 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVReST: Enhancing Reasoning in Large Vision-Language Models through Tree Search and Self-Reward Mechanism
Jun 10, 2025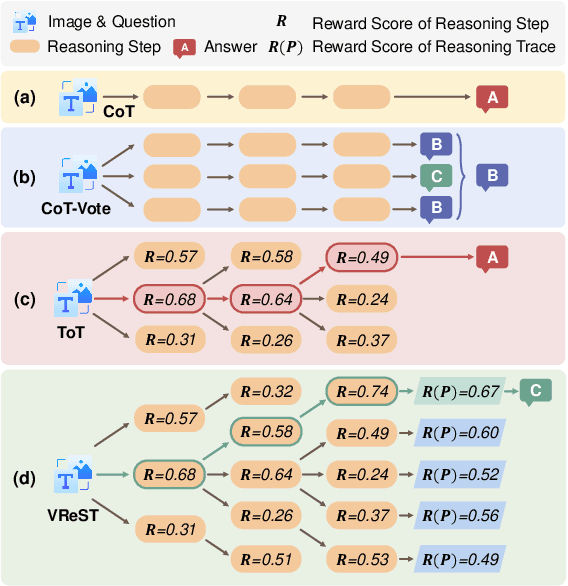
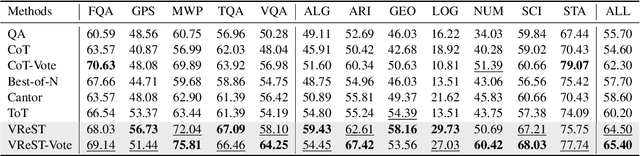
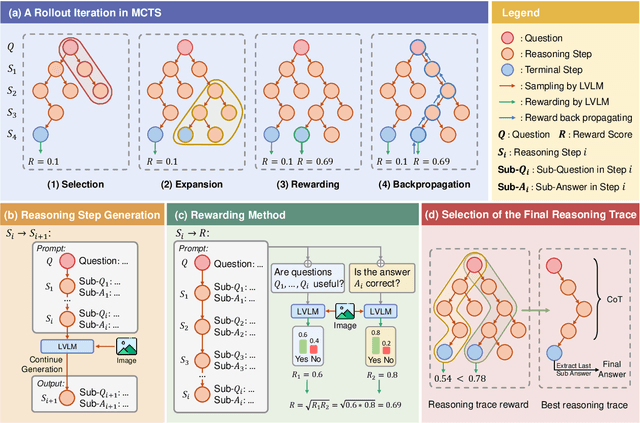
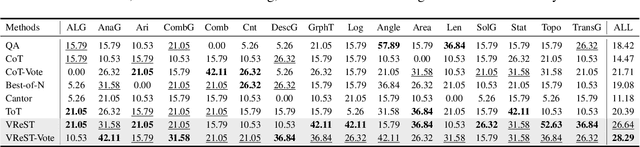
Large Vision-Language Models (LVLMs) have shown exceptional performance in multimodal tasks, but their effectiveness in complex visual reasoning is still constrained, especially when employing Chain-of-Thought prompting techniques. In this paper, we propose VReST, a novel training-free approach that enhances Reasoning in LVLMs through Monte Carlo Tree Search and Self-Reward mechanisms. VReST meticulously traverses the reasoning landscape by establishing a search tree, where each node encapsulates a reasoning step, and each path delineates a comprehensive reasoning sequence. Our innovative multimodal Self-Reward mechanism assesses the quality of reasoning steps by integrating the utility of sub-questions, answer correctness, and the relevance of vision-language clues, all without the need for additional models. VReST surpasses current prompting methods and secures state-of-the-art performance across three multimodal mathematical reasoning benchmarks. Furthermore, it substantiates the efficacy of test-time scaling laws in multimodal tasks, offering a promising direction for future research.
SCOPE: Optimizing Key-Value Cache Compression in Long-context Generation
Dec 18, 2024Key-Value (KV) cache has become a bottleneck of LLMs for long-context generation. Despite the numerous efforts in this area, the optimization for the decoding phase is generally ignored. However, we believe such optimization is crucial, especially for long-output generation tasks based on the following two observations: (i) Excessive compression during the prefill phase, which requires specific full context impairs the comprehension of the reasoning task; (ii) Deviation of heavy hitters occurs in the reasoning tasks with long outputs. Therefore, SCOPE, a simple yet efficient framework that separately performs KV cache optimization during the prefill and decoding phases, is introduced. Specifically, the KV cache during the prefill phase is preserved to maintain the essential information, while a novel strategy based on sliding is proposed to select essential heavy hitters for the decoding phase. Memory usage and memory transfer are further optimized using adaptive and discontinuous strategies. Extensive experiments on LongGenBench show the effectiveness and generalization of SCOPE and its compatibility as a plug-in to other prefill-only KV compression methods.
AdaCQR: Enhancing Query Reformulation for Conversational Search via Sparse and Dense Retrieval Alignment
Jul 02, 2024Conversational Query Reformulation (CQR) has significantly advanced in addressing the challenges of conversational search, particularly those stemming from the latent user intent and the need for historical context. Recent works aimed to boost the performance of CRQ through alignment. However, they are designed for one specific retrieval system, which potentially results in poor generalization. To overcome this limitation, we present a novel framework AdaCQR. By aligning reformulation models with both term-based and semantic-based retrieval systems, AdaCQR enhances the generalizability of information-seeking queries across diverse retrieval environments through a dual-phase training strategy. We also developed two effective approaches for acquiring superior labels and diverse input candidates, boosting the efficiency and robustness of the framework. Experimental evaluations on the TopiOCQA and QReCC datasets demonstrate that AdaCQR significantly outperforms existing methods, offering both quantitative and qualitative improvements in conversational query reformulation.
SEED: Accelerating Reasoning Tree Construction via Scheduled Speculative Decoding
Jun 26, 2024



Large Language Models (LLMs) demonstrate remarkable emergent abilities across various tasks, yet fall short of complex reasoning and planning tasks. The tree-search-based reasoning methods address this by surpassing the capabilities of chain-of-thought prompting, encouraging exploration of intermediate steps. However, such methods introduce significant inference latency due to the systematic exploration and evaluation of multiple thought paths. This paper introduces SeeD, a novel and efficient inference framework to optimize runtime speed and GPU memory management concurrently. By employing a scheduled speculative execution, SeeD efficiently handles multiple iterations for the thought generation and the state evaluation, leveraging a rounds-scheduled strategy to manage draft model dispatching. Extensive experimental evaluations on three reasoning datasets demonstrate superior speedup performance of SeeD, providing a viable path for batched inference in training-free speculative decoding.
Large, Small or Both: A Novel Data Augmentation Framework Based on Language Models for Debiasing Opinion Summarization
Mar 19, 2024



As more than 70$\%$ of reviews in the existing opinion summary data set are positive, current opinion summarization approaches are reluctant to generate negative summaries given the input of negative texts. To address such sentiment bias, a direct approach without the over-reliance on a specific framework is to generate additional data based on large language models to balance the emotional distribution of the dataset. However, data augmentation based on large language models faces two disadvantages: 1) the potential issues or toxicity in the augmented data; 2) the expensive costs. Therefore, in this paper, we propose a novel data augmentation framework based on both large and small language models for debiasing opinion summarization. In specific, a small size of synthesized negative reviews is obtained by rewriting the positive text via a large language model. Then, a disentangle reconstruction model is trained based on the generated data. After training, a large amount of synthetic data can be obtained by decoding the new representation obtained from the combination of different sample representations and filtering based on confusion degree and sentiment classification. Experiments have proved that our framework can effectively alleviate emotional bias same as using only large models, but more economically.