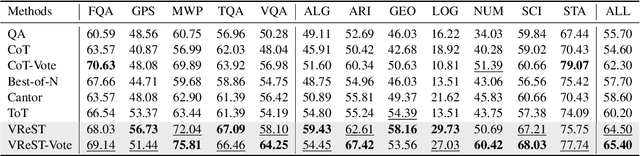
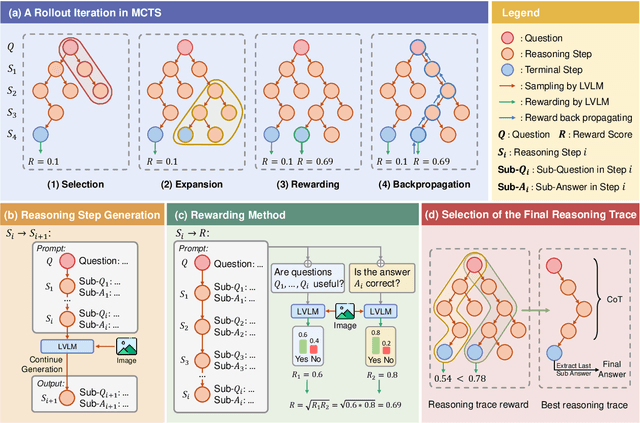
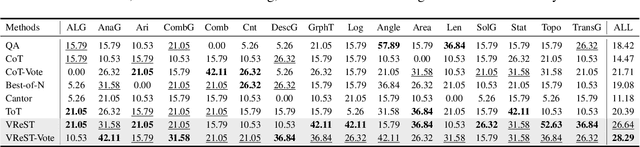
Large Vision-Language Models (LVLMs) have shown exceptional performance in multimodal tasks, but their effectiveness in complex visual reasoning is still constrained, especially when employing Chain-of-Thought prompting techniques. In this paper, we propose VReST, a novel training-free approach that enhances Reasoning in LVLMs through Monte Carlo Tree Search and Self-Reward mechanisms. VReST meticulously traverses the reasoning landscape by establishing a search tree, where each node encapsulates a reasoning step, and each path delineates a comprehensive reasoning sequence. Our innovative multimodal Self-Reward mechanism assesses the quality of reasoning steps by integrating the utility of sub-questions, answer correctness, and the relevance of vision-language clues, all without the need for additional models. VReST surpasses current prompting methods and secures state-of-the-art performance across three multimodal mathematical reasoning benchmarks. Furthermore, it substantiates the efficacy of test-time scaling laws in multimodal tasks, offering a promising direction for future research.
Benchmarking Temporal Reasoning and Alignment Across Chinese Dynasties
Feb 24, 2025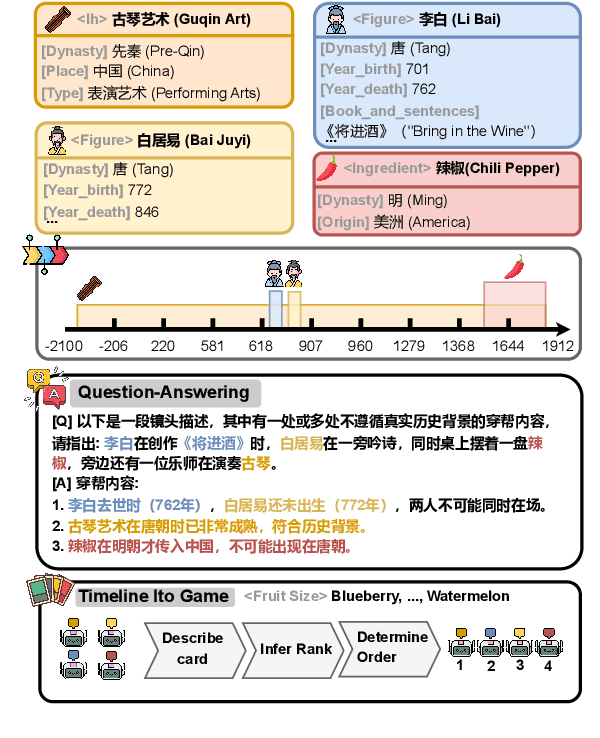
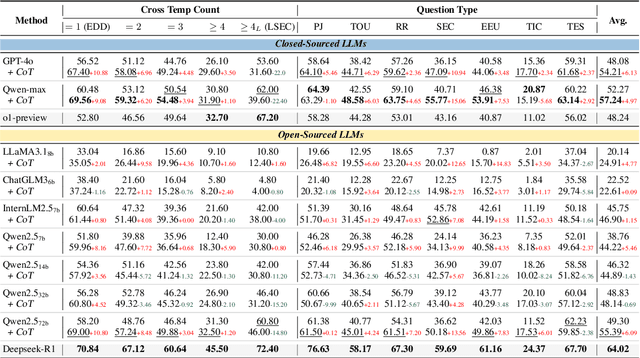
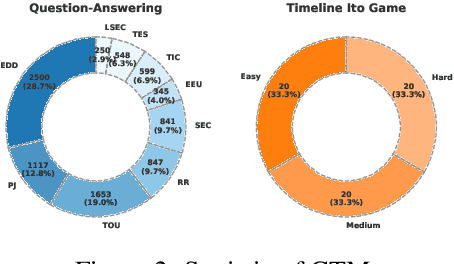
Temporal reasoning is fundamental to human cognition and is crucial for various real-world applications. While recent advances in Large Language Models have demonstrated promising capabilities in temporal reasoning, existing benchmarks primarily rely on rule-based construction, lack contextual depth, and involve a limited range of temporal entities. To address these limitations, we introduce Chinese Time Reasoning (CTM), a benchmark designed to evaluate LLMs on temporal reasoning within the extensive scope of Chinese dynastic chronology. CTM emphasizes cross-entity relationships, pairwise temporal alignment, and contextualized and culturally-grounded reasoning, providing a comprehensive evaluation. Extensive experimental results reveal the challenges posed by CTM and highlight potential avenues for improvement.
WebWalker: Benchmarking LLMs in Web Traversal
Jan 14, 2025



