 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Meta-Reasoning: Metacognitive Consolidation for Self-Improving LLM Reasoning
Apr 19, 2026Large language models (LLMs) have demonstrated strong reasoning capabilities, and as existing approaches for enhancing LLM reasoning continue to mature, increasing attention has shifted toward meta-reasoning as a promising direction for further improvement. However, most existing meta-reasoning methods remain episodic: they focus on executing complex meta-reasoning routines within individual instances, but ignore the accumulation of reusable meta-reasoning skills across instances, leading to recurring failure modes and repeatedly high metacognitive effort. In this paper, we introduce Metacognitive Consolidation, a novel framework in which a model consolidates metacognitive experience from past reasoning episodes into reusable knowledge that improves future meta-reasoning. We instantiate this framework by structuring instance-level problem solving into distinct roles for reasoning, monitoring, and control to generate rich, attributable meta-level traces. These traces are then consolidated through a hierarchical, multi-timescale update mechanism that gradually forms evolving meta-knowledge. Experimental results demonstrate consistent performance gains across benchmarks and backbone models, and show that performance improves as metacognitive experience accumulates over time.
SynGraph: A Dynamic Graph-LLM Synthesis Framework for Sparse Streaming User Sentiment Modeling
Mar 06, 2025User reviews on e-commerce platforms exhibit dynamic sentiment patterns driven by temporal and contextual factors. Traditional sentiment analysis methods focus on static reviews, failing to capture the evolving temporal relationship between user sentiment rating and textual content. Sentiment analysis on streaming reviews addresses this limitation by modeling and predicting the temporal evolution of user sentiments. However, it suffers from data sparsity, manifesting in temporal, spatial, and combined forms. In this paper, we introduce SynGraph, a novel framework designed to address data sparsity in sentiment analysis on streaming reviews. SynGraph alleviates data sparsity by categorizing users into mid-tail, long-tail, and extreme scenarios and incorporating LLM-augmented enhancements within a dynamic graph-based structure. Experiments on real-world datasets demonstrate its effectiveness in addressing sparsity and improving sentiment modeling in streaming reviews.
PROPER: A Progressive Learning Framework for Personalized Large Language Models with Group-Level Adaptation
Mar 03, 2025Personalized large language models (LLMs) aim to tailor their outputs to user preferences. Recent advances in parameter-efficient fine-tuning (PEFT) methods have highlighted the effectiveness of adapting population-level LLMs to personalized LLMs by fine-tuning user-specific parameters with user history. However, user data is typically sparse, making it challenging to adapt LLMs to specific user patterns. To address this challenge, we propose PROgressive PERsonalization (PROPER), a novel progressive learning framework inspired by meso-level theory in social science. PROPER bridges population-level and user-level models by grouping users based on preferences and adapting LLMs in stages. It combines a Mixture-of-Experts (MoE) structure with Low Ranked Adaptation (LoRA), using a user-aware router to assign users to appropriate groups automatically. Additionally, a LoRA-aware router is proposed to facilitate the integration of individual user LoRAs with group-level LoRAs. Experimental results show that PROPER significantly outperforms SOTA models across multiple tasks, demonstrating the effectiveness of our approach.
Explainable Depression Detection in Clinical Interviews with Personalized Retrieval-Augmented Generation
Mar 03, 2025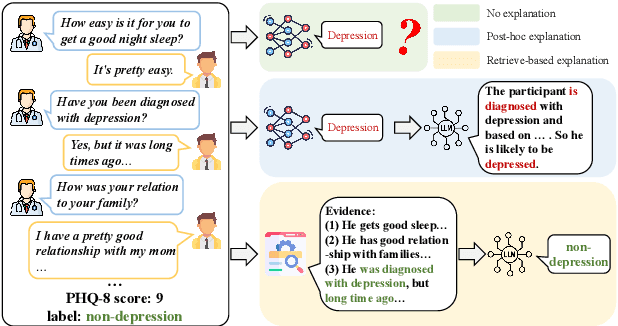
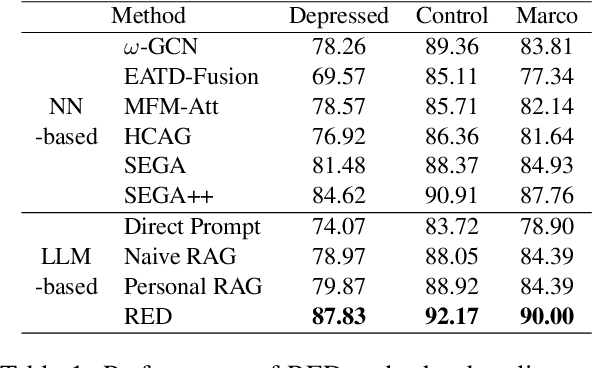
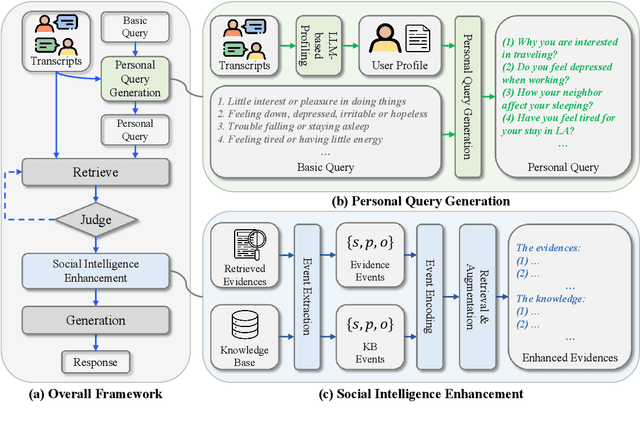
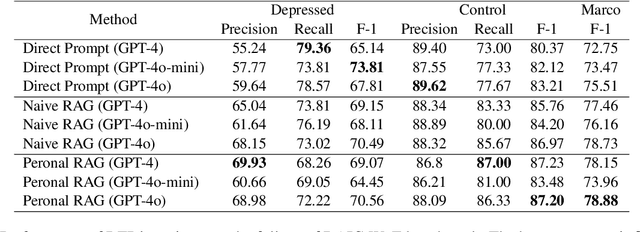
Depression is a widespread mental health disorder, and clinical interviews are the gold standard for assessment. However, their reliance on scarce professionals highlights the need for automated detection. Current systems mainly employ black-box neural networks, which lack interpretability, which is crucial in mental health contexts. Some attempts to improve interpretability use post-hoc LLM generation but suffer from hallucination. To address these limitations, we propose RED, a Retrieval-augmented generation framework for Explainable depression Detection. RED retrieves evidence from clinical interview transcripts, providing explanations for predictions. Traditional query-based retrieval systems use a one-size-fits-all approach, which may not be optimal for depression detection, as user backgrounds and situations vary. We introduce a personalized query generation module that combines standard queries with user-specific background inferred by LLMs, tailoring retrieval to individual contexts. Additionally, to enhance LLM performance in social intelligence, we augment LLMs by retrieving relevant knowledge from a social intelligence datastore using an event-centric retriever. Experimental results on the real-world benchmark demonstrate RED's effectiveness compared to neural networks and LLM-based baselines.
CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation
Feb 28, 2025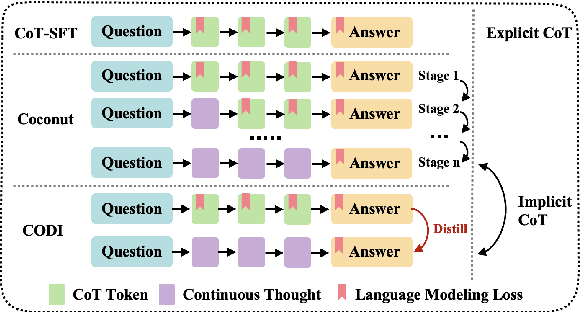
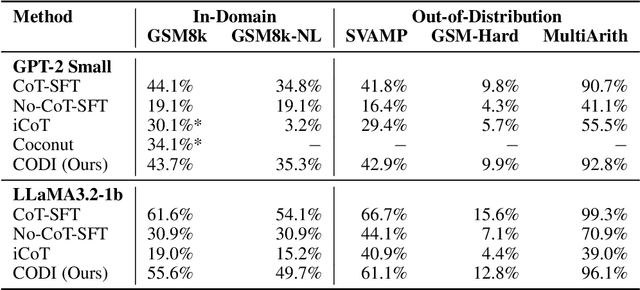
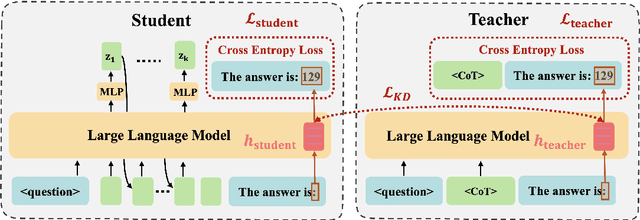
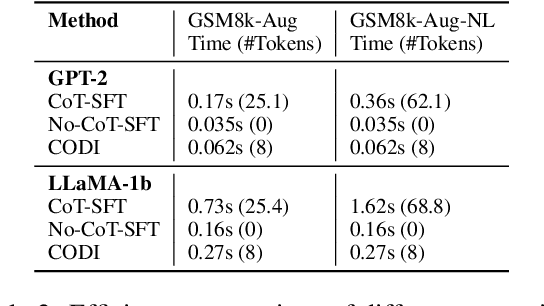
Chain-of-Thought (CoT) enhances Large Language Models (LLMs) by enabling step-by-step reasoning in natural language. However, the language space may be suboptimal for reasoning. While implicit CoT methods attempt to enable reasoning without explicit CoT tokens, they have consistently lagged behind explicit CoT method in task performance. We propose CODI (Continuous Chain-of-Thought via Self-Distillation), a novel framework that distills CoT into a continuous space, where a shared model acts as both teacher and student, jointly learning explicit and implicit CoT while aligning their hidden activation on the token generating the final answer. CODI is the first implicit CoT method to match explicit CoT's performance on GSM8k while achieving 3.1x compression, surpassing the previous state-of-the-art by 28.2% in accuracy. Furthermore, CODI demonstrates scalability, robustness, and generalizability to more complex CoT datasets. Additionally, CODI retains interpretability by decoding its continuous thoughts, making its reasoning process transparent. Our findings establish implicit CoT as not only a more efficient but a powerful alternative to explicit CoT.
RGAR: Recurrence Generation-augmented Retrieval for Factual-aware Medical Question Answering
Feb 19, 2025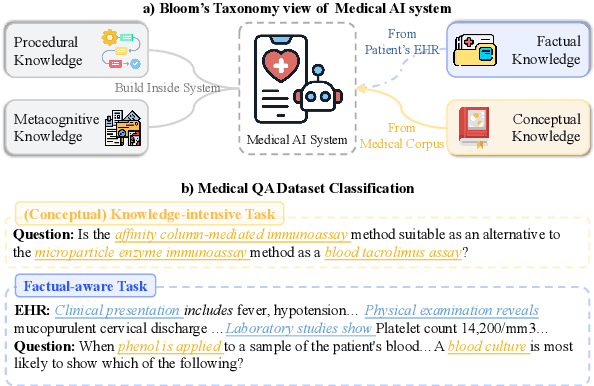
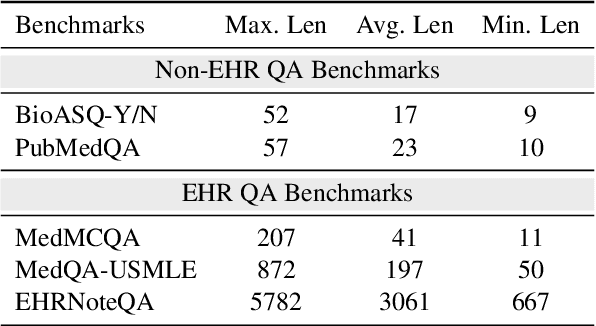
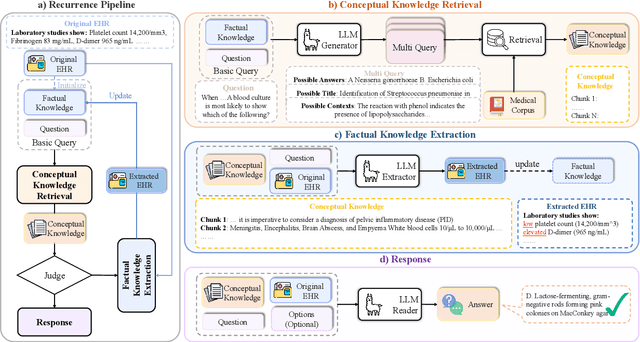
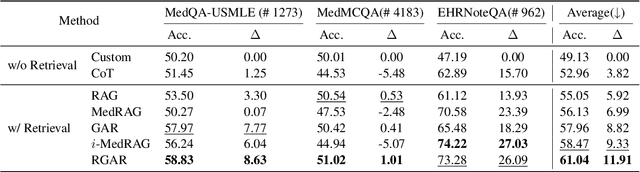
Medical question answering requires extensive access to specialized conceptual knowledge. The current paradigm, Retrieval-Augmented Generation (RAG), acquires expertise medical knowledge through large-scale corpus retrieval and uses this knowledge to guide a general-purpose large language model (LLM) for generating answers. However, existing retrieval approaches often overlook the importance of factual knowledge, which limits the relevance of retrieved conceptual knowledge and restricts its applicability in real-world scenarios, such as clinical decision-making based on Electronic Health Records (EHRs). This paper introduces RGAR, a recurrence generation-augmented retrieval framework that retrieves both relevant factual and conceptual knowledge from dual sources (i.e., EHRs and the corpus), allowing them to interact and refine each another. Through extensive evaluation across three factual-aware medical question answering benchmarks, RGAR establishes a new state-of-the-art performance among medical RAG systems. Notably, the Llama-3.1-8B-Instruct model with RGAR surpasses the considerably larger, RAG-enhanced GPT-3.5. Our findings demonstrate the benefit of extracting factual knowledge for retrieval, which consistently yields improved generation quality.
WebWalker: Benchmarking LLMs in Web Traversal
Jan 14, 2025



Retrieval-augmented generation (RAG) demonstrates remarkable performance across tasks in open-domain question-answering. However, traditional search engines may retrieve shallow content, limiting the ability of LLMs to handle complex, multi-layered information. To address it, we introduce WebWalkerQA, a benchmark designed to assess the ability of LLMs to perform web traversal. It evaluates the capacity of LLMs to traverse a website's subpages to extract high-quality data systematically. We propose WebWalker, which is a multi-agent framework that mimics human-like web navigation through an explore-critic paradigm. Extensive experimental results show that WebWalkerQA is challenging and demonstrates the effectiveness of RAG combined with WebWalker, through the horizontal and vertical integration in real-world scenarios.
SCOPE: Optimizing Key-Value Cache Compression in Long-context Generation
Dec 18, 2024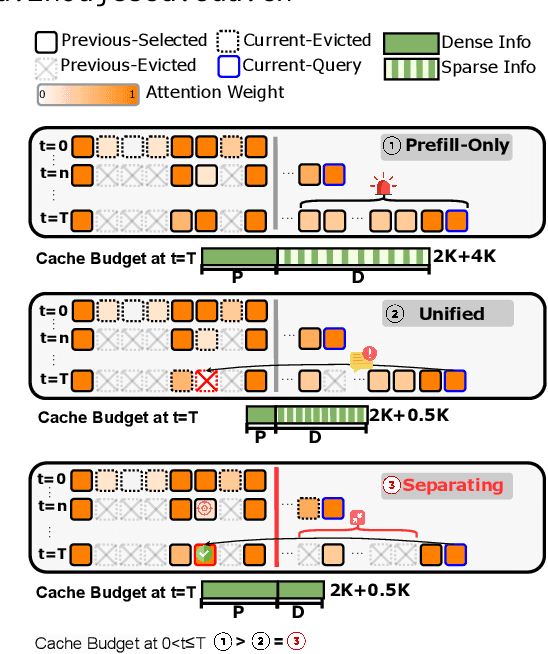
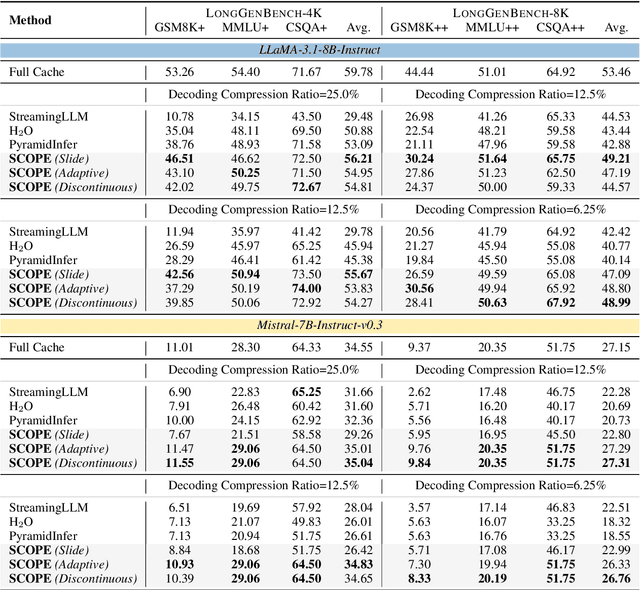
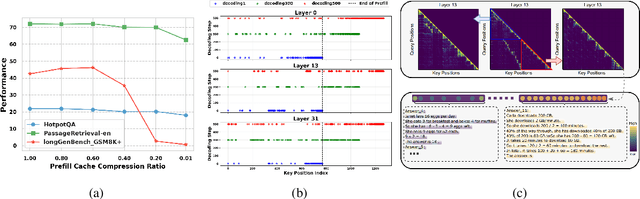
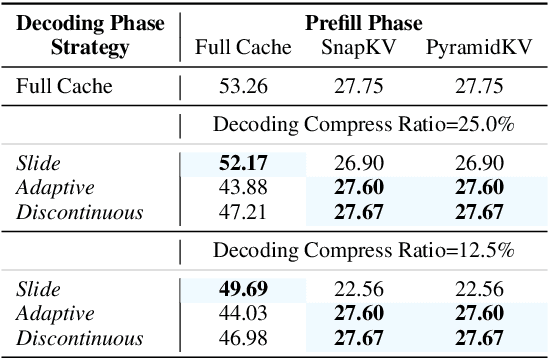
Key-Value (KV) cache has become a bottleneck of LLMs for long-context generation. Despite the numerous efforts in this area, the optimization for the decoding phase is generally ignored. However, we believe such optimization is crucial, especially for long-output generation tasks based on the following two observations: (i) Excessive compression during the prefill phase, which requires specific full context impairs the comprehension of the reasoning task; (ii) Deviation of heavy hitters occurs in the reasoning tasks with long outputs. Therefore, SCOPE, a simple yet efficient framework that separately performs KV cache optimization during the prefill and decoding phases, is introduced. Specifically, the KV cache during the prefill phase is preserved to maintain the essential information, while a novel strategy based on sliding is proposed to select essential heavy hitters for the decoding phase. Memory usage and memory transfer are further optimized using adaptive and discontinuous strategies. Extensive experiments on LongGenBench show the effectiveness and generalization of SCOPE and its compatibility as a plug-in to other prefill-only KV compression methods.
Fine-grainedly Synthesize Streaming Data Based On Large Language Models With Graph Structure Understanding For Data Sparsity
Mar 10, 2024



Due to the sparsity of user data, sentiment analysis on user reviews in e-commerce platforms often suffers from poor performance, especially when faced with extremely sparse user data or long-tail labels. Recently, the emergence of LLMs has introduced new solutions to such problems by leveraging graph structures to generate supplementary user profiles. However, previous approaches have not fully utilized the graph understanding capabilities of LLMs and have struggled to adapt to complex streaming data environments. In this work, we propose a fine-grained streaming data synthesis framework that categorizes sparse users into three categories: Mid-tail, Long-tail, and Extreme. Specifically, we design LLMs to comprehensively understand three key graph elements in streaming data, including Local-global Graph Understanding, Second-Order Relationship Extraction, and Product Attribute Understanding, which enables the generation of high-quality synthetic data to effectively address sparsity across different categories. Experimental results on three real datasets demonstrate significant performance improvements, with synthesized data contributing to MSE reductions of 45.85%, 3.16%, and 62.21%, respectively.
Causal Walk: Debiasing Multi-Hop Fact Verification with Front-Door Adjustment
Mar 05, 2024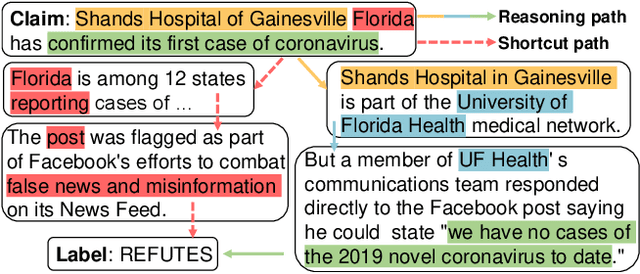
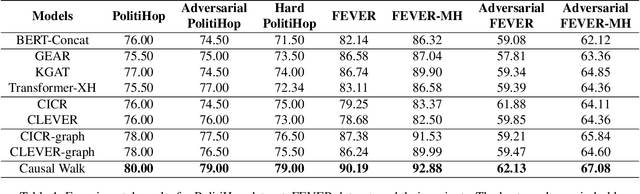
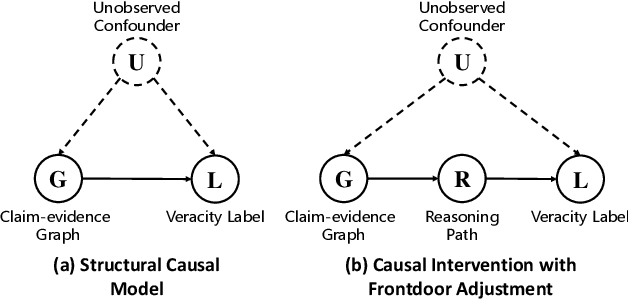

Conventional multi-hop fact verification models are prone to rely on spurious correlations from the annotation artifacts, leading to an obvious performance decline on unbiased datasets. Among the various debiasing works, the causal inference-based methods become popular by performing theoretically guaranteed debiasing such as casual intervention or counterfactual reasoning. However, existing causal inference-based debiasing methods, which mainly formulate fact verification as a single-hop reasoning task to tackle shallow bias patterns, cannot deal with the complicated bias patterns hidden in multiple hops of evidence. To address the challenge, we propose Causal Walk, a novel method for debiasing multi-hop fact verification from a causal perspective with front-door adjustment. Specifically, in the structural causal model, the reasoning path between the treatment (the input claim-evidence graph) and the outcome (the veracity label) is introduced as the mediator to block the confounder. With the front-door adjustment, the causal effect between the treatment and the outcome is decomposed into the causal effect between the treatment and the mediator, which is estimated by applying the idea of random walk, and the causal effect between the mediator and the outcome, which is estimated with normalized weighted geometric mean approximation. To investigate the effectiveness of the proposed method, an adversarial multi-hop fact verification dataset and a symmetric multi-hop fact verification dataset are proposed with the help of the large language model. Experimental results show that Causal Walk outperforms some previous debiasing methods on both existing datasets and the newly constructed datasets. Code and data will be released at https://github.com/zcccccz/CausalWalk.