Retrieval-augmented generation (RAG) demonstrates remarkable performance across tasks in open-domain question-answering. However, traditional search engines may retrieve shallow content, limiting the ability of LLMs to handle complex, multi-layered information. To address it, we introduce WebWalkerQA, a benchmark designed to assess the ability of LLMs to perform web traversal. It evaluates the capacity of LLMs to traverse a website's subpages to extract high-quality data systematically. We propose WebWalker, which is a multi-agent framework that mimics human-like web navigation through an explore-critic paradigm. Extensive experimental results show that WebWalkerQA is challenging and demonstrates the effectiveness of RAG combined with WebWalker, through the horizontal and vertical integration in real-world scenarios.
SCOPE: Optimizing Key-Value Cache Compression in Long-context Generation
Dec 18, 2024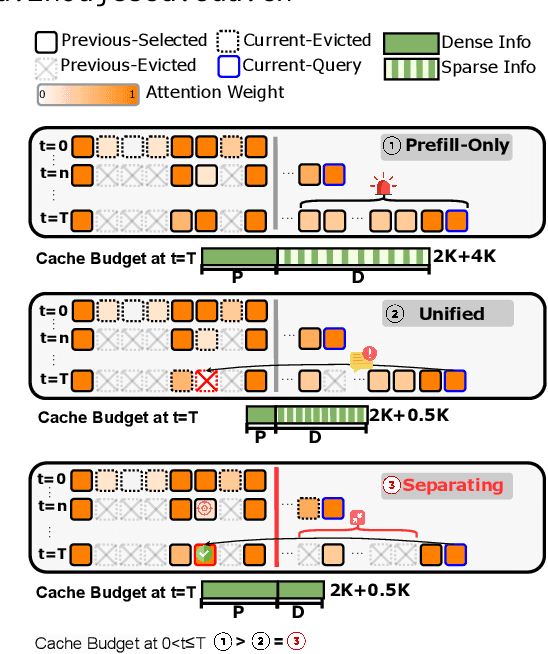
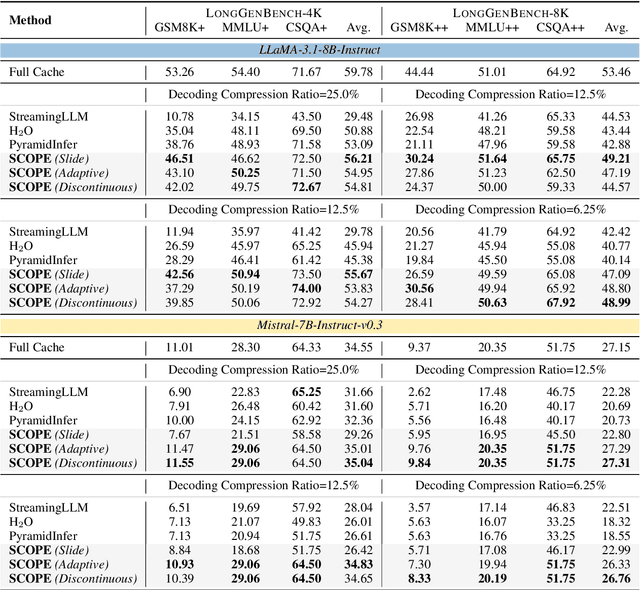
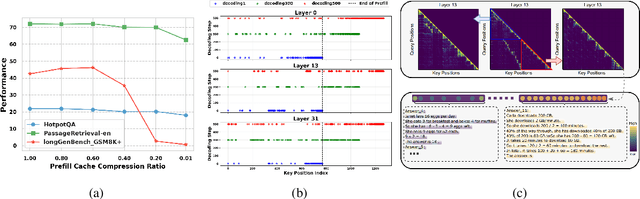
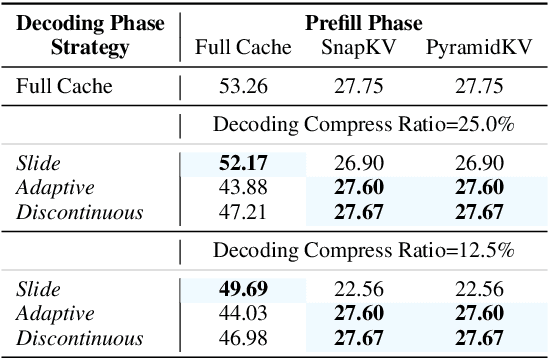
Key-Value (KV) cache has become a bottleneck of LLMs for long-context generation. Despite the numerous efforts in this area, the optimization for the decoding phase is generally ignored. However, we believe such optimization is crucial, especially for long-output generation tasks based on the following two observations: (i) Excessive compression during the prefill phase, which requires specific full context impairs the comprehension of the reasoning task; (ii) Deviation of heavy hitters occurs in the reasoning tasks with long outputs. Therefore, SCOPE, a simple yet efficient framework that separately performs KV cache optimization during the prefill and decoding phases, is introduced. Specifically, the KV cache during the prefill phase is preserved to maintain the essential information, while a novel strategy based on sliding is proposed to select essential heavy hitters for the decoding phase. Memory usage and memory transfer are further optimized using adaptive and discontinuous strategies. Extensive experiments on LongGenBench show the effectiveness and generalization of SCOPE and its compatibility as a plug-in to other prefill-only KV compression methods.
SEED: Accelerating Reasoning Tree Construction via Scheduled Speculative Decoding
Jun 26, 2024



Large Language Models (LLMs) demonstrate remarkable emergent abilities across various tasks, yet fall short of complex reasoning and planning tasks. The tree-search-based reasoning methods address this by surpassing the capabilities of chain-of-thought prompting, encouraging exploration of intermediate steps. However, such methods introduce significant inference latency due to the systematic exploration and evaluation of multiple thought paths. This paper introduces SeeD, a novel and efficient inference framework to optimize runtime speed and GPU memory management concurrently. By employing a scheduled speculative execution, SeeD efficiently handles multiple iterations for the thought generation and the state evaluation, leveraging a rounds-scheduled strategy to manage draft model dispatching. Extensive experimental evaluations on three reasoning datasets demonstrate superior speedup performance of SeeD, providing a viable path for batched inference in training-free speculative decoding.
Adaptive Prompt Learning with Distilled Connective Knowledge for Implicit Discourse Relation Recognition
Sep 14, 2023



Implicit discourse relation recognition (IDRR) aims at recognizing the discourse relation between two text segments without an explicit connective. Recently, the prompt learning has just been applied to the IDRR task with great performance improvements over various neural network-based approaches. However, the discrete nature of the state-art-of-art prompting approach requires manual design of templates and answers, a big hurdle for its practical applications. In this paper, we propose a continuous version of prompt learning together with connective knowledge distillation, called AdaptPrompt, to reduce manual design efforts via continuous prompting while further improving performance via knowledge transfer. In particular, we design and train a few virtual tokens to form continuous templates and automatically select the most suitable one by gradient search in the embedding space. We also design an answer-relation mapping rule to generate a few virtual answers as the answer space. Furthermore, we notice the importance of annotated connectives in the training dataset and design a teacher-student architecture for knowledge transfer. Experiments on the up-to-date PDTB Corpus V3.0 validate our design objectives in terms of the better relation recognition performance over the state-of-the-art competitors